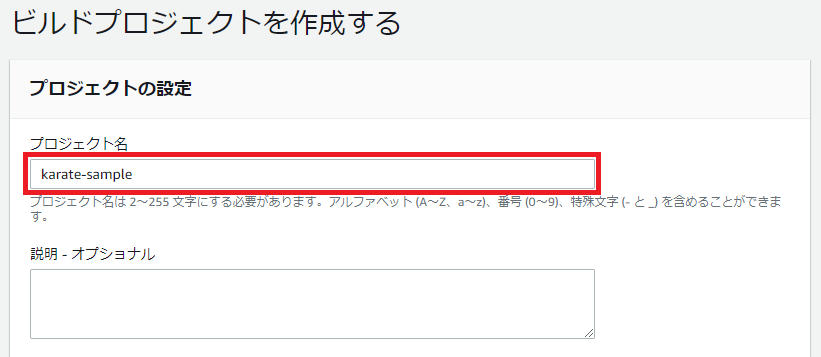
はじめに
こんにちは。フロントエンドエンジニアのmiuraです。

本記事では、2021年12月のAWS re:Inventで発表されたAmazon CloudWatch RUMを、
AngularのWEBアプリケーションで実際に利用してみて、使い勝手を確認してみたいと思います。
Amazon CloudWatch RUMの特徴、実際の使い方をお伝えできればと思います。
Amazon CloudWatch RUMとは
概要
Amazon CloudWatch RUMは、WEBアプリケーションのパフォーマンスやエラーなどをモニタリングすることができるサービスです。
例えば、ECサイトに組み込むことで、ユーザーがどの端末やブラウザからアクセスしており、コンテンツの表示速度がどのくらいかなどを簡単にモニタリングすることができ、WEBアプリケーションの改善に役立たせることができます。
特徴
Amazon CloudWatch RUMでは、以下の4つをモニタリングすることができます。
- パフォーマンス
- WEBアプリケーションのパフォーマンス指標である4つの値が収集され、確認することができます。
- 時刻別の平均ロード時間
- 最大コンテンツの描画(LCP)
- 最初の入力遅延(FID)
- 累積レイアウトシフト(CLS)
- WEBアプリケーションのパフォーマンス指標である4つの値が収集され、確認することができます。
- エラーとセッション
- HTTPエラーやJavaScript内の想定外のエラーを一覧で確認することができます。
- ブラウザとデバイス
- ブラウザやデバイス、国ごとに平均ロード時間やエラー数などを確認することができます。
- ユーザージャーニー
- ユーザーが、WEBアプリケーション内のどのページからアクセスして、どのページに遷移したかを確認することができます。
