こんにちは。
本記事は、Azure Advent Calendar 2020 の19日目の記事になります。
最近、Angular+FastAPIでアプリを実装したのですが、仮想マシン ではなく、サーバレス・コンテナを使ったWebアプリとして構築してみたくなりました。
調べている中で、Azure Container Instances (以下、ACI)を見つけ、実際に試してみたところ、
この記事では、私が実際にACIを使ってみた中で学んだ、ACI上でのWebアプリの動かし方について、
この記事を見ながら、皆さんも実際にこの手軽さを体験していただきたいと思います。
それでは、さっそく始めましょう!
始めに: "Azure Container Instances"とは
ACIとは、高速かつ簡単にコンテナを実行できるサービスです。メリットは次の2つです。
コンテナイメージさえあればコマンド一つで立ち上げることができ、さらにインターネット上に直接公開をすることもできるので、すぐに利用することができます。
コンテナの起動時間とその間に使用したCPUとメモリに応じて課金されるので、使わないときは停止する等をすれば、コストも抑えることができます。
Webアプリの説明
まずはじめに、例として扱うWebアプリを説明します。
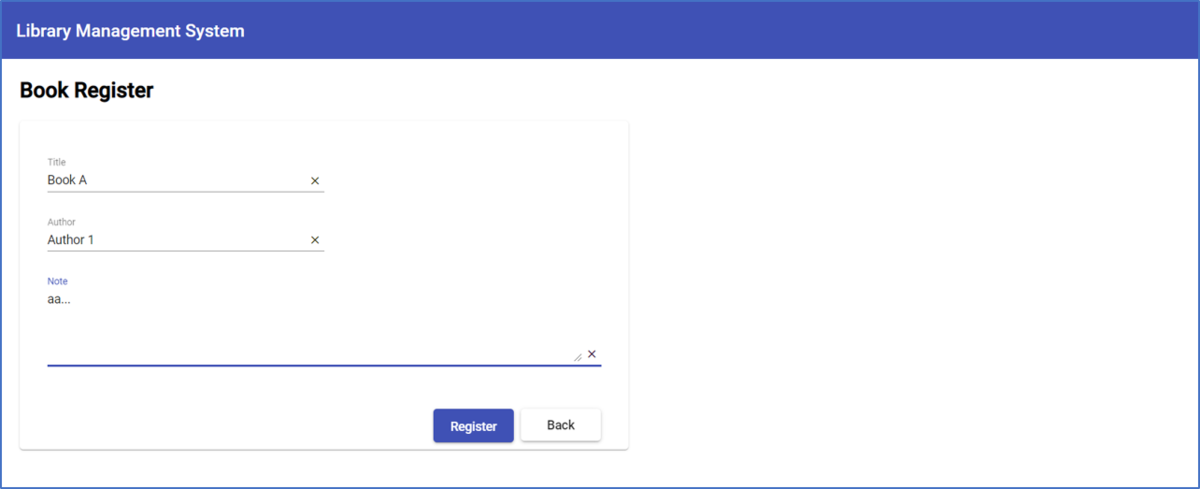
今回、本の情報を管理する、簡単な図書管理システムを構築してみました。
図書管理システムの一覧画面
図書管理システムの詳細・編集画面
フロントエンドはnginx + Angular、バックエンドはFastAPIを、今回は使用しました。
また、今回開発するにあたり、以下の環境を使用しました。
Node.js: v14.15.0
Docker: 20.10.0
Azure CLI : 2.16.0
なお、ディレクト リ構成は以下のようになっています。
sample-lsm-app
├─deploy-aci.yaml
├─docker-compose.yml
├─client
│ ├─angular.json
│ ├─Dockerfile
│ ├─package-lock.json
│ ├─package.json
│ ├─dist
│ │ └─client
│ │ └─フロントエンドの本体コードのビルド媒体
│ ├─nginx
│ │ └─default.conf
│ ├─node_modules
│ └─src
│ ├─app
│ │ └─フロントエンドの本体コード
│ └─environments
│ └─フロントエンドの環境設定
└─server
├─Dockerfile
├─poetry.lock
├─pyproject.toml
├─.venv
├─src
│ └─バックエンドの本体コード
└─tests
└─バックエンドのテストコード
Webアプリの構成
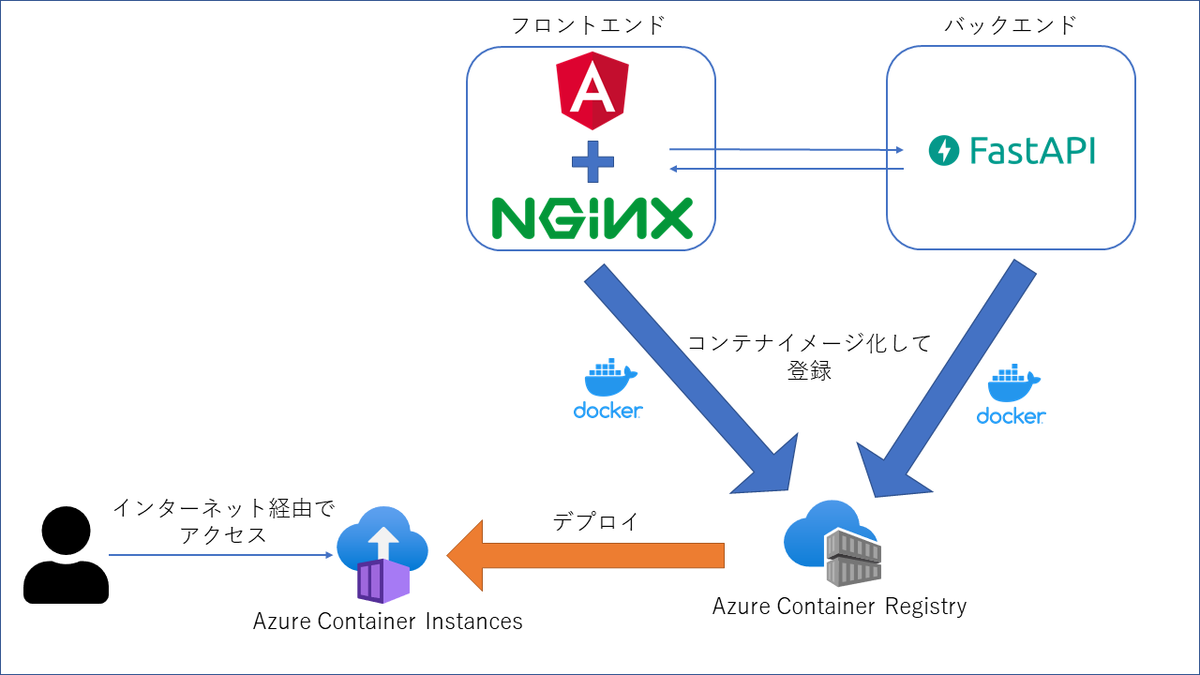
本アプリのAzure上での構成は以下のようになっています。
