最近、実際の仕事でも、データレイクに関する話を耳にするようになってきました。私自身、あまり経験がない分野だったので、「安全なデータレイクを数日で簡単にセットアップできる」という、うたい文句にひかれて、今回、AWS Lake Formation + Athena による、簡易なデータレイク構築を試してみました。 実際に構築をしてみたところ、つまづいたポイントなどもいくつかあり、特にIAMの扱いや権限の考え方などは重要だと感じました。そこで、実際に構築してみた流れや、つまづいたポイントなどを中心に、記事にまとめていきたいと思います。
ひとつの記事では、まとまらない量になってしまったので、3回にわたって連載していきます。
各記事で取り扱うテーマは次の通りです。
- 第1回:AWS Lake Formationでデータレイク体験! #1 何がうれしいのか?(本記事)
- 第2回:AWS Lake Formationでデータレイク体験! #2 Athenaで簡単データ連携
- 第3回:AWS Lake Formationでデータレイク体験! #3 きめ細かな権限管理
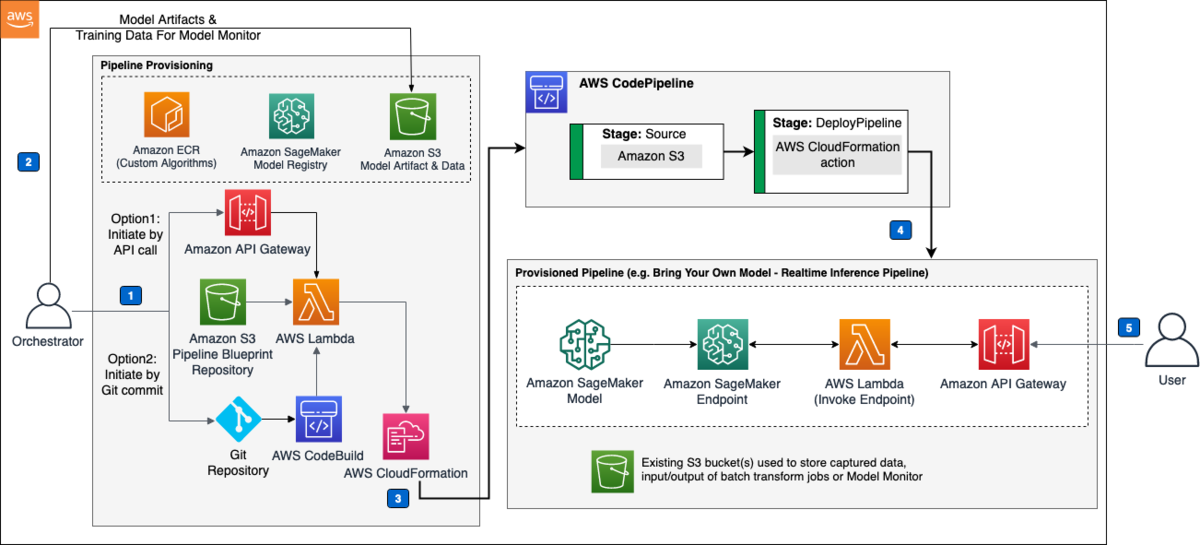
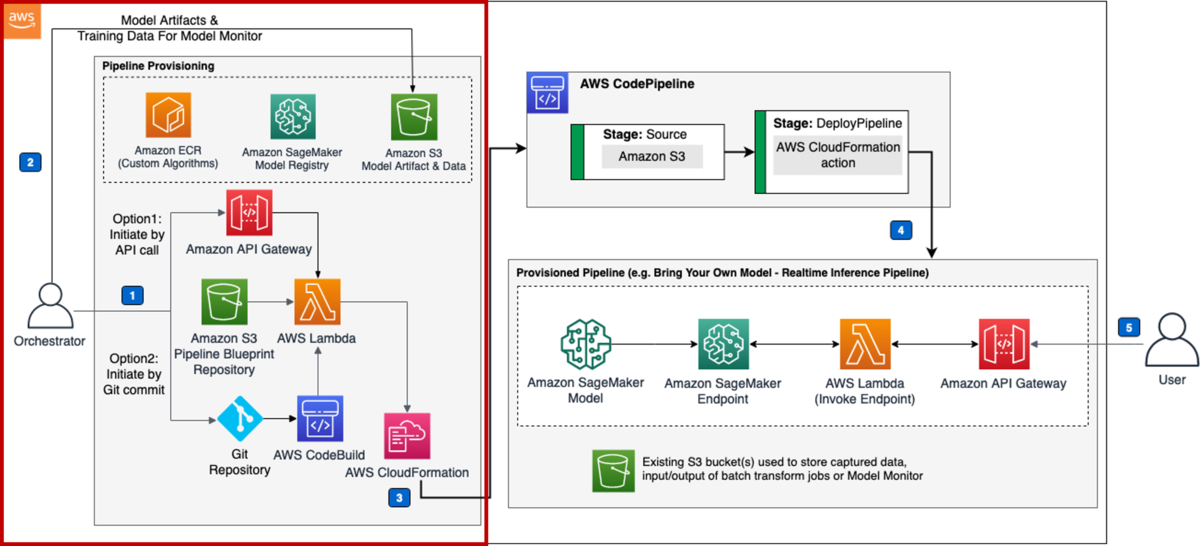
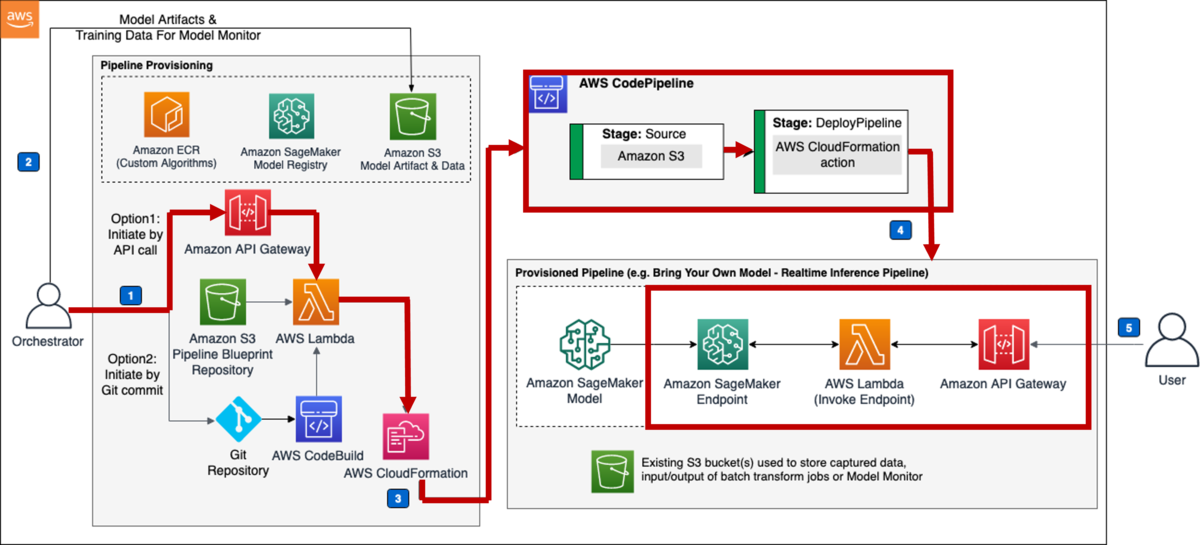
3回の記事を通して、以下の構成で構築していきます。 本記事では、赤枠部分の構築をしていきます。