そして、これらのモニタリングをお手軽に設定できることが、Amazon CloudWatch RUMの最大の特徴になります。
料金
Amazon CloudWatch RUMの料金は「イベント」を単位として、100,000 イベントあたり $1の課金が発生します。
ページの遷移やエラーをそれぞれ1イベントとして計算されるため、JavaScriptや画像などのコンテンツサイズは料金には影響しません。
Amazon CloudWatch RUMを使ったモニタリング
それでは実際に、Amazon CloudWatch RUMを設定し、いかに手軽にWEBアプリケーションのモニタリングをできるかを見ていきたいと思います。
前提
今回は、以下の前提をもとに手順を示します。
1. AWSアカウントを持っている。
2. Node.js v14.15.5以上がインストールされている。
Amazon CloudWatch RUMの新規追加
AWSコンソールで、Amazon CloudWatchを開きます。左のサイドメニューより「アプリケーションのモニタリング > RUM」を選択します。
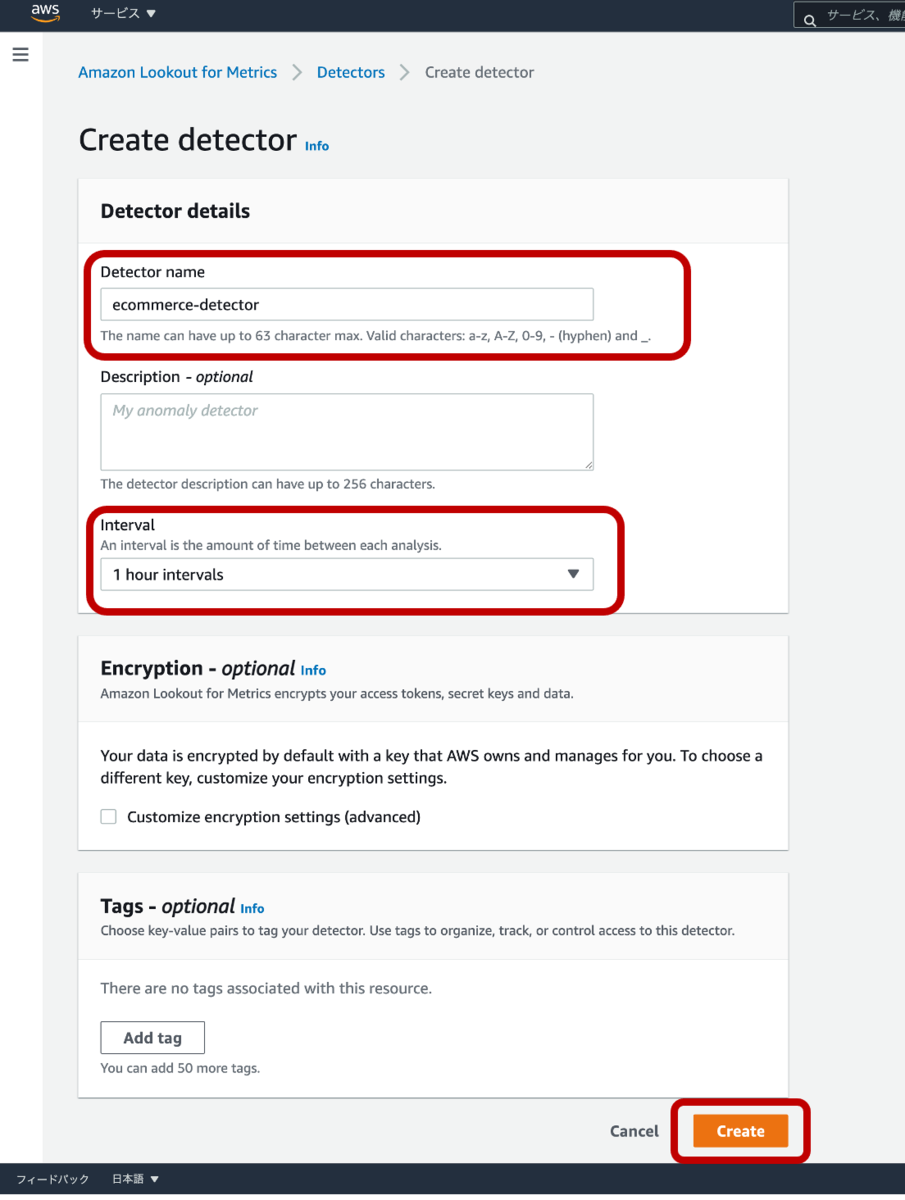
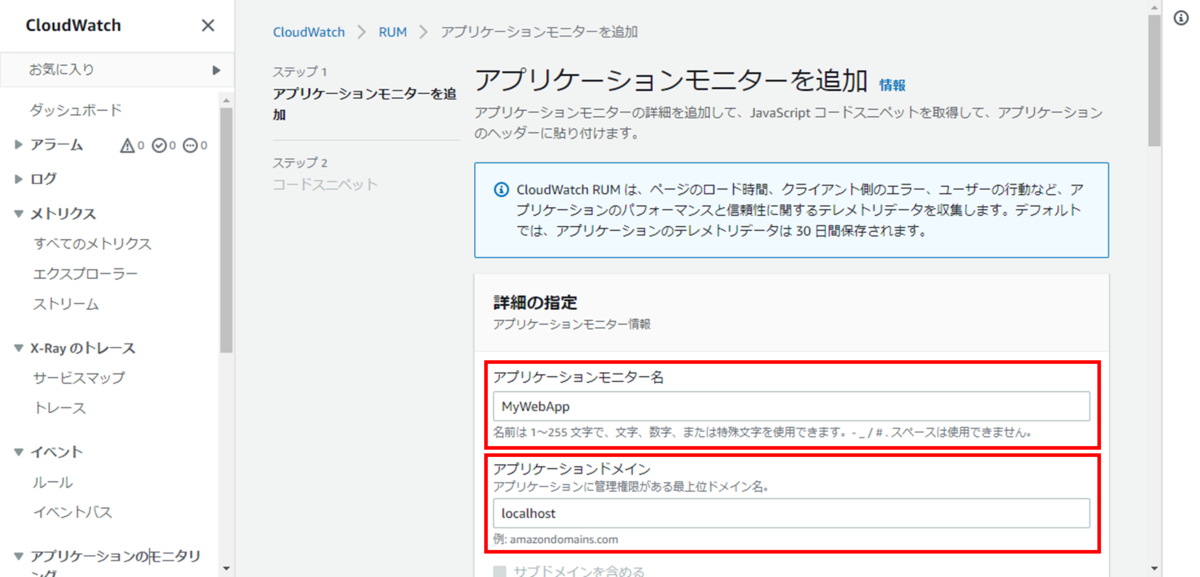
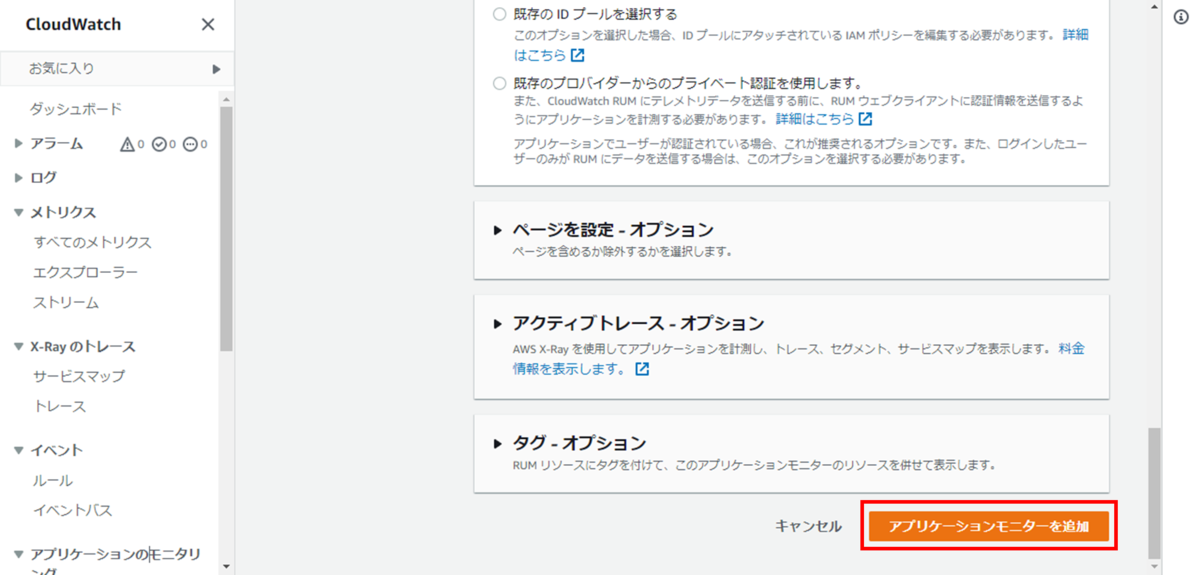
「アプリケーションモニターを追加」を押下し、アプリケーションモニターの追加画面を開きます。

アプリケーションモニターの追加画面では、
①アプリケーションモニター名
②アプリケーションドメイン
を設定します。
②のアプリケーションドメインには、WEBアプリケーションにアクセスできるドメインを設定します。今回はローカルで動作確認できるように「localhost」を指定します。
上記の①②以外のオプションは、今回、デフォルト設定のままにします。
画面下部の「アプリケーションモニターを追加」を押下し、追加を完了します。
