<goal>
GPTに関して、アシスタントとして使う方法と、出力が事実か確かめる方法についてそれぞれ検索して結果をまとめて要約してください
</goal><plan><function.MyRetrieverSkill.Search input="GPT and how to use it as an assistant"setContextVariable="SEARCH_RESULT_1"/><function.MyRetrieverSkill.Search input="GPT and how to verify the output is true"setContextVariable="SEARCH_RESULT_2"/><function._GLOBAL_FUNCTIONS_.BucketOutputs input="$SEARCH_RESULT_1"bucketCount="1"bucketLabelPrefix="RESULT_1"/><function._GLOBAL_FUNCTIONS_.BucketOutputs input="$SEARCH_RESULT_2"bucketCount="1"bucketLabelPrefix="RESULT_2"/><function.MyRetrieverSkill.SummaryDocument input="$RESULT_1;$RESULT_2"appendToResult="RESULT__SUMMARY"/></plan>
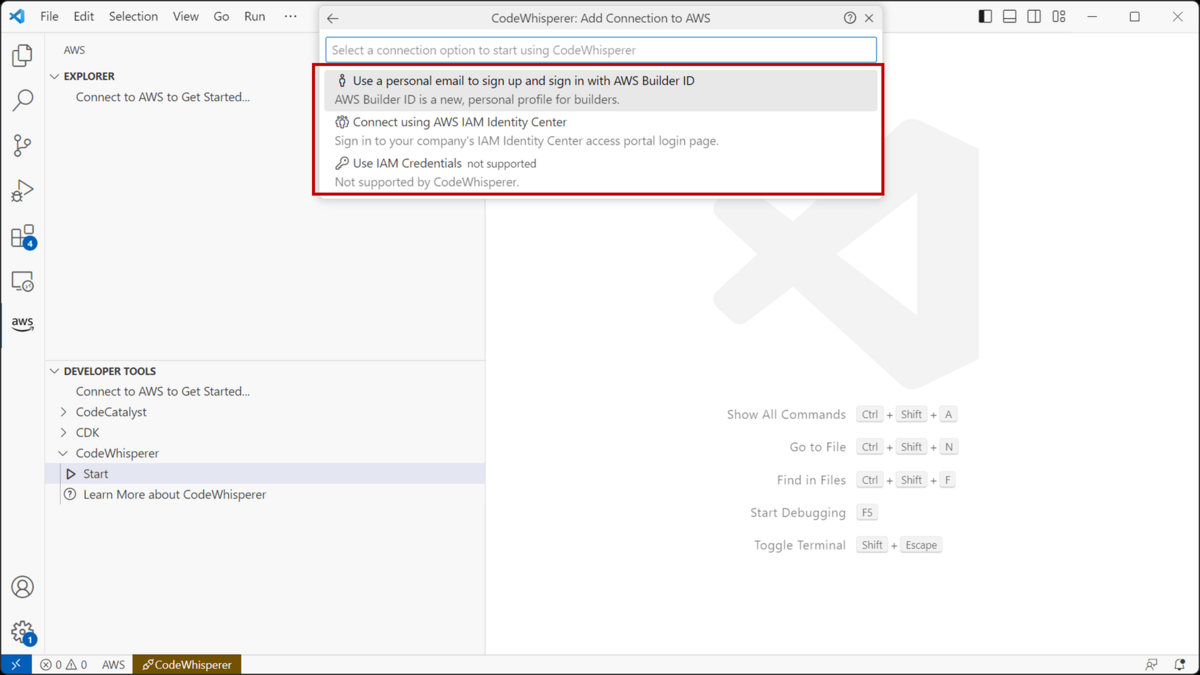
FAQsの原文を引用すると、こう表現されています。「Just like with your IDE, you own the code that you write, including any code suggestions provided by CodeWhisperer. 」
生成AIで作成したコードは誰が所有するのか?という問題は、しばしば議論される領域で、他のサービスではコードの所有が誰にあるのか明言していないものもあります。CodeWhispererがここで「you own the code」と明言しているのは、業務で利用するという点で、一つハードルをクリアしやすくなっていると思いました。
収集されたコードの漏洩
Professionalでは、「No. Content processed by CodeWhisperer Professional, such as code snippets, comments, and contents from files open in the IDE, is not stored or used to train the model, and therefore will never be reproduced in a code suggestion for another user.」と書かれており、はっきりと否定されています。
Individualでは、「We have safeguards designed to prevent reproduction of unique private code collected from CodeWhisperer Individual users.」という説明がされています。
from transformers4rec import torch as tr
max_sequence_length, d_model = 20, 320# Define input module to process tabular input-features and to prepare masked inputs
input_module = tr.TabularSequenceFeatures.from_schema(
schema,
max_sequence_length=max_sequence_length,
continuous_projection=64,
aggregation="concat",
d_output=d_model,
masking="mlm",
)
# Define Next item prediction-task
prediction_task = tr.NextItemPredictionTask(hf_format=True, weight_tying=True)
# Define the config of the XLNet Transformer architecture
transformer_config = tr.XLNetConfig.build(
d_model=d_model, n_head=8, n_layer=2, total_seq_length=max_sequence_length
)
# Get the end-to-end model
model = transformer_config.to_torch_model(input_module, prediction_task)