初回の本記事では、データレイク、およびLake Formationの概要と、Lake Formationの基本的な構築を実施していきます。
1. データレイクとは
データレイクとは、様々な形式、かつ、大規模なデータを保存し、一元管理するための仕組みです。 同様に、大量のデータを保存・管理する仕組みとして、従来からデータウェアハウスがありましたが、以下のような違いがあります。
| 特徴 | データウェアハウス | データレイク |
|---|---|---|
| データタイプ | 構造化データ | すべての構造化・非構造化データ |
| データ | 分析用に加工したデータ | 加工前データ |
| 分析用途 | BI / データビジュアライゼーション | 機械学習 / 予測分析 |
| 関連AWSサービス | Amazon RedShift | S3, Lake Formation |
2. Lake Formationでできること
Lake Formationの特徴は以下の3点です。
そのため、データレイクを一から構築するとなると、それぞれの技術要素に深い理解が求められ、数か月単位で時間・コストが必要とも言われています。Lake Formationでは、そうした障壁なく、短時間でデータレイクを構築することが可能です。
その際、個人情報などは許可された役割の人にのみアクセス可能にする等の対応が必要になります。Lake Formationでは、データソースレベルだけでなく、行・列レベルできめ細かに権限設定できます。
3. データレイク構築
ここからは、実際にLake Formationでデータレイクを構築していきたいと思います。以下の流れで、データレイクを構築していきます。
- (1) データ準備
- (2) IAMユーザ/ロールの準備
- (3) Lake Formation構築
(1) データ準備
利用データのダウンロード
本記事では、AI・データサイエンスのコンペティションであるKaggleで公開されているデータを利用します。
利用するファイルと、データの内容は、以下のようになっています。
| ファイル名 | 説明 |
|---|---|
| sales_train.csv | 2013年1月から2015年10月までの日別販売トランザクションデータ |
| items.csv | 商品名のマスタデータ |
| item_categories.csv | 商品カテゴリのマスタデータ |
| shops.csv | 店舗情報のマスタデータ |
S3へのデータアップロード
取得したCSVファイルを、S3にアップロードします。
sales_train.csvをsales.csvにリネームし、以下のディレクトリ構成でS3にアップロードします。
/ ├ sales/ | └ sales.csv/ ├ items/ | └ items.csv/ ├ item_categories/ | └ item_categories.csv/ └ shops/ └ shops.csv/
(2) IAMユーザの準備
IAM管理者
こちらは、Lake Formationにおける、ペルソナの考えに従い、AdministratorAccess権限を持つユーザを想定しています。
AdministratorAccess権限は、ルートユーザ同等の権限となるので、扱いには注意が必要です。
ワークフロー用ロール
まず、Lake Formationがデータ自動収集するための、Workflow用にロールを作成していきます。 このWorkflowで収集されたデータは、データカタログという形で整理され、Athenaなどの分析ツールから参照するために使われます。
この機構はAWS Glueに依拠するもので、実際Lake Formationの裏ではAWS Glueが動きます。
こちらのロールは、公式ドキュメントに沿って、設定します。 ロールの名前は「LakeFormationWorkflowRole」とします。
ここで注意が必要な点として、S3バケットへのアクセス権限を付与する必要があるケースがあるということです。
なぜならば、AWSGlueServiceRoleには、特定のprefixを持つ、S3バケットへのアクセスのみ許可されているためです。
S3バケットを読み取る権限がないと、Glueでテーブル作成時に以下のようなエラーが発生します。