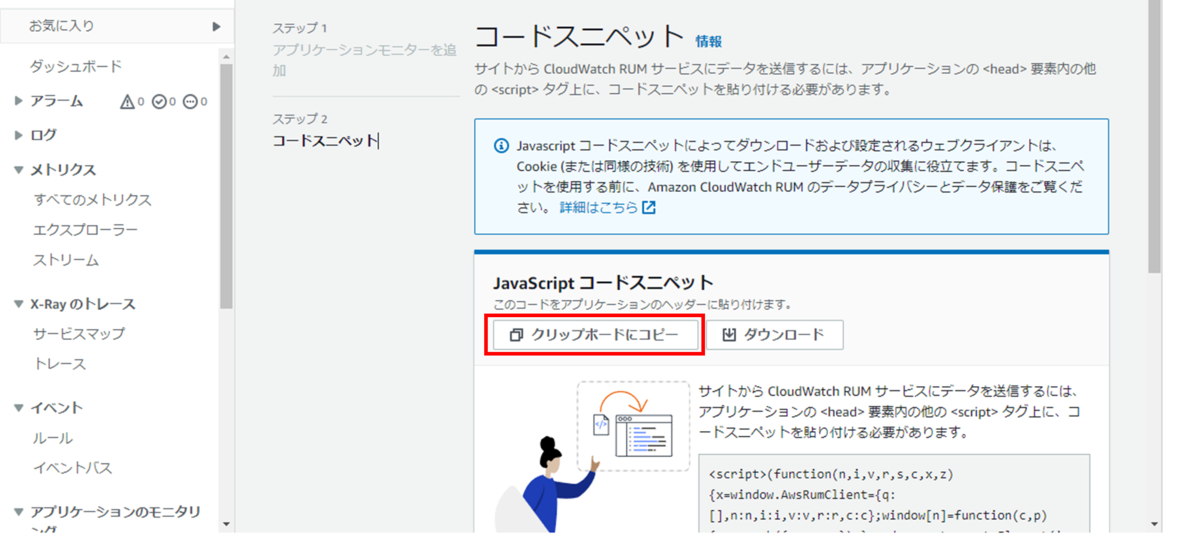
アプリケーションモニターが追加されると、WEBアプリケーションに組み込むコードスニペットが表示されます。
「クリップボードにコピー」を押下して、メモに残しておきます。
※一度閉じた後でもアプリケーションモニターの設定画面から確認できます。
WEBアプリケーションへの組み込み
今回、JavaScriptフレームワークであるAngularを用いたWEBアプリケーションに組み込んでみます。
まずは、Angular CLIをインストールします。
npm install -g @angular/cli
Angular CLIを使って、初期プロジェクトを作成します。
ng new my-angular-web-app
初期プロジェクトの作成が完了すると、指定したプロジェクト名(例:my-angular-web-app)のフォルダが作成されるので、そのフォルダを開きます。
そのフォルダ内にある「src/index.html」を編集するため開きます。
「head」タグ内の最後に、Amazon CloudWatch RUMを追加したときに取得したコードスニペットを貼り付けて保存します。
<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8" /> <title>MyAngularWebApp</title> <base href="/" /> <meta name="viewport" content="width=device-width, initial-scale=1" /> <link rel="icon" type="image/x-icon" href="favicon.ico" /> <!-- こちらにコードスニペットを貼り付ける --> </head> <body> <app-root></app-root> </body> </html>
ここまでで、すでにモニタリングできる準備は整いました。