サンプルアプリ構成イメージ
フロントエンド、バックエンド、それぞれ別でコンテナイメージを作成して、Azure Container Registry(以下、ACR)に登録、
それでは実際に、ローカルで作成したWebアプリをAzure上に構築していきましょう。
WebアプリのAzure化
1. フロントエンドとバックエンドの結合部分の準備
まずは、フロントエンドからバックエンドへAPI を呼んで、データのやりとりができるように準備をします。
server {
listen 80;
server_name localhost;
root /usr/share/nginx/html;
index index.html index.htm;
location /api/ {
proxy_pass http://localhost:8000;
}
}
ここでのポイントは、
proxy_pass http://localhost :8000;
の部分です。通常、Docker上で動かす際は、"localhost "の部分にコンテナ名を指定しますが、localhost "での指定になります。
以上の設定で、"http://<ACIの公開FQDN >:80/api /~" とURLを指定することで、フロントエンドからAPI を呼ぶことができるようになりました。
ここから先はAngularの内容です。
nginxで設定したAPI のURLを呼べるように、environment.prod.tsに以下のように記述します。
export const environment = {
production: true ,
server: 'http://<ACIの公開FQDN>'
} ;
そして、実際にAPI を呼ぶservice.tsでは、以下のようにURLを指定するようにします。
fetchBooks() : Observable< Book[] > {
return this .http.get< Book[] >( environment.server + '/api/books' );
}
最後に、以下のコマンドで本番環境としてビルドを行うことで、フロントエンドをACI上で動かすための準備が完了しました。
npm build --prod
2. コンテナイメージ化
Dockerを使用し、フロントエンド側・バックエンド側両方のコンテナイメージを作成します。
まず、それぞれのDockerfileの内容はこちらです。
フロントエンド側
FROM nginx:1.16
COPY ./nginx/default.conf /etc/nginx/conf.d/default.conf
# distディレクトリ配下に作成されたビルド媒体をコピー
COPY ./dist/client /usr/share/nginx/html
バックエンド側
FROM python:3.8-slim
WORKDIR /usr/src/app
RUN pip install poetry
# ソースコード類のコピー
COPY . .