今回はインラインポリシーでバケットを読み取る権限を付与します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::{BUCKET_NAME}",
"arn:aws:s3:::{BUCKET_NAME}/*"
]
}
]
}
データレイク管理者
データレイク管理者は、AWSLakeFormationDataAdmin の権限が必須です。
次の権限は、オプションとなります。
- AWSGlueConsoleFullAccess
- CloudWatchLogsReadOnlyAccess
- AWSLakeFormationCrossAccountManager
本記事では、オプションの権限も付与しておきます。
次に、「datalake-admin-servicelinkrole-create」という名前で、インラインポリシーとしてサービスリンクロール作成権限と、ロール作成権限を付与します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"iam:CreateServiceLinkedRole",
"iam:PutRolePolicy"
],
"Resource": "*"
}
]
}
後述する、Data lake locationsの設定で、AWSServiceRoleForLakeFormationDataAccessというLake FormationのサービスリンクロールをIAMユーザに付与することになります。(ドキュメント)
iam:CreateServiceLinkedRoleとiam:PutRolePolicyが付与されていないと、以下のような権限エラーが発生します。

最後に、データレイク管理者がWorkflowを利用するため、Pass Roleをインラインポリシーとして付与します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PassRolePermissions",
"Effect": "Allow",
"Action": [
"iam:PassRole"
],
"Resource": [
"arn:aws:iam::<account_id>:role/LakeFormationWorkflowRole"
]
}
]
}
最終的に付与した権限はこちらです。

ここでは、簡単に記載するため、FullAccessのポリシーを利用していますが、実際には要件に応じて適切な権限に絞ってください。
データアナリスト
データアナリスト向けには、Amazon Athena クエリを実行する権限(ここでは、AmazonAthenaFullAccess)を付与します。
注意が必要な点として、Athenaクエリを実行する際、クエリの結果を保存するS3への書き込み権限が必要になります。 S3への書き込み権限がないままAthenaクエリを実行すると、以下のようなエラーが発生します。

