こんにちは。社内データサイエンスチームYAMALEXの@Ssk1029Takashiです。 
最近はRTX4090のマシンを買って電気代が上がってきています。
昨今NLP界隈では事前学習モデルが出てからは、検索というのもキーワードでの検索だけではなく、文章を入力にして似たような文章を探す類似文書検索も使われるようになりました。
そんな中で、今回はFAQを対象にした類似文書検索をSentence BERTを使って試してみます。
FAQでよくある困りごと
FAQはあらゆる場面で重要な情報源ですが、いまいち検索がしづらい情報でもあります。
FAQを利用しようとするときはたいていは何か困ったことがあった時に調べに行くものですが、ユーザーが困っている内容をドキュメントと同じような単語で表現するのはときに難しいです。
例えば、何かシステムがあってログインできないという症状を説明するだけでも、「認証が通らない」とか「勝手にサインアウトする」など多様な説明ができてしまいます。
このようなことを解決するために、ユーザーの入力の意味を解釈して、近しい回答を出してくれる検索がFAQ検索では有効になります。
今回やること
今回は以下のステップに沿って進んでいきます。
- 既存のFAQデータセットを使ってSentence BERTをFine Tuning
- Fine TuningしたBERTを使ってFAQの回答をベクトル化
- 同じくFine TuningしたBERTを使って質問文をベクトル化して回答ベクトルを検索

まずは既存のFAQデータセットを使ってSentence BERTをFine Tuningします。
詳細は手法は後述しますが、FAQデータセットはQとAはセットで与えられるので、その組み合わせを類似した文章とみなして学習させます。
そのあと、学習したBERTを使用して、回答文と質問文の文章ベクトルを作成して、コサイン距離を測り類似文章を探します。
この手法で試したいのは、質問文同士の検索ではなく、直接質問文のベクトルから回答文のベクトルが探れるのかというポイントになります。
そのために、質問文同士をペアにするのではなく、質問文と回答文を類似文章としてペアにしてSentence BERTを学習してみます。
Sentence BERTとは
検証に入る前にSentence BERTについて簡単に説明します。
Sentence BERTとは、BERTをベースにより精度の高い文章の埋め込み表現を取得できるようFine Tuningする手法になります。
Fine Tuning方法の詳細は省きますが、簡単に言うと、類似する一組の文章からそれぞれ生成される文章ベクトルが近くなるように学習するという内容になります。
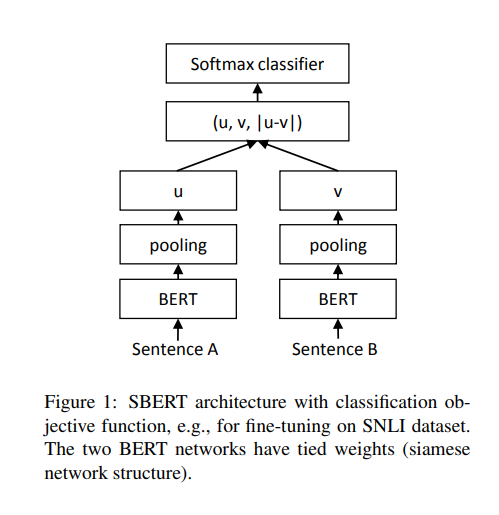
詳細が気になる方はぜひ読みやすいので元論文も読んでみてください。
arxiv.org
検証
それでは実際に検証してみましょう。
FAQデータセットから文章ベクトルを学習する
それでは実際に文章ベクトルを学習してみましょう。
今回使用するデータセットはJapanese FAQ dataset for e-learning systemというe-ラーニングシステムの日本語FAQをデータセットにしたものです。
データセットの内容は質問文が427個とその質問文に対する回答が全部で79個与えられているので、サイズとしては比較的小さいデータセットになります。
また、質問・回答のペアにはそれぞれ「資料」「課題」などのカテゴリが振られています。
zenodo.org
Sentence BERTはロス関数に何を使うかで入力が変わります。
例えば、Cosine Similarity Lossを使用する場合は、文章のペアとその文章の類似度が入力で与えられる必要があります。
今回はロス関数にはTriplet Lossを使用します。
Triplet Lossとは、簡単に言うと近しいものを近づけて、遠いものを遠ざけるように計算するロス関数になります。
詳細は以下のページが詳しく載っているのでぜひ読んでみてください。
qiita.com
Triplet Lossを計算する際には、Sentence BERTには入力として以下の三つを与える必要があります。
- anchor: サンプルとなる文章。今回は質問文を与えます。
- positive: anchorと意味的に近しい文章。今回はanchorに対する回答文を与えます。
- negative: anchorと意味的に遠い文章。今回はanchorと異なるカテゴリの回答文を与えます。
本当はnegativeには同一のカテゴリの文章を与えたほうが、hard negative、つまり識別しづらい負例になり学習に有用なのですが、同一カテゴリ内にデータのバリエーションが少ないので今回は異なるカテゴリのデータを使用します。
上記の形式に合わせて以下のようなデータを用意します。

ここから一行を一つの組として学習していきます。
今回ライブラリにsentence-transformersを使っていきます。
sentence-transformersは文字通りSentence BERTを使って学習・推論するためのライブラリです。
huggingfaceに登録されている事前学習モデルを使用できるなどが便利な点です。
www.sbert.net
まずは、学習するモデルを定義します。
使用するモデルは汎用日本語BERTでもよいのですが、せっかくなので今回はhuggingfaceに登録されている日本語用のsentence bertの事前学習モデルを使用してみます。
