こんにちは、安部です。 最近急に、暖かさを通り越して暑いぐらいになってきましたが、皆さまいかがお過ごしでしょうか。
最近急に、暖かさを通り越して暑いぐらいになってきましたが、皆さまいかがお過ごしでしょうか。
季節外れかなとも思いつつ、もう半袖で過ごしたいくらいの気候ですね。
さて、今回は、OpenAIのAssistants APIの使い方を紹介していきます。 題材は「PDFを和訳して要約してもらう」としました。 これはWeb版のChatGPTでも単にPDFファイルを添付して依頼すればできますが、APIの使い方を示すサンプルとしてはちょうどよいと思います。
最新情報については以下の公式ドキュメントをご覧ください。
https://platform.openai.com/docs/assistants/overview
https://platform.openai.com/docs/api-reference/assistants
それでは早速、Assistants APIの使い方を見ていきましょう。
1. Assistants APIとは
Assistants APIは、開発者が独自にAIアシスタントを組み込んだアプリケーションを開発できるようOpenAIから提供されているAPIです。 AIアシスタントとは、要はCopilotやChatGPTみたいなもののことです。
旧来提供されていたChat Completions APIはステートレスでしたが、Assistants APIはステートフルになったため、メッセージ履歴の管理やモデルの最大トークンに合わせたメッセージの切り捨てなどの処理を抽象化してくれます。
2. Assistantsには何ができるのか
AssistantsはChatGPTでできるような会話はもちろんのこと、Code Interpreter・Knowledge Retrieval・Function Calling という3つの機能(ツール)を使用できます。各機能に関する詳細な解説は割愛しますが、それぞれ概ね以下のような機能です。
Code Interpreter
サンドボックス化された実行環境でPythonコードを記述し、実行することができます。このツールは、多様なデータやフォーマットのファイルを処理し、データやグラフの画像を含むファイルを生成できます。
Knowledge Retrieval
ユーザーから提供されたドキュメントなど、アシスタントのモデル外からの知識でアシスタントを補強します。 これにより、自社製品のマニュアルなど固有の情報に基づいた回答をアシスタントにしてもらうことができるようになります。
Function calling
文字通り、アシスタントに関数呼び出しをさせることができます。これにより、特定の情報は外部APIを使って取得し、その情報を含んだ自然な応答をアシスタントに返させたり、外部アプリを操作させたりすることができます。
3. Assistants APIを実際に使ってみる
それでは、実際にAssistants APIを使っていきましょう。冒頭で述べたように、PDFファイル("Attention is All You Need"という有名論文)を渡してその要約などをしてもらいます。
以下の順にやっていきます。
準備
Assistantの作成
Threadを作成し、Messageを追加
Threadの実行
実際のユースケースでは、Webアプリケーションなどに組み込むことで、ユーザからの入力に応じてAssistantへのメッセージ送信などを行うことが多いかと思います。
今回はあくまでAPIの使い方を解説する目的なので、フロント側の処理などは省略しています。
3-1. 準備
本記事では、OpenAI Python API libraryを使ってAssistants APIの使い方を見ていきます。
紹介するサンプルコードは、ローカル環境やJupyter Notebookなどで動かすことを想定しています。 OpenAIのAPIキーを取得し、OPENAI_API_KEYという環境変数に登録しておいてください。
なお、Assistantsの動きを試したいだけであれば、OpenAIサイト内のPlayground > Assistantsで試すこともできます。
3-2. Assistantの作成
それでは、最初のステップとしてAssistantを作成していきましょう。