なので、インラインポリシーでAthena クエリ結果保存用S3への書き込み権限を付与します。
次のドキュメントを参考に、権限を付与していきます。
Athena クエリの実行時の「Access Denied (アクセスが拒否されました) 」エラーを解決する
本記事では、「write-athena-query-result」という名前で、以下のインラインポリシーを付与します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:AbortMultipartUpload",
"s3:PutObject",
"s3:ListMultipartUploadParts"
],
"Resource": [
"arn:aws:s3:::{BUCKET_NAME}",
"arn:aws:s3:::{BUCKET_NAME}/*"
]
}
]
}
データアナリストに付与するIAMは、最終的にこうなりました。

プロジェクトリーダー
データアナリストよりは広い権限を持ち、データレイク管理者よりは狭い権限を持つユーザを想定して作成します。
以下のようなポリシーを付与します。

また、このユーザは、データレイク管理者としては設定せずにおきます。
(3) Lake Formation構築
データレイク管理者登録
ここでの作業は、「IAM管理者 (AdministratorAccessを持つユーザ)」で行います。
前述したように、AdministratorAccess権限はルートユーザ同等の権限となるので、扱いには注意が必要です。
先ほど作成した、データレイク管理IAMユーザをLake Formation上で、管理者として設定します。
作成したデータレイク管理IAMユーザをLake Formation上で、データレイク管理者として割り当てます。 Lake Formationを初めて開くと、以下のようなダイアログが出てくるので、 「Add other AWS users or roles」を選択し、データレイク管理者とするIAMユーザを選択します。

データレイク管理者設定は、「AdministratorAccess 」の権限を持つユーザによって実施可能です。 しかし、次の2つの権限を付与すれば、「AdministratorAccess 」の権限を持つユーザ以外でも、データレイク管理者設定可能です。
- lakeformation:GetDataLakeSettings
- lakeformation:PutDataLakeSettings
ここでポイントになるのは、Lake Formationでは、「暗黙的なアクセス許可」が存在することです。 例えば、「AdministratorAccess 」は、「lakeformation:GetDataLakeSettings」と 「lakeformation:PutDataLakeSettings」の権限が暗黙的に付与されています。
このほかにも、データレイク管理者・データベース作成者・テーブル作成者にも、それぞれ暗黙的なアクセス許可が付与されています。データレイク構築時、この点を押さえておくことは重要になりそうです。
尚、データレイク管理者IAMユーザでログインし、データレイク管理者に自身を追加しようとすると、権限エラーが発生します。最初、「AWSLakeFormationDataAdmin」を付与したIAMユーザで、自身をデータレイク管理者に設定しようとしたところ、User: arn:aws:iam::xxxx:user/admin is not authorized to perform: lakeformation:PutDataLakeSettings with an explicit denyのエラーが発生しました。
また、注記として、「IAM管理ユーザ (AdministratorAccess AWS 管理ポリシーを持つユーザ) をデータレイク管理者に選択しないことを推奨します。」と公式ドキュメントに記載されています。
データカタログ設定
ここでの作業は、IAM管理者で実施します。
前述のとおり、Lake Formationは、デフォルトでは、「IAMによるアクセスコントロール」のみが適用されるようになっています。 つまり、Lake Formation上での権限管理は、反映されない設定がデフォルトになっているということです。
これは、Lake FormationはAWS Glueに依拠しており、既存のAWS Glueの挙動との互換性を取るためとされています。
しかし、Lake Formationでは、「Lake Formation のアクセス許可」によりきめ細かなアクセスコントロールを取ることが推奨されています。 Lake Formationのアクセス許可を有効化するために、「Data catalog settings」から、IAMによるアクセスコントロールのみ適用される設定を変更します。

この設定に関して、Classmethod様が詳細に解説しています。 AWS Lake Formationにおけるデータカタログ設定の意味について | DevelopersIO
データカタログ権限設定
ここでの作業は、データレイク管理者で実施します。
Athenaからクエリで参照するための、データカタログの設定をしていきます。 データカタログとは、平たく言えばデータレイク保存されているデータを、分析するために整理されたものです。
前提として、Lake Formationは、AWS Glueがバックエンドとして動くため、クローラ、ETLなど、Glue の機能をもとにしています。 データカタログの作り方等は、AWS Glue寄りの話題となるので、本記記事での説明は割愛します。
S3パスの登録
Lake Formationコンソールから、「Register and ingest」> 「Data lake locations」>「Register location」を選びます。 次に、データレイクに登録するS3 Pathを指定し、「Register location」を押下します。 ここでの操作が意味するのは、「Data lake locations」で設定されたS3バケットは、Lake Formationの権限管理配下に入ったということです。