huggingface.co
事前学習モデルをそのまま使用する場合は、文章ベクトルを取得するためにPooling層を追加する必要があります。
以下のようなコードになります。
from sentence_transformers import SentenceTransformer, SentencesDataset, InputExample, losses, models bert = models.Transformer('sonoisa/sentence-bert-base-ja-mean-tokens-v2') pooling = models.Pooling(bert.get_word_embedding_dimension()) model = SentenceTransformer(modules=[bert, pooling])
次にTriplet Lossで学習するために、dataset, dataloaderを定義して、model.fit()の入力にします。
from torch.utils.data import DataLoader train_dataset = SentencesDataset([InputExample(texts=[row["anchor"], row["positive"], row["negative"]]) for index,row in datasets_df.iterrows()], model) train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=8) train_loss = losses.TripletLoss(model=model) model.fit( train_objectives=[(train_dataloader, train_loss)], epochs=5, evaluation_steps=1, warmup_steps=1, output_path="./sbert", )
今回epochsなどのハイパーパラメータは適当に決めているので、データ数などを見て調整してください。
これで事前学習モデルにFAQの回答と質問の類似度を学習させることができました。
回答文から文章ベクトルを生成する
次は回答文を文章ベクトルに変換します。
通常ベクトル検索にはFAISSやValdなどのベクトル検索ライブラリを使うのが一般的ですが、今回は対象データも少なくまずは簡単に試したいのでリストで持って逐次にコサイン類似度を計算することにします。
# 回答文書の一覧を取得 answers = list(datasets_df["positive"][~datasets_df["positive"].duplicated()]) # ベクトルに変換 corpus_embeddings = model.encode(answers, convert_to_tensor=True)
質問文から近しい回答を見つける
最後に質問文もベクトルに変換して、回答文のベクトルとのコサイン類似度を計算して近しい文章を取得します。
from sentence_transformers import util query = "生徒登録がしたい" query_embedding = model.encode(query, convert_to_tensor=True) cos_scores = util.cos_sim(query_embedding , corpus_embeddings) top_results = torch.topk(cos_scores, k=3) print("\n\n======================\n\n") print("Query:", query) print("\nTop 3 most similar sentences in corpus:") for score, idx in zip(top_results[0][0], top_results[1][0]): print(answers[idx], "(Score: {:.4f})\n".format(score))
すると以下のような結果が得られます。
====================== Query: 生徒登録がしたい Top 3 most similar sentences in corpus: 履修申請した受講生は「授業情報」機能の履修状態が「本登録」と表示されます。一方、教員が受講生を手動登録、あるいは学生が自己登録することでコースに登録された場合「仮登録」と表示されます。仮登録でもkibacoのコースを利用することはできますが、別途履修申請しなければ単位を取得できません。なお、以下の場合、受講生は仮登録のままとなります。1. 科目等履修生や研究生などの非正規学生。表示を本登録へ変更する必要がある場合は、教務課や国際課などの事務あるいは授業担当の先生から システム管理室2(e-learning-ml●ml.tmu.ac.jp、●をアットマークに変えてください) へ連絡してください。2. 事務情報システムに登録されていないコースをkibaco上で作成し利用している場合。学生をTA/チューターとして登録する場合には、「授業情報」機能の「受講生・TAを登録」で学生を登録する際に「TA/チューター」権限を与えてください。詳細は授業担当者向けマニュアルの31~33ページをご覧ください。なお、資料は教員が作成する必要があります。" (Score: 0.8198) 科目に対応するコースへ学生を登録すれば、履修申請前でも受講生をコースへアクセスさせることができます。