こんにちは。@Ssk1029Takashiです。
この記事は、Elastic Stack (Elasticsearch) Advent Calendar 2020の11日目です。
qiita.com
はじめに
Kibanaでアプリのログ管理をしていると、KibanaのDashboardだけを見ているだけではなく、実際のWebアプリの画面も確認することが多いです。
例えば、検索アプリの検索ログをKibanaでダッシュボードしている場合、急に検索回数が増えた単語などは、ユーザーがどんなコンテンツを探しているのか知るために実際の検索結果画面が見たくなります。
このような時に、DashboardとWebアプリの画面を行き来するのは、オペレーションの中で意外とストレスになります。

そこで、Kibana 7.10から追加されたURL drilldownという機能を使うことで、より手軽にDashboardからWebページを参照できるようなります。
今回書かないこと
今回以下のことは記事の対象外にしています。
- App Search・Elastic Stackの構築方法
- Visualizeの作成方法
URL Drilldownとは
簡単に言うと、DashboardからクリックしたVisualizeの値をもとにしたURLへ遷移できる機能です。
URLはテンプレートを使って、クリックした値やVisualizeのタイトルなどを参照できます。
使い方として、以下のようにケースがあります。
- 問題を絞り込んでクリックする際に、チケット管理システムのURLの特定フィールドに渡して起票する
- ログ管理で表示したIPアドレスを外部のReputationサイトに渡して、そのページで結果を見てさらに詳しい情報を参照する。
