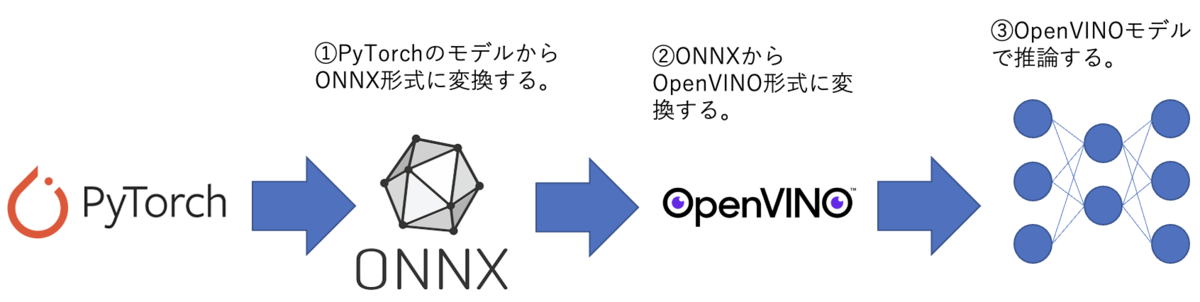
アクロクエスト アドベントカレンダー 12月7日 の記事です。
こんにちは、機械学習チーム YAMALEX メンバの駿です。
この度、東北大学、理化学研究所が主催する「 AI 王~クイズ AI 日本一決定戦~第3回コンペティション」(以下、AI王)に YAMALEX として参加しました。
初めて参加するコンペで、結果としては入賞できませんでしたが、今回は参加した感想をお伝えします。
技術的な詳細はこちらのスライドにまとまっているので、併せてごらんください。
YAMALEX とは
YAMALEX とは2022年夏に Acro 社内で発足した、 会社の未来の技術を創る、データサイエンスチーム です。
Kaggle Grandmaster の山本を中心に、若手のデータサイエンティスト5人がメンバーです。
最先端技術の調査、実証を通し、会社としてのデータ分析事業の方向性を示すと同時に先端を切り開くデータサイエンティストになることを目指して活動しています。
YAMALEX についてもっと知りたい方はこちらの記事もご覧ください。

AI 王とは
AI王とは、日本の質問応答研究を推進させることを目的として、クイズ問題を題材とした質疑応答データセットを用いて、より正確に答えを出すことができるモデルを作成するコンペティションです。

2020年の第1回から毎年行われており、今回が第3回となります。
第1回は20個の選択肢の中からクイズの回答を選択するものでしたが、第2回からは自由回答になっていて、
回を重ねるごとに難易度が上がっています。
そんな中、 YAMALEX として AI 王となるため、挑戦を決めました。
参加のモチベーション
QA の経験を積みたい
QA システム自体は、チームメンバがほぼ扱ったことが無かったので このコンペを知った際に、チャレンジしたくなった(今回、初参加です)。
日本語の NLP コンペに参加したい
Kaggle などには参加したことはあるが、問題のほとんどが英語の文章なので 日本のコンペにチームとして出たかった。
チームでまとまってコンペに参加してみたい
YAMALEX チームはまだ個人参加はあれど、チームでコンペに取り組んだ ことがなかったので、チームで取り組んでみたかった。
スケジュール
| 時期 |
概要 |
内容 |
|---|---|---|
| ある10月末頃 | AI 王へのチャレンジが始動する | とあるチームメンバが唐突に本格的に AI 王をやりたいと発言したところから、私たち YAMALEX チーム5人の挑戦は始まりました。 |
| ~11月7日 | 作戦を立てる | 既存ベンチマークの動作確認と昨年度のソリューションを読んで作戦を立てて、分担を決めました。 役割は、 Retriever ( BPR/DPR ) / FiD /外部データセット取得で、3人、1人、1人ほどです。 Retriever が最もやることが多かったのでその部分に人を多めに担当してもらうようになりました。 |
| ~11月14日頃 | チーム毎に作業を進める | チームに分かれて以下に取り組んでいました。 QA に取り組んだメンバがいないため勘所が分からないこともあり、一つ一つ、影響のあるパラメータや手法を考えて確認をしていました。 |
| 11月18日頃 | 外部データを追加する | 計算時間が膨大になる Wikipedia のデータを新たに追加する解法を取り入れました。 Dev/Test 間の LB での相関が取れなくなり思うようにスコアが伸びず、頭を抱えるようになったのはこの頃です。 |
| リーダーボード 締切直前 |
アンサンブルを導入する | 複数のモデルを計算する時間が厳しい中、シンプルな Voting を行うアンサンブルを試みました。 アンサンブルのバリエーションもいくつかあると思いますが、この部分は詰め切れませんでした。 最終提出は LB 最高スコアに届きませんが、このアンサンブルした結果にしています。 Dev/Test で相関が取れていないことから問題傾向によるブレがあると予測し、安定した結果を出すためにシンプルな Voting を行うアンサンブルが妥当だといった判断です。 |
| 11月23日 | リーダーボード提出締切 | テストデータでのスコアの確認、他チームの進捗確認がこれ以降できなくなる。 |
| リーダーボード 締切後 |
Dockerfileを作成する | リーダーボードへの提出が締め切られ、システムの最終提出のみとなってからは、 Dockerfile の作成に追われていました。 提出のために不要なファイルを消すなど試行錯誤をしていました。 |
| 11月26日 | システム最終提出締切 | 本当に最後の締め切り。ここで提出した Docker イメージを使って未知の問題を解き、スコアと順位が確定する。 |
感想
チームとして話し合いながら進めるのが楽しい!