登録方法の一つに、コースを自己登録可能に設定して学生に自己登録させる方法があります。コースへの自己登録の可否は、各授業の担当教員が設定できます。学生が自己登録したいと思っても、授業担当の先生が設定しなければ自己登録できません。なお、学部1年生は、前期の情報リテラシー実践I/IAの初回授業で情報倫理講習を受講するまでkibacoを利用できません。詳細は授業担当者向けマニュアルの34ページをご覧ください。" (Score: 0.8008) 仮登録の受講生が履修申請した場合、翌日に本登録へ変更されます。履修申請しない場合は履修申請期間を過ぎても仮登録のままコースに残ります。授業担当教員は仮登録の受講生をコースから登録解除することができます。ただし、以下の場合、履修申請していても受講生は仮登録のままとなりますので注意してください。1. 科目等履修生や研究生などの非正規学生。表示を本登録へ変更する必要がある場合は、教務課や国際課などの事務あるいは授業担当の先生から システム管理室2(e-learning-ml●ml.tmu.ac.jp、●をアットマークに変えてください) へ連絡してください。2. 事務情報システムに登録されていないコースをkibaco上で作成し利用している場合。なお、受講生が履修申請を取り下げた場合のみ、本登録の受講生がコースから登録解除されます。 (Score: 0.6863)
上記の例では近しい回答を出せているように見えます。
単語が揺れてもいい感じに回答を取得できるのか検証
例として以下の回答が欲しい場合を考えてみます。
まず、パスワードの有効期限が過ぎたことでkibacoを利用できなくなった場合、利用停止後2週間以内ならTMUNER上で新しいパスワードを設定できます。TMUNER上で「利用者メニューログイン」から、「利用者メニューログインはこちら」でログインして確認します。それ以外の場合でユーザIDやパスワードを忘れてしまった場合はこちらを参照してください
データセット上では以下の質問文に対して上記の回答が与えられています。
- ID、パスワードが分からない。
- kibacoのログインパスワードを忘れてしまったので、パスワードの再発行をしたい。
- 荒川キャンパスの学生ですが、kibakoを利用したいのですが、ユーザーIDとパスワードを忘れてしまいました。
- ログインパスワードの再設定を行いたい。
- 日野キャンパスの学生ですが、kibakoを利用したいのですが、ユーザーIDとパスワードを忘れてしまいました。
なので、検証として上記の質問と回答で使われている単語を避けて「アカウント情報を紛失した」という問い合わせにしてみます。
結果としては、以下になりました。
Query: アカウント情報を紛失した Top 3 most similar sentences in corpus: まず、パスワードの有効期限が過ぎたことでkibacoを利用できなくなった場合、利用停止後2週間以内ならTMUNER上で新しいパスワードを設定できます。TMUNER上で「利用者メニューログイン」から、「利用者メニューログインはこちら」でログインして確認します。それ以外の場合でユーザIDやパスワードを忘れてしまった場合はこちらを参照してください。" (Score: 0.5902) 新学期が始まる約一ヶ月までの情報を基にしているので、それ以降の変更は反映されていません。授業担当者ではなくなった場合、登録を解除する必要があります。登録解除は システム管理室2(e-learning-ml●ml.tmu.ac.jp、●をアットマークに変えてください)宛てに申請メール(科目名、授業番号、解除する教員氏名、解除する教員の教育研究用情報システムID)を主担当教員からお送りいただくか、主担当教員をCCに入れてお送りいただく必要があります。 (Score: 0.4353) 仮登録の受講生が履修申請した場合、翌日に本登録へ変更されます。履修申請しない場合は履修申請期間を過ぎても仮登録のままコースに残ります。授業担当教員は仮登録の受講生をコースから登録解除することができます。ただし、以下の場合、履修申請していても受講生は仮登録のままとなりますので注意してください。1. 科目等履修生や研究生などの非正規学生。表示を本登録へ変更する必要がある場合は、教務課や国際課などの事務あるいは授業担当の先生から システム管理室2(e-learning-ml●ml.tmu.ac.jp、●をアットマークに変えてください) へ連絡してください。2. 事務情報システムに登録されていないコースをkibaco上で作成し利用している場合。なお、受講生が履修申請を取り下げた場合のみ、本登録の受講生がコースから登録解除されます。 (Score: 0.4321)
ほしい回答が得られていますね。
このように、単語の揺れにはある程度対応できるFAQ検索がSentence BERTで実現できそうです。
まとめ
今回はSentence BERTを使って、FAQの類似文章検索を試してみました。
キーワード検索でもヒットしない回答が、類似文章検索を使えば取得できそうです。
Sentence BERT自体は、文章のペアを作れるデータがあれば適用可能なので、他の分野でも活用できそうですね。
ぜひ試してみてください。
それではまた。
Acroquest Technologyでは、キャリア採用を行っています。
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。