IPアドレスをReputationサイトで調査する機能はSIEM UIに標準で実装されていますが、Dashboardからでも実現可能になります。
詳しくは以下のドキュメントを参照してください。
www.elastic.co
実際に試してみる
環境
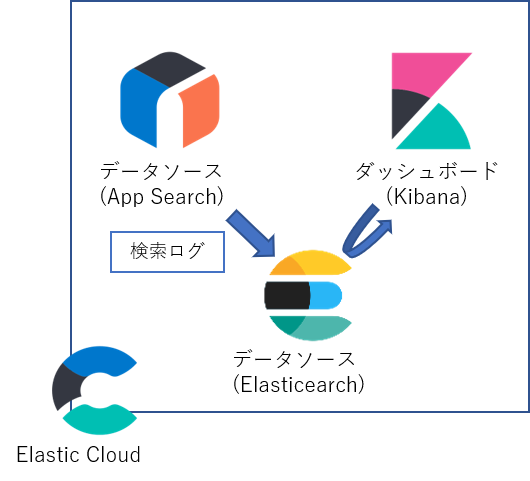
今回はElastic Cloud上のApp Searchを検索アプリとして、URL drilldownを使った画面遷移を試してみます。
Elasticsearch:7.10
Kibana:7.10
App Search:7.10
また、今回は事前にApp Searchでこのブログのデータを検索できるようにしています。
構成としては以下のようになっています。
Dashboardを作成する
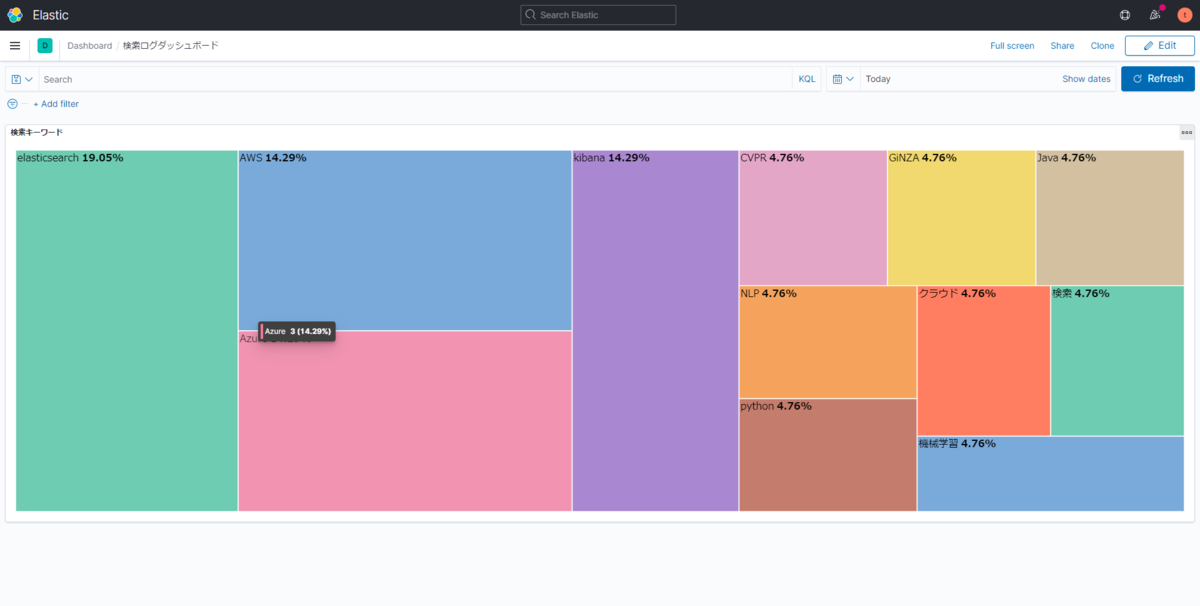
まずは、App Searchのログを参照して、検索されたキーワードの頻度を出すVisualizeを作成して、Dashboardに設定します。
今回はLensのTreeMapを使用しています。
URL drilldownを設定する
それではDashboardにURL drilldownを設定していきます。
Dashboardの編集画面から、URL drilldownを設定したいVisualizeを選択すると、「Create drilldown」というメニューが出てきます。

選択すると、drilldown作成メニューが表示されます。
まず、Dashboard drilldownかURL drilldownのどちらを作成するかを選択する必要があるので、「Go to URL」を選択します。
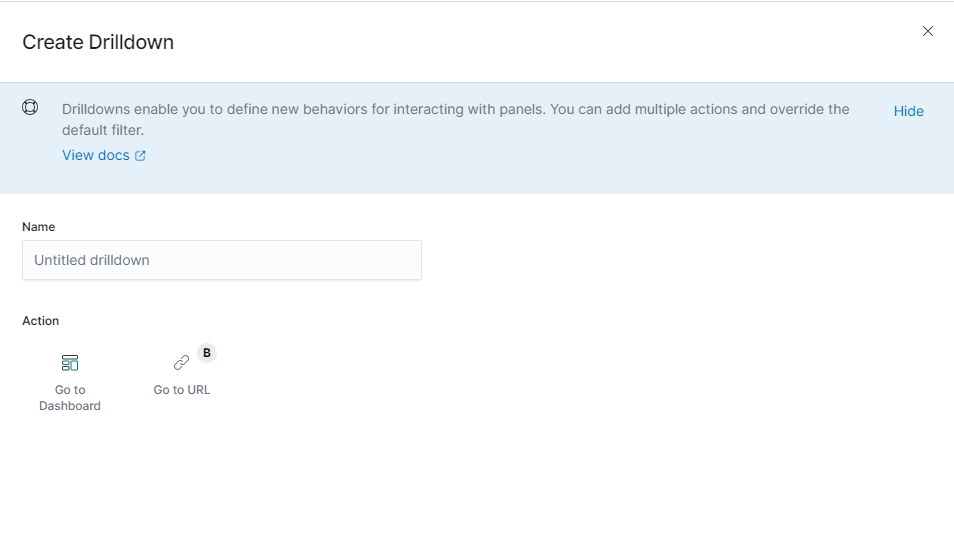
drilldown名とURLテンプレートを設定する画面なので、任意の名前と、URLを設定しましょう。