私はあまり NLP が得意ではないのですが、モデル改良に向けてチームでの話し合いに参加しました。
その中で、クイズを見ながら「こういう問題にはこういうアプローチをしたい」や「これができると精度上がらないですか」 などの意見を出して、できそう/できなそうを議論することができました。
人がクイズを答えるときにやっていることと同様にやろうとすると、 複数モデルを用意して、問題文から適切なモデルを選択しないといけず、 複雑かつ巨大になってしまうことなども分かり、興味深かったです。
例:ですが問題は「ですが」の前と後の対比をできるモデルがあれば強いが、他の問題に対しては全く使い物にならない。締め切りまじかになると、普段の生活では味わえない、ひりひり感を会話から感じる事ができました。
NLP 分野の知識が広がった!
AI 王では主催者がベースラインのモデルを提供しており、初心者でも環境があれば動かせる状態から始めることができました。
また、ベースラインを動かして各機能の入出力や中のコードを見ることで、 QA タスクのアプローチを知ることができました。
一つのやり方を学ぶことができたため、別の機会に別のモデルを見たときには、 今回のモデルと比較することで、どんなことをやっているかが分かりやすくなると思います。スコアが上がっていくのを見るのが楽しい!
これはコンペティションなら言わずもがなですね。
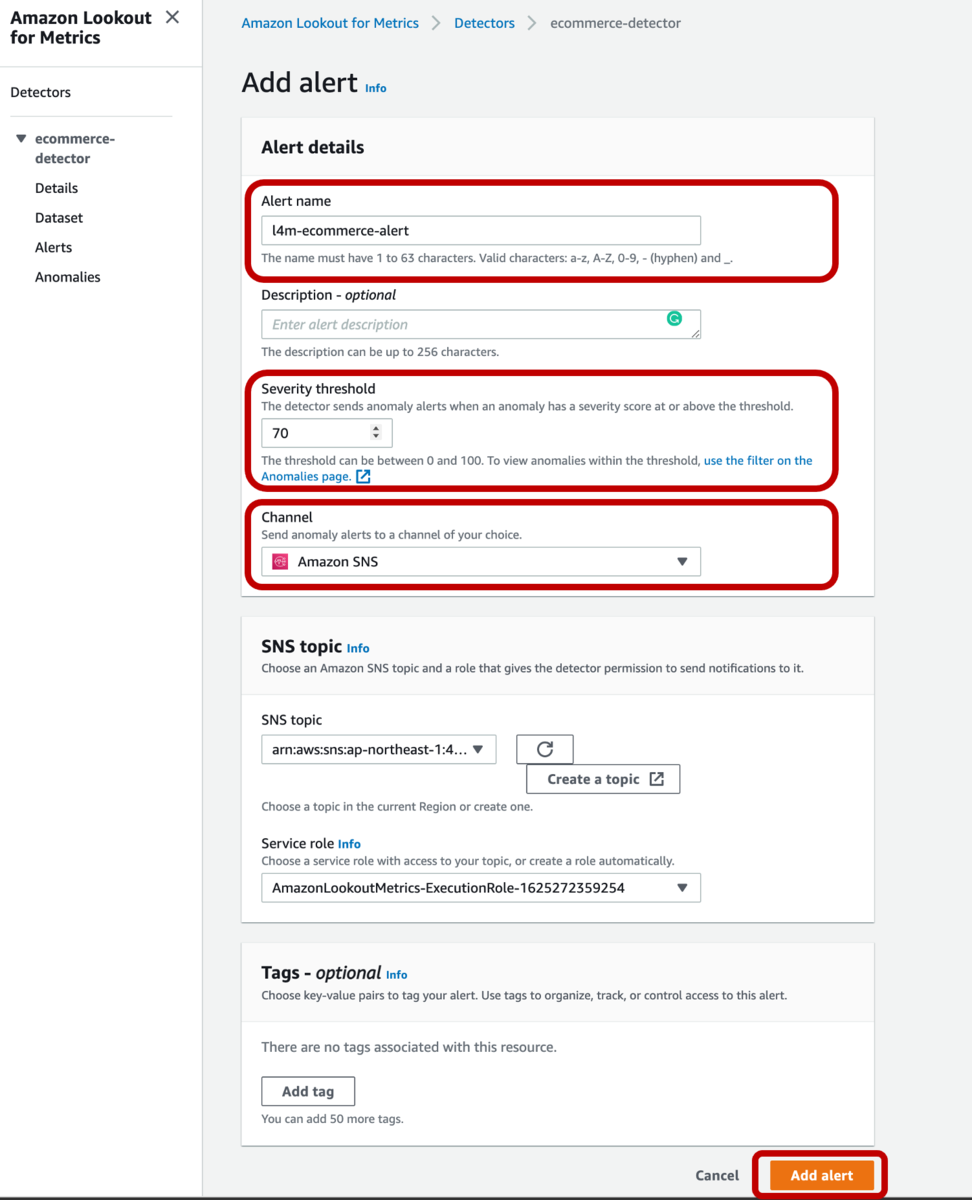
下の図はリーダーボードスコア(LB Score)といって、提出回数ごとに、AIによる質疑応答のスコアの遷移を表しています。
当社のデータだけを示していますが、コンペ開催中は、リーダーボードに各チームの暫定スコアと順位が表示されており、 上の人のスコアに徐々に近づいて追い抜いていく、逆に追い越されるなど、 他チームとの駆け引きも面白いポイントでした。
今回コンペのYAMALEXチームスコアの遷移
まとめ
今回は AI 王に参加した感想を書いてみました。
残念ながら、初参加で入賞!とはいきませんでしたが、確実に YAMALEX チームとしての強さとチームワークは上がったと思います。 この経験を糧に次の挑戦をしていきます。
開催していただいた運営の方々、ありがとうございました!
Acroquest Technologyでは、キャリア採用を行っています。少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。 www.wantedly.com
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長