# 実行環境の用意
RUN poetry export -f requirements.txt > requirements.txt
RUN pip install -r requirements.txt
# FastAPIの起動
CMD python /src/main.py
これらをまとめて立ち上げるための、docker-compose.yaml はこちらです。
version : "3"
services :
client :
build : ./client
image : sample-lms-app_client:1.0
container_name : sample-lms-app_client
ports :
- 80:80
server :
build : ./server
image : sample-lms-app_server:1.0
container_name : sample-lms-app_server
ports :
- 8000:8000
docker-composeのbuildコマンドで、コンテナイメージを作成します。
docker-compose build
3. Azure Container Registryの作成
2で作成したコンテナイメージを、登録するためのACRを用意します。
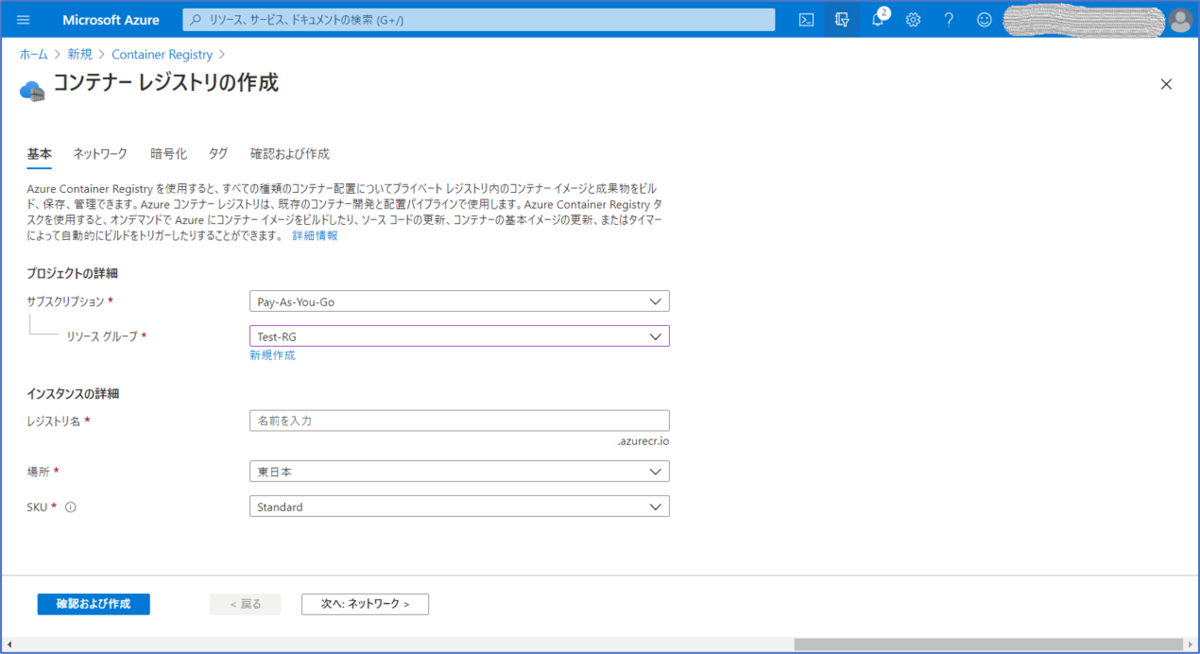
Azure portal から「リソースの作成」を行い、"Container Registry"を検索します。
"Container Registry"で検索すると、作成画面が開きます
必要事項を入力し、ACRを作成します。
ACRの作成画面
