この記事は Elastic stack (Elasticsearch) Advent Calendar 2020 の 22日目の記事になります。
こんにちは、@shin0higuchiです😊
今回のテーマは、「Elasticsearchで教師あり機械学習」ということで、Data Frame Analyticsの機能を紹介します。
はじめに
2017年ごろから、Elasticsearchには時系列データの異常検知に特化した、教師なしの機械学習機能がありました。
詳しくは、昨年(2019年)のAdvent Calendarで @yukata_uno さんが
「Elastic Machine Learningの歴史を振り返る」という記事を書いていらっしゃるのでそちらをご参照ください。
今年は Elasticsearch の Ver.7.2 で transform が利用可能となり、
そこから outlier detection, regression, classification などの機能が続々リリースされました。
本記事では、その中の Classification を利用して、実際に機械学習を試してみます。
※X-Packの有償機能を利用するため、トライアルライセンスを有効化しています。
利用するデータについて
データセットとしてはこちらを利用します。
www.kaggle.com
データに含まれる「年齢」、「給与」、「婚姻状況」、「クレジットカードの制限」、「クレジットカードのカテゴリ」などの情報から、その顧客がクレジットカードを解約するかどうかを予測することを今回の目標としましょう。
Attrition_Flagのカラムに「Existing Customer」「Attrited Customer」の2値が入っており、これを予測する形になります。
では、CSVファイルをKibanaから取り込んで中身を見てみましょう。
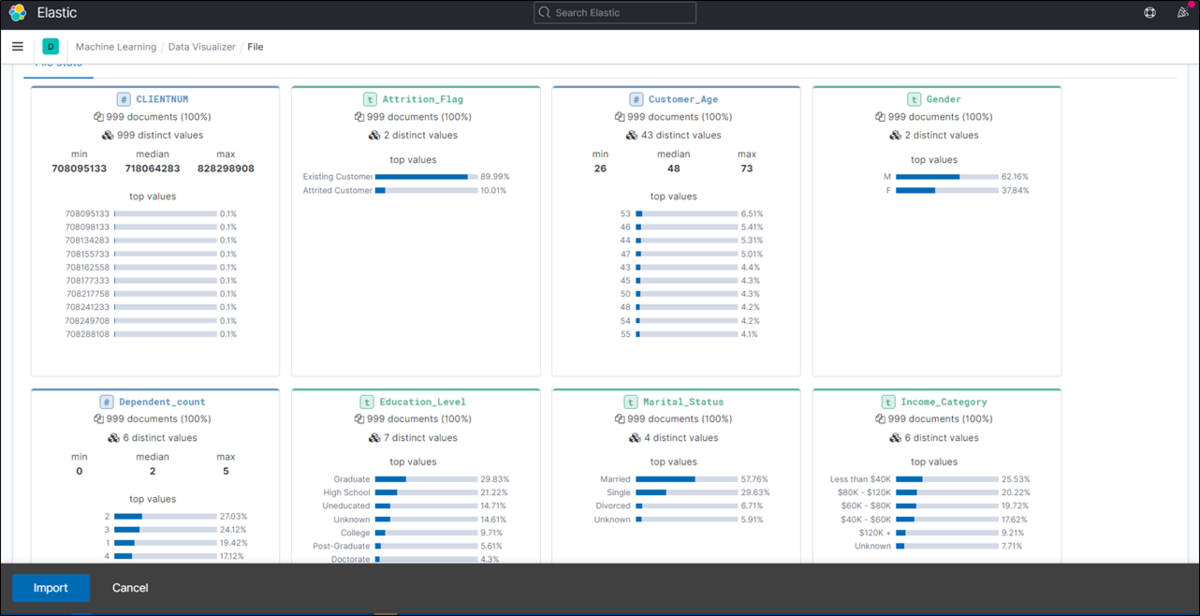
bank_churners という名前のインデックスに取り込みます。
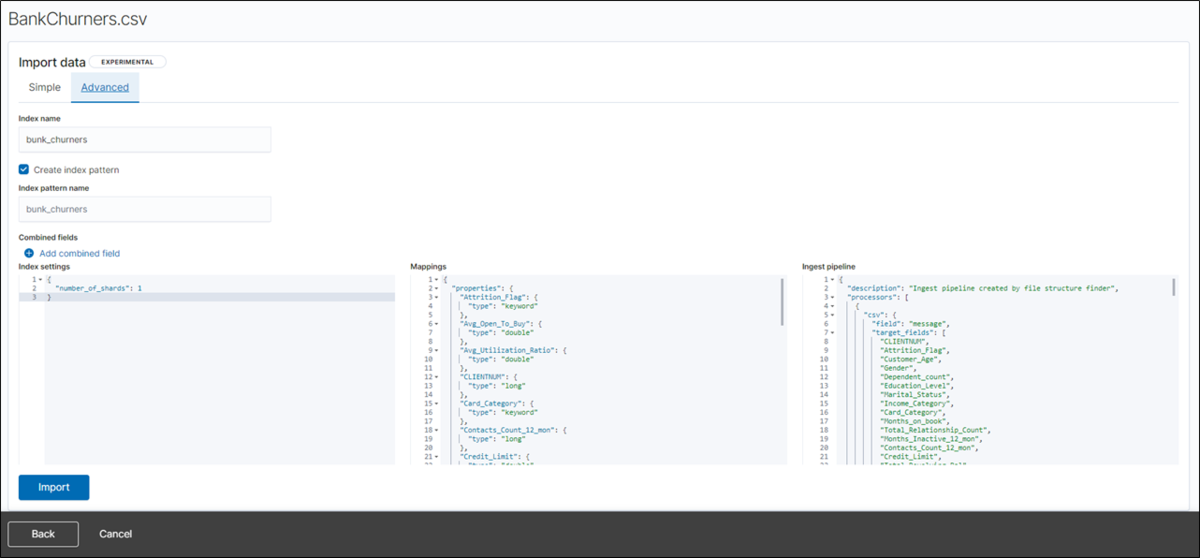
機械学習ジョブの作成
Machine LearningのメニューからData Analytics Jobの「Create job」を選択し...
Classificationを選択します。
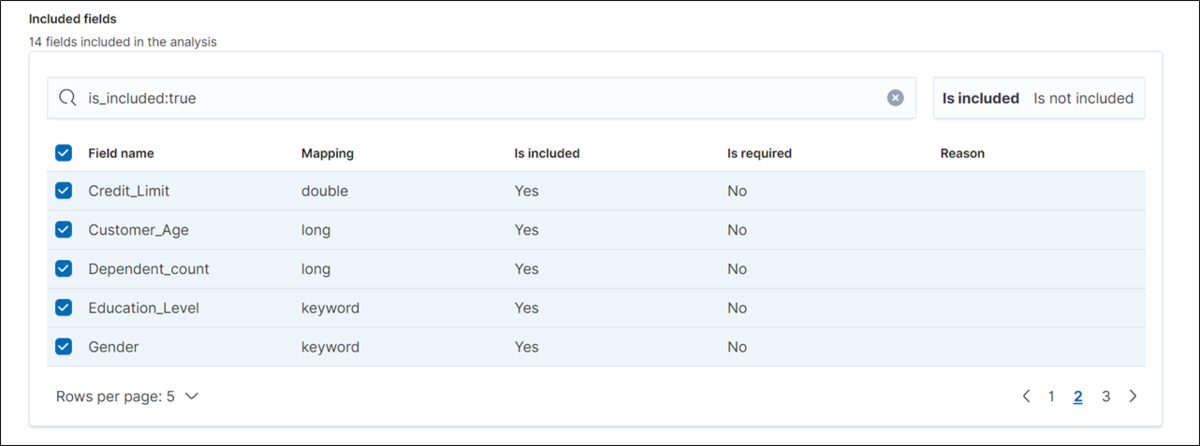
Dependent variable には分類の対象となる Attrition_Flag を指定します。

分析に利用するフィールドはチェックボックスで選択することができます。
ここでは前述の「年齢」、「給与」、「婚姻状況」、「クレジットカードの制限」、「クレジットカードのカテゴリ」を含む14フィールドを指定しています。
ElasticsearchのClassificationでは、内部的にBoosted Decision Tree Regressionによる学習をおこないます。
設定項目は分析の種類によって異なりますが、Classificationの場合は以下の通りです。
| 項目名 | 説明 |
|---|---|
| Feature importance values | 結果に大きく影響したカラムを取得する最大数 |
| Prediction field name | 予測結果を入れるフィールド名 |
| Top classes | 分類するクラス数 |
| Model memory limit | モデルの上限メモリ量 |
| Maximum number of threads | 分析時の最大スレッド数 |
ハイパーパラメータについては、内部で適切な値を選択してくれるようなので、詳しくない場合はデフォルトで良いでしょう。ここでは説明を割愛します。Hyperparameter optimization | Machine Learning in the Elastic Stack [7.10] | Elastic
設定の詳細はこちらをご参照ください。
Concepts | Machine Learning in the Elastic Stack [7.10] | ElasticClassification | Machine Learning in the Elastic Stack [7.10] | Elastic
結果の確認
結果画面では、影響度の大きいカラム・モデルの評価値・推定結果などが確認可能です。
まずは、影響度の大きいカラムのランキングを見てみましょう。
Avg_Utilization_Ratio, Months_Inactive_12_mon, Contacts_Count_12_monなどが上位となっています。カードの利用率や過去12カ月の動きが少ない人が解約しやすいと思われるので、感覚的には正しそうな印象ですね。
※表示されるフィールド数は、先ほど設定したFeature importance valuesによります。

そしてこちらが、モデルの評価値です。
実際の推論結果と、正解ラベルをマトリクスで示したものになります。
解約しそうなユーザーを漏れなく見つけることが重要になるので、Attrited Customer側の正解率をもっと上げたい(再現率を上げたい)印象はあるものの、解約と継続の正解率はそれぞれ68%, 80%となっており、総じて悪くない結果なのではないでしょうか。

作成したモデルの利用
学習したモデルは、inferenceという機能を通じて、ingest nodeの processor や、Aggregation から利用することができます。
たとえば次のような ingest processor を用意することで、新規に取り込むドキュメントを学習済みのモデルで分類することができます。
{ "inference": { "model_id": "bank_churners-1608484239997", "target_field": "BunkChrner_prediction_infer", "inference_config": { "classification":{ "num_top_classes": 2, "results_field": "prediction", "top_class_results_field": "probabilities" } } } }
※ model_idは GET /_ml/trained_models で確認することができます
Aggregationについては割愛します。親となるAggregationの値に対して推論をかける形になりますので、 inference processorと基本的な設定内容は同じです。詳しくはこちらを参照してください。Inference bucket aggregation | Elasticsearch Reference [master] | Elastic
まとめ
以上のように、Elasticsearchの機械学習が大幅に強化され、専門的な知識がなくとも利用できるようになって来ています。Elasticsearchの強みは、集約したデータを様々なユースケースに横断的に活用できる点だと思っていますが、今回紹介した機能はさらにその幅を広げてくれるのではないかと思っています。
皆さんも是非ElasticsearchのData Frame Analyticsを試してみてください。
それでは。
Acroquest Technologyでは、キャリア採用を行っています。
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。【データ分析】
Kaggle Masterと働きたい尖ったエンジニアWanted! - Acroquest Technology株式会社のデータサイエンティストの求人 - Wantedlywww.wantedly.com