しかし、Angularの場合、想定外のエラーをキャッチしてAmazon CloudWatch RUMに送信するために、追加で実装が必要でした。
「src/app」フォルダ配下に「utils」フォルダを作成し、その中で以下のコードで「cwr-error-handler.ts」を作成します。
import { ErrorHandler } from '@angular/core'; declare function cwr(operation: string, payload: any): void; export class CwrErrorHandler implements ErrorHandler { handleError(error: any) { console.error(error); cwr('recordError', error); } }
「app.module.ts」を開き、「providers」に「ErrorHandler」を追加します。
import { ErrorHandler, NgModule } from '@angular/core'; import { BrowserModule } from '@angular/platform-browser'; import { AppRoutingModule } from './app-routing.module'; import { AppComponent } from './app.component'; import { CwrErrorHandler } from './utils/cwr-error-handler'; @NgModule({ declarations: [AppComponent], imports: [BrowserModule, AppRoutingModule], providers: [ { provide: ErrorHandler, useClass: CwrErrorHandler, }, ], bootstrap: [AppComponent], }) export class AppModule {}
以上で、WEBアプリケーションへの組み込みが完了しました。
以下のコマンドでWEBアプリケーションを起動し、http://localhost:4200を開きます。
npm start
WEBアプリケーションを開いた時点でAmazon CloudWatch RUM(https://dataplane.rum.<リージョン>.amazonaws.com)への送信が開始されます。
そして、画面遷移やエラーが発生する度にその情報が送信され、Amazon CloudWatch RUM上に表示されます。

パフォーマンスの確認
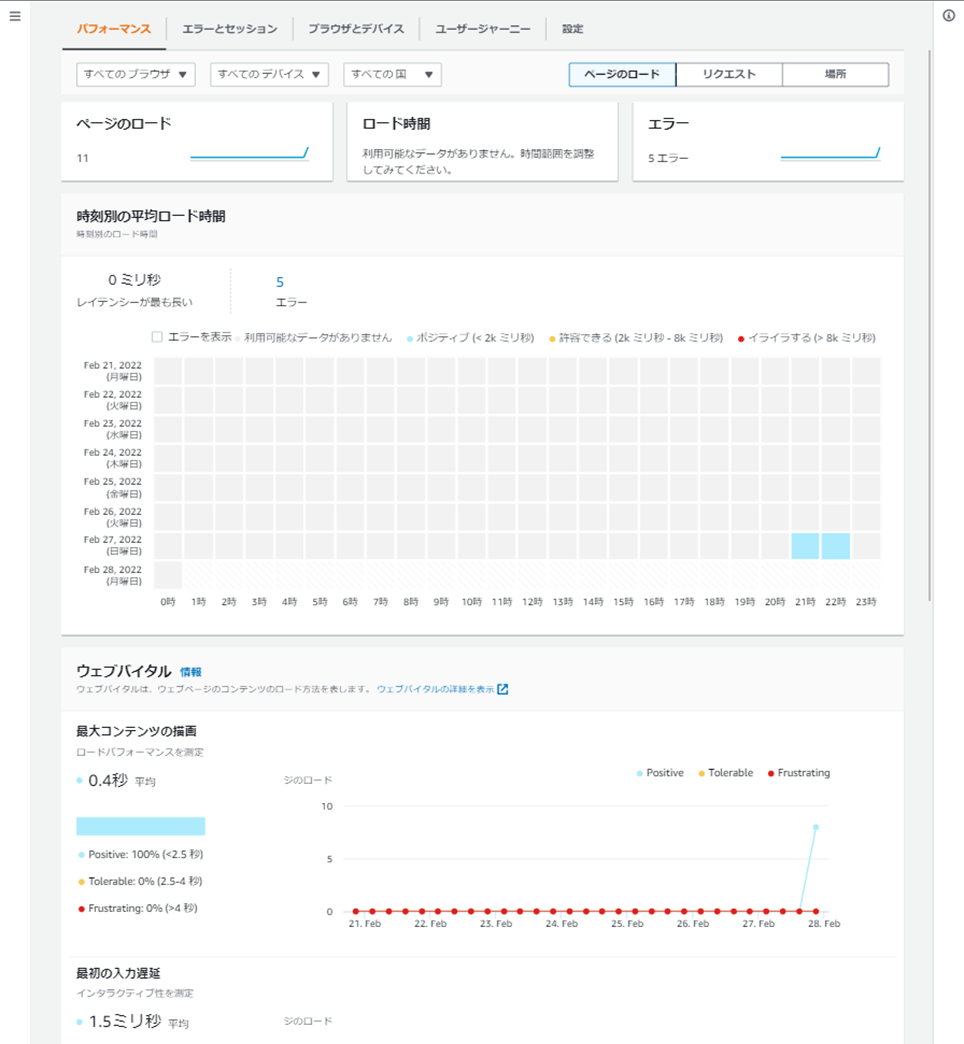
数回WEBアプリケーションの表示を行うと、Amazon CloudWatch RUM上にログが蓄積し、ウェブバイタルやユーザージャーニーなどにグラフが表示されます。
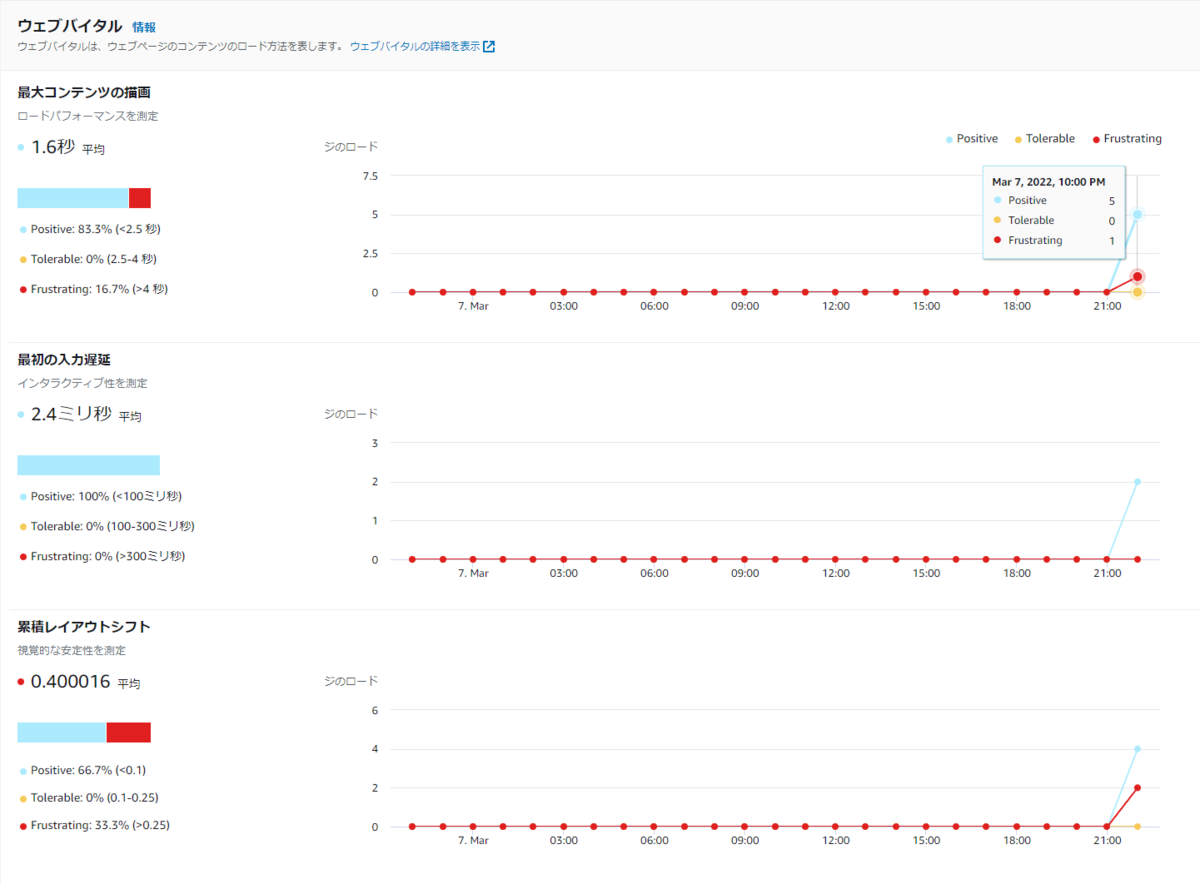
ウェブバイタルの場合、グラフには「Positive」「Tolerable」「Frustrating」という3つのしきい値があらかじめ設けられています。
それぞれ「Positive」ならパフォーマンスが良く、「Tolerable」なら許容できる程度のパフォーマンスがあり、「Frustrating」ならユーザーがイライラするほどパフォーマンスが悪いことを示しています。
例えば、下図の場合、「最大コンテンツの描画」では、計6回のアクセスのうち5回は「Positive」で、1回は「Frustrating」であったことが、時系列で確認できます。
もし今後「Frustrating」が多くなった場合は、パフォーマンス改善が必要ということになります。
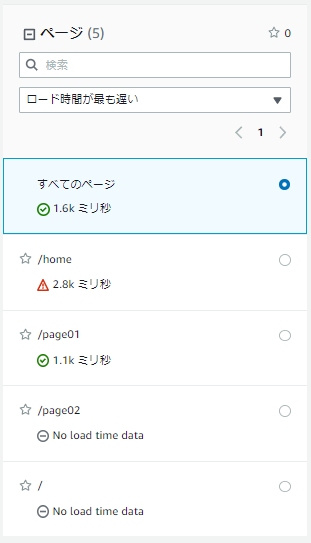