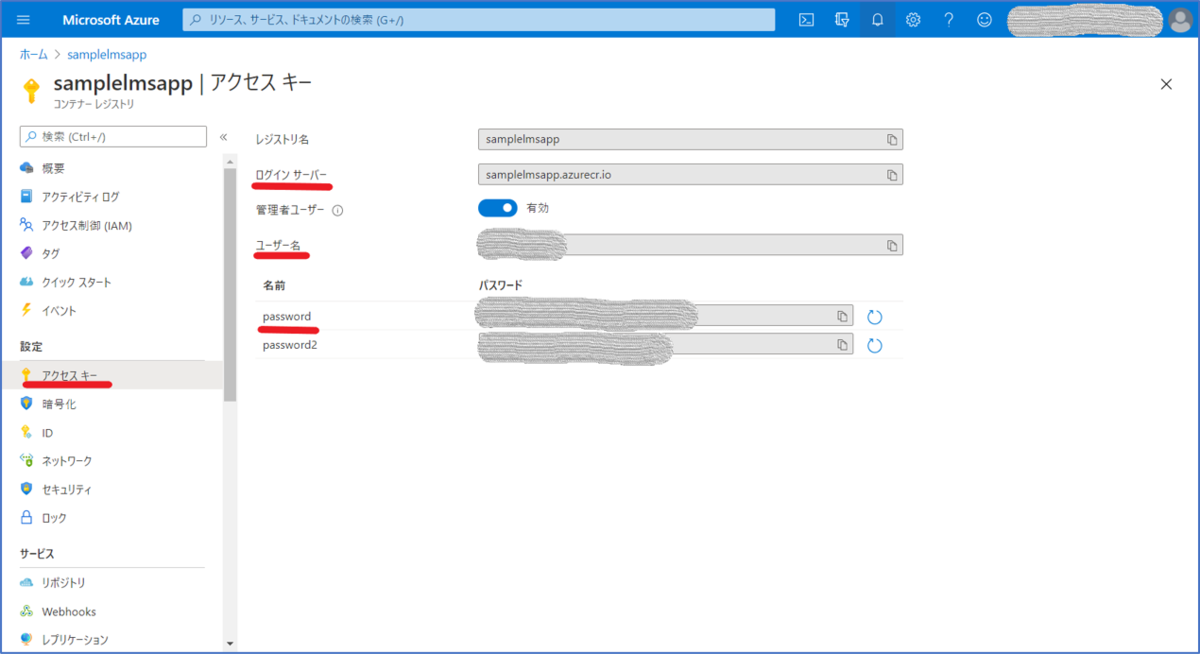
作成完了後、「アクセスキー」から、「管理者ユーザー」の設定を有効化します。
ACRへのアクセスキーの表示
4. Azure Container Registryへコンテナイメージの登録
2で作成したコンテナイメージを、3で作成したACRに登録します。
最初に、コマンドプロンプト 経由で、ACRにログインを行います。3の最後で取得した、アクセスキーを使用します。
docker login <ログインサーバー> -u <ユーザー名> -p <パスワード>
次に、2で作成したコンテナイメージに、タグ付けを行います。
docker tag sample-lms-app_client:1.0 <ログインサーバー>/sample-lms-app_client:1.0
docker tag sample-lms-app_server:1.0 <ログインサーバー>/sample-lms-app_server:1.0
最後に、pushを行うことで、ACRにコンテナイメージが登録されます。
docker push <ログインサーバー>/sample-lms-app_client:1.0
docker push <ログインサーバー>/sample-lms-app_server:1.0
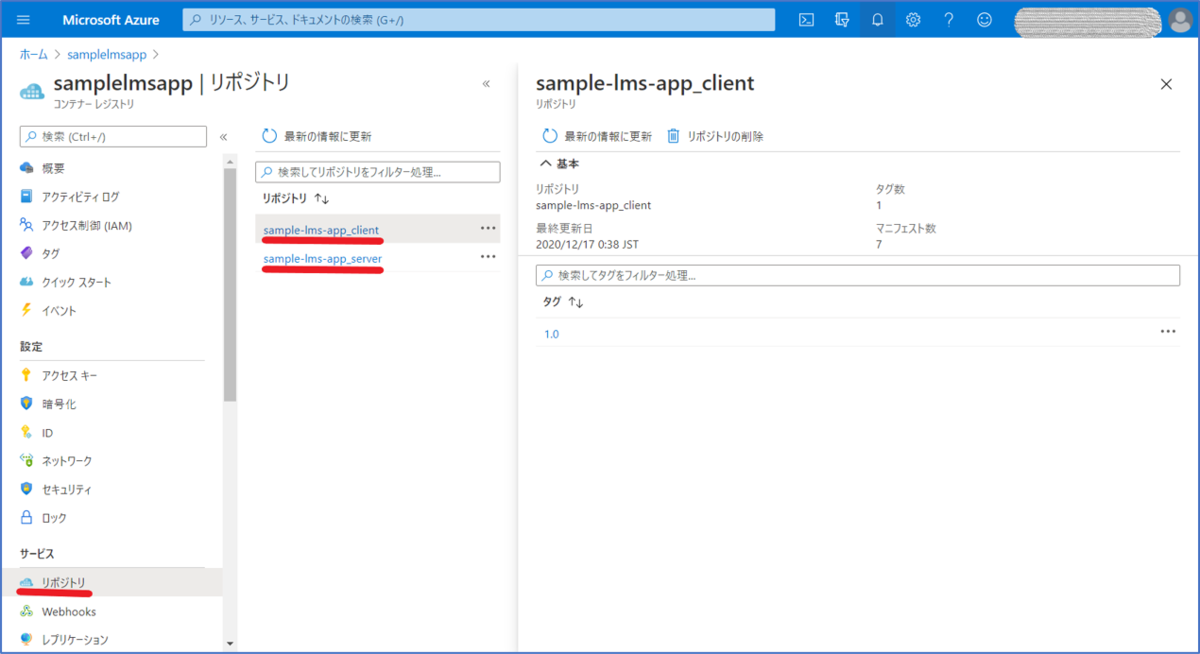
登録が成功していることは、Azure portal の画面から、「リポジトリ 」の画面を開くことで確認ができます。
登録済みコンテナイメージの一覧
5. Azure Container Instancesの立ち上げ