ここで、データレイク管理者にサービスリンクロール作成権限、ポリシー作成権限がないと、以下のようにエラーが発生します。

データベース作成
続いて、データベースを作成します。


データベース・テーブル権限設定
続いて、データベース・テーブルの権限設定に移ります。
今回、Glueを利用してテーブルを作成するので、LakeFormationWorkflowRoleがテーブル作成できるように権限付与します。
データロケーション登録
「Permissions」>「Data locations」>「Grant」を選びます。 今回は、クロスアカウントではなく、同一アカウントの操作なので、「My account」 「IAM users and roles」で、ワークフロー用ロール(LakeFormationWorkflowRole)を指定します。

ここでの操作が意味するのは、指定されたS3パスに対し、指定されたユーザ・ロールがデータベース作成権限を得たということです。
一つ前で設定した、「Data lake locations」と「Data locations」の考え方がややこしいと感じました。
「Data lake locations」と「Data locations」が、各IAMユーザにどのように作用するか、まとめてみます。
バケットA、Bという二つのS3バケットが存在するとし、IAMユーザは本記事で作成している3つです。
尚、AWSLakeFormationDataAdmin権限は、glue:CreateDatabaseポリシーを保持するため、データベース作成は可能です。
また、データレイク管理者は暗黙的にデータベース作成権限を持つので、すべての条件でデータベース作成可能です。
| Data lake locations | Data locations | バケットAデータベース作成 | バケットBデータベース作成 |
|---|---|---|---|
| バケットA | 指定なし | データレイク管理者 | データレイク管理者、PL |
| バケットA | バケットAへの権限をPLに付与 | データレイク管理者、PL | データレイク管理者、PL |
| 指定なし | バケットAへの権限をPLに付与 →データレイク管理下でないので、設定不可 |
データレイク管理者、PL | データレイク管理者、PL |
| バケットB | バケットBへの権限をアナリストに付与 | データレイク管理者、PL | データレイク管理者、※アナリスト |
上記から、「Data lake locations」で指定されたS3バケットに対して、Data locationsで権限付与されていなければ、AWSLakeFormationDataAdmin権限を持っていてもデータベース作成ができないことがわかります。
つまり、Lake Formationの権限管理配下にあるS3バケットに対して、Lake Formationによる権限付与がなければ操作できないということがわかります。
また、Lake Formationの権限管理配下にないS3バケットに対し、AWSLakeFormationDataAdminを持っていれば、データベース作成できることがわかります。
※の部分では、アナリストによるデータベース作成はできますが、 「Unknown error」が発生します。 アナリストのペルソナとして、データベース作成は役割の範囲外となると思います。 ここでは、敢えて権限付与したときの挙動を確かめましたが、通常の運用では役割の分割、設計を行うべきかと思います。
データベース権限付与
続いて、データベースに対して、LakeFormationWorkflowRoleがテーブル作成できるように権限付与します。
「Data catalog」 > 「Tables」 > 「テーブル名」 > 「Action」 > 「Grant」を選択し、「Create Table」権限を付与します。

データカタログ作成
データカタログ(テーブル)は、Lake FormationのBlueprintやGlueの クローラを使い自動で作成する方法と、 コンソールから手動で作成する方法があります。
本記事では、AWS Glueの クローラを利用して、テーブルを作成していきます。 本記事では、Glue自体は詳しく触れません。以下のキャプチャのように設定し、クローラを作成していきます。







クローラを実行すると、テーブルが作成されます。

今回は取り扱いませんが、クロスアカウントで利用する場合、S3のACL設定が必要になる場合もあります。
Glueクローラーで、テーブル作成時にS3から403エラーが返ってきた場合、以下のドキュメントからトラブルシューティング方法を参照できます。
4. まとめ
以上で、Lake Formationを使った、ベースとなるデータレイクの作成は完了です。個人的には、S3やGlueとの連携部分で発生する、IAM権限設定が最初の難関でした。次に、「Data lake locations」と「Data locations」周りの考え方を理解するのに時間がかかりました。
次回、Athenaを利用し、作成したデータレイクからデータ取得ができるかどうかを見ていきます。
Acroquest Technologyでは、キャリア採用を行っています。少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。 www.wantedly.com
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長