URLは以下のように検索サイトのURLにテンプレート文字列で選択した値がURLパラメータになるように設定します。
App Searchでは、URL引数にq=<検索キーワード>の形式で指定することで、検索できるので、以下のようにテンプレートを設定します
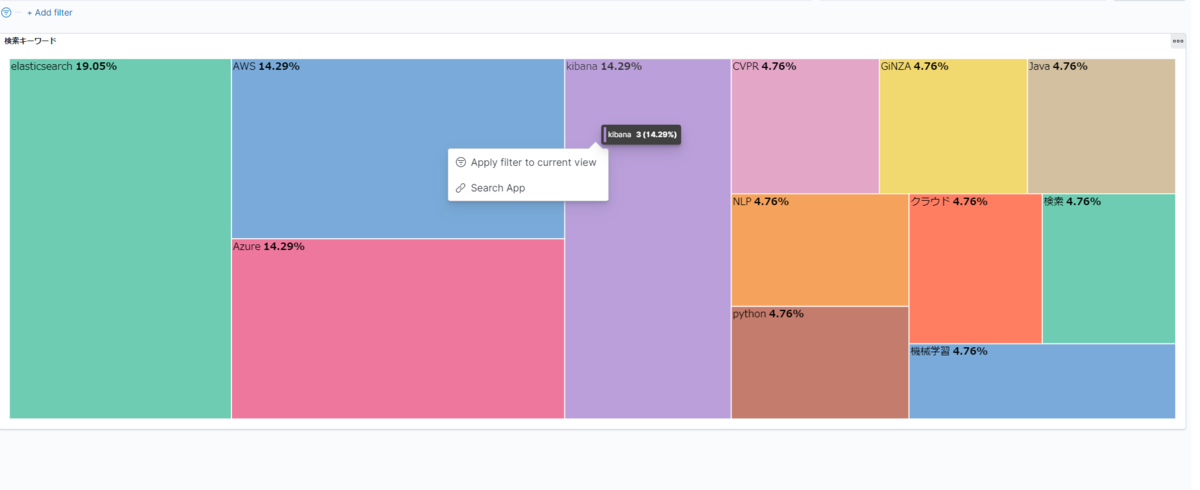
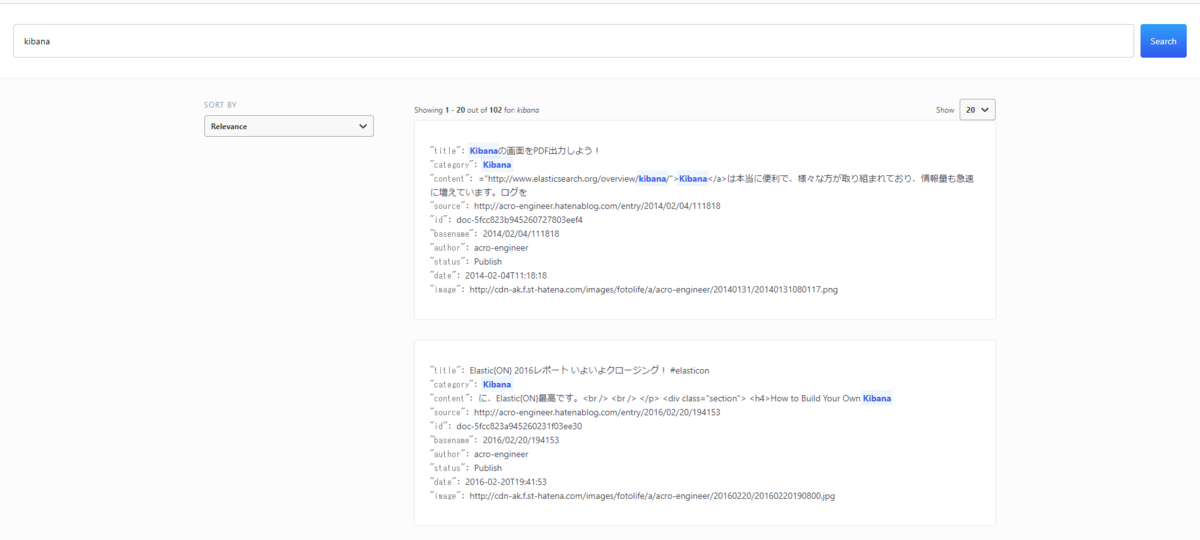
https://<検索サイトのURL>?q={{event.value}}上記の{{event.value}}の部分にDashboardで選択した部分が表示している値が入ります。
上記を設定後、「Create drilldown」を選択して、URL drilldownを作成します。
設定後は、Dashboardを保存する必要があるので、忘れないようにしましょう。
まとめ
本記事では、Kibanaの新機能であるURL drilldownを利用して、DashboardからWebアプリの画面にスムーズに移動できるようにすることで、日々の運用の効率化を図りました。
別のページを開きなおす、再度入力し直すなどの手間が減って、効率的になりそうです。
皆さんもDashboardでアプリログを運用するときにはぜひ参考にしてみてください。
Acroquest Technologyでは、キャリア採用を行っています。
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。世界初のElastic認定エンジニアと一緒に働きたい人Wanted! - Acroquest Technology株式会社のデータサイエンティストの求人 - Wantedlywww.wantedly.com