いよいよ、ACI上にアプリを立ち上げます。
そのために、設定ファイルの作成が必要です。以下のような"deploy-aci.yaml "を作成しました。
apiVersion : 2018-10-01
name : SampleLMSAppACG
location : japaneast
properties :
containers :
- name : client
properties :
image : <ログインサーバー>/sample-lms-app_client:1.0
resources :
requests :
cpu : 1
memoryInGb : 1
ports :
- port : 80
protocol : TCP
- name : server
properties :
image : <ログインサーバー>/sample-lms-app_server:1.0
resources :
requests :
cpu : 1
memoryInGb : 1
ports :
- port : 8000
protocol : TCP
osType : Linux
ipAddress :
type : Public
ports :
- protocol : tcp
port : 80
- protocol : tcp
port : 8000
dnsNameLabel : sample-lsm-app
imageRegistryCredentials :
- server : <SERVER>
username : <USERNAME>
password : <PASSWORD>
以下、詳細な説明です。
type: Public
今回は、ACIを直接公開するため、"Public"を選択しました。
例えば、IP制限等を行うために、VNet下にアプリを立ち上げる場合には、ここで"Private"を選択します。
dnsNameLabel: sample-lsm-app
1で設定した"ACIの公開FQDN "は、ここで設定したものです。
ここで設定したDNS ラベルと、選択したリージョンによって、"<DNS ラベル>.<リージョン>.azurecontainer.io"のように、公開FQDN が決定します。
ここで作成した設定ファイルを使って、ACIのデプロイを行います。コマンドプロンプト 上で、"az"コマンドが使えるようになっている必要があります。(Azure CLIのインストール )
まずは、Azure CLI 上で、ログインが必要です。
az login
これで、アプリをデプロイするための準備がすべて整いました。最後に、以下のコマンドでアプリを立ち上げます。
az container create --resource-group <リソースグループ> --file deploy-aci.yaml
6. 動作確認
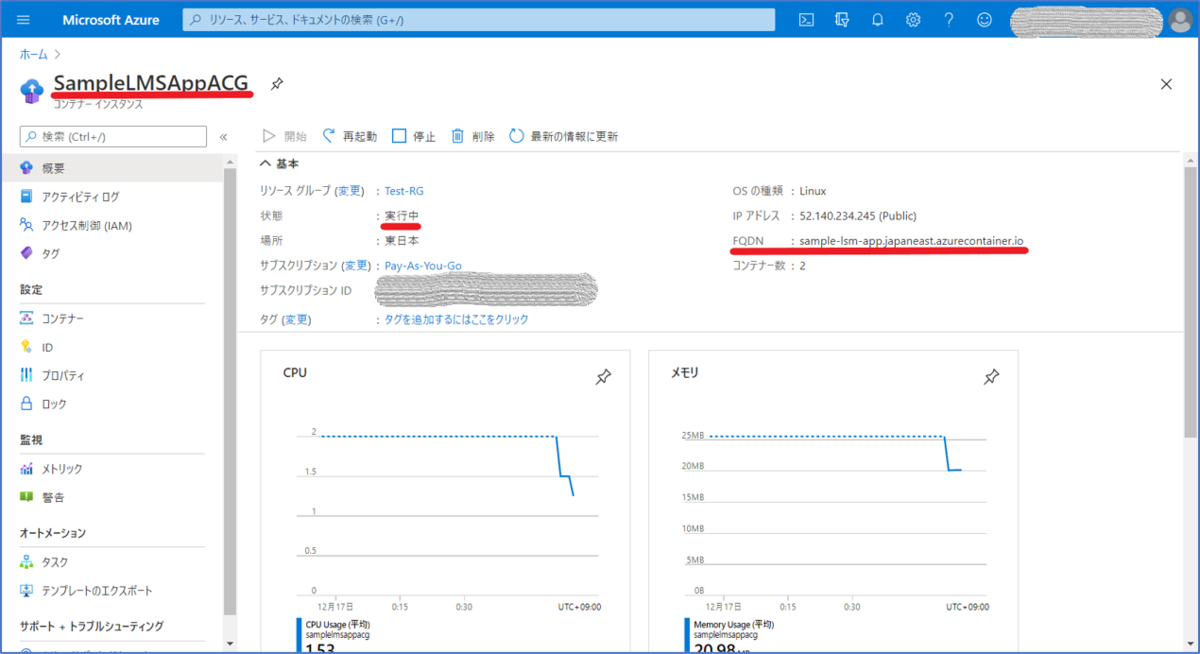
作成コマンドを実行したら、Azure portal 上で、実際にACIが作成されたか確認してみましょう。
作成したACIの概要画面
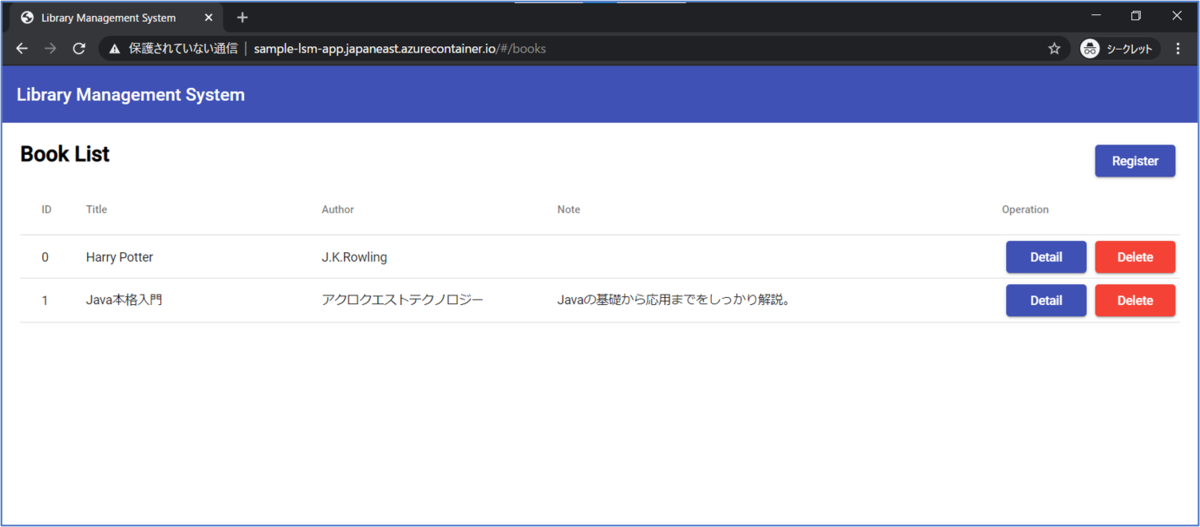
ACIが実際に作成できたことが確認できたら、画面に表示されているFQDN から、アプリにアクセスしてみましょう。
ACI上で動いているアプリにアクセスした様子
無事に画面を開くことができました!