また、Amazon CloudWatch RUMでは、WEBアプリケーションが複数ページある場合、それぞれのページを指定して表示することができるため、どのページで改善が必要なのかを確認することもできます。
使用感
使いやすい点
注意が必要な点
- JavaScriptフレームワークによっては追加の実装が必要になる
- AngularなどJavaScriptフレームワークによっては、想定外のエラーを内部でキャッチしてしまうため、今回のような追加の実装が必要になります。
- 問題を検知して自動で通知してくれる機能がない
- ユーザージャーニーにて、動的に変わるURLを同じページとみなすためには、追加の実装が必要になる
- 表示するページは同じだが、中身の値を変化させる場合、「/users/<ユーザーID>」のようにURLを動的に変えることがあります。
- この動的に変わるURLを同じページとみなしたい場合は、aws-rum-web/cdn_angular.md at main · aws-observability/aws-rum-web · GitHubのように、追加で実装をする必要があります。
さいごに
以上で、Amazon CloudWatch RUMを使ったモニタリングは完了です。
とにかくお手軽にWEBアプリケーションのモニタリングを始めたい、という人におすすめできるサービスだと思いました。
また、X-Rayと一緒に活用することで、よりWEBアプリケーションの運用に役立ちそうです。
それでは。
Acroquest Technologyでは、キャリア採用を行っています。
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。
サーバーレスでサービス開発を行いたいクラウドエンジニア募集! - Acroquest Technology株式会社のシステムエンジニアの採用 - Wantedlywww.wantedly.com