Assistant作成時に入力する項目のうち、重要なものは以下の通りです。
| 項目名 | 内容 |
|---|---|
| model | 使用するモデル |
| file_ids | アシスタントに覚えてもらいたいファイル |
| name | アシスタントの名前 |
| instructions | アシスタントの方向づけなどに使われる指示 |
| tools | アシスタントが利用できるツール |
Pythonで実装すると、以下のようになります。
ここでは、モデルとしてgpt-4-turbo-previewを指定し、Knowledge Retrievalの機能を有効にしています。また、ローカルに置いてあるPDFファイルをアシスタントに渡すことで、これを知識ベースに加えてもらいます。
from openai import OpenAI # 特に指定しなければ、環境変数OPENAI_API_KEYを参照してアカウントとの紐付けが行われる client = OpenAI() file = client.files.create( file=open("attention.pdf", "rb"), purpose='assistants' ) assistant = client.beta.assistants.create( name="general-assistant", instructions="あなたはチャットサービスのアシスタントです。問い合わせに対し、可能な場合は知識ベースにある知識に基づいて回答してください。", model="gpt-4-turbo-preview", tools=[{"type": "retrieval"}], file_ids=[file.id] )
これを実行し、Assistantが作成されたか確認してみます。OpenAIのサイト内のAssistantsを開いてみましょう。 ここでは、アカウントに紐づいたアシスタントの一覧をGUIで確認したり新規作成したりできます。
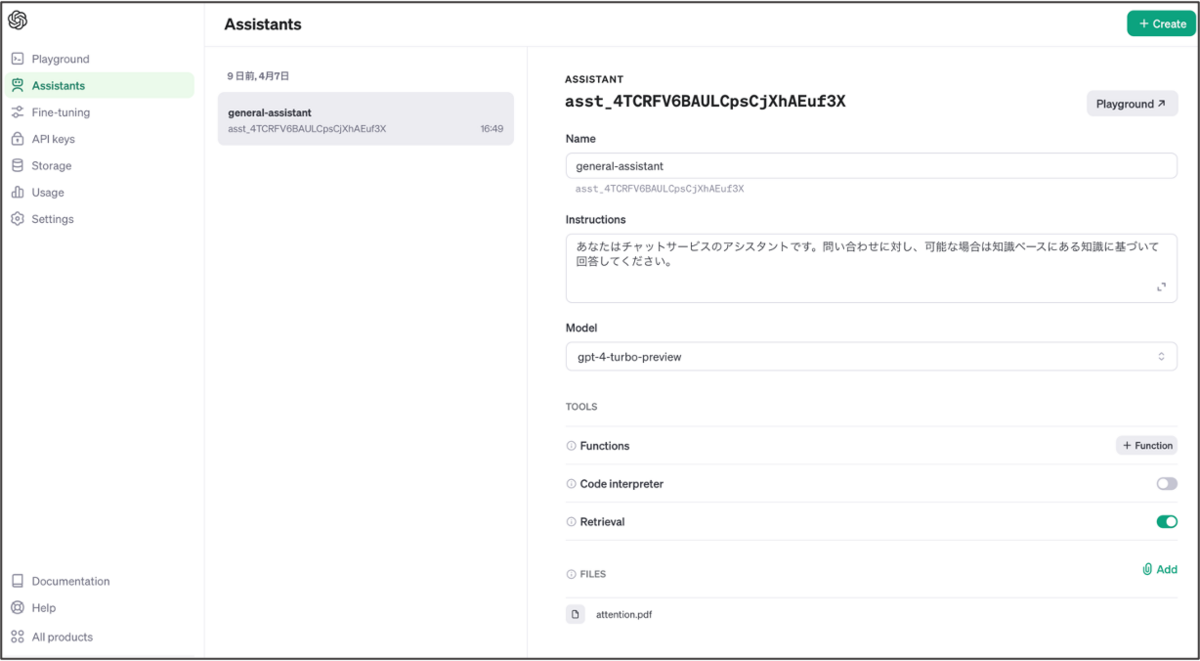
確かに、作成したAssistantが確認できていますね。添付したファイルも問題なくアップロードされているようです。
ついでに、Storageも確認してみます。
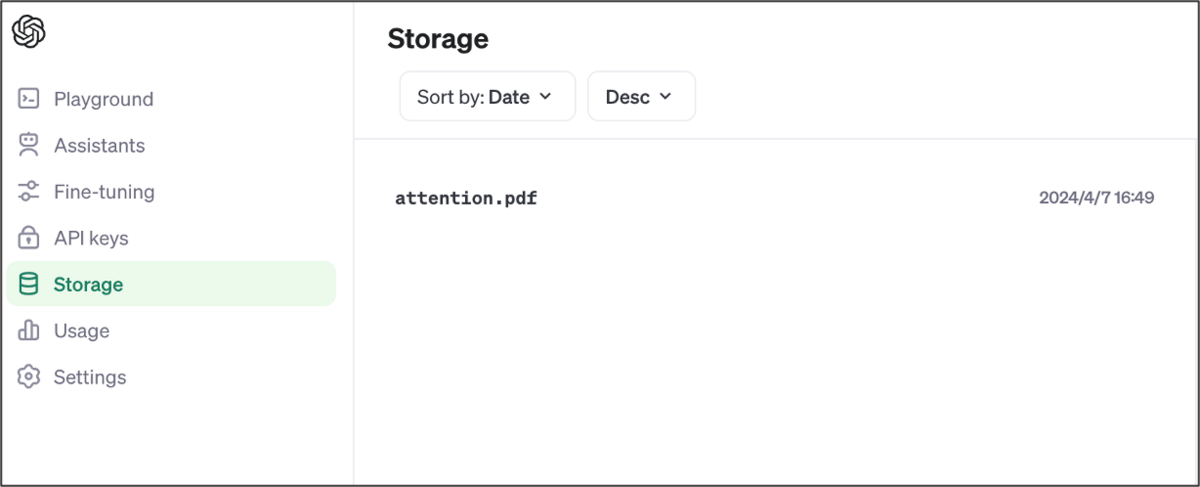
こちらにも、アップロードした画像が格納されています。
なお、今回のように1回限りのアシスタント作成であれば、最初から"Assistants"からGUIを使ってやってしまっても問題ありません。
Webアプリに組み込んでユーザごとにアシスタントを自動作成する場合などに、アシスタントの作成APIを利用することになるかと思います。
3-3. Threadを作成し、Messageを追加
無事にPDFファイルを保持したAssistantを作成できたので、Threadを作成してメッセージを追加していきましょう。
# Threadの作成 thread = client.beta.threads.create() # メッセージをThreadに追加 message = client.beta.threads.messages.create( thread_id=thread.id, role="user", content="Attention is All You Needという論文の内容を、要約して教えてください" )
Threadとは、アシスタントとユーザー間の会話セッションの単位です。 メッセージを保存したり、会話長をモデルのコンテキスト長に適合させるために自動切り捨て処理などを実行してくれます。
コードを見てもらってわかる通り、Threadは最初はアシスタントとは独立して定義します。 後ほどThreadを実行(Run)する際に、どのアシスタントに応答させるかを指定します。
ちなみにメッセージには、画像・テキストなどのファイルを含めることも可能です。
3-4. Threadの実行
それでは、Threadを実行し、回答を表示してみましょう。 Threadの実行(run)とは、Thread上でアシスタントを呼び出すことです。
Threadを実行することで、アシスタントが応答を返してくれます。
# 作成済みのAssistantを取得 assistant = client.beta.