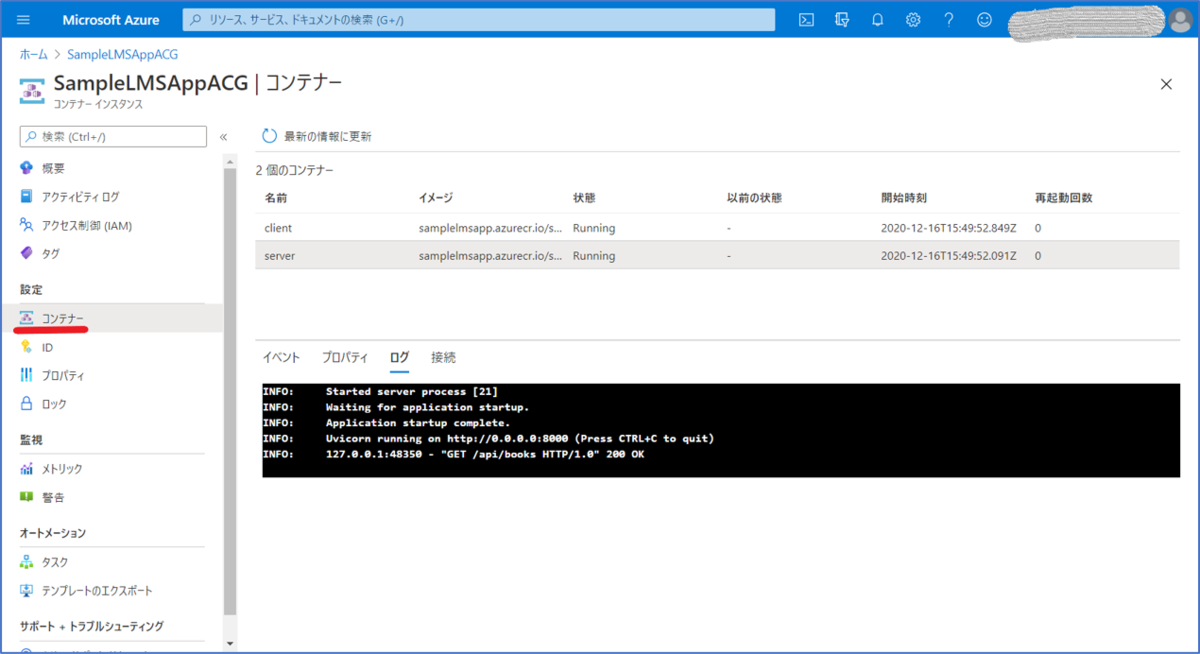
もしもここで画面が開けなかった場合は、コンテナのログを見て、エラーが出ていないか確認します。
コンテナログの表示
詰まりやすいのは、フロントエンドとバックエンドとの連携の部分なので、
なお、ACIのリソースは一度削除してから、作成コマンドを実行してください。
最後に
いかがだったでしょうか?
私が初めてこの構成でアプリを立ち上げようとした時は、チュートリアル を参考にしたものの、1つのコンテナの場合の説明のみだったため、
ぜひ皆さんも自作のアプリをACI上にデプロイして、動かしてみてください!
Acroquest Technologyでは、キャリア採用を行っています。
ディープラーニング 等を使った自然言語 /画像/音声/動画解析の研究開発Elasticsearch等を使ったデータ収集/分析/可視化
マイクロサービス、DevOps、最新のOSS を利用する開発プロジェクト
書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。
モノリシックなアプリケーションをマイクロサービス化したいエンジニア募集! - Acroquest Technology株式会社のWebエンジニアの求人 - Wantedly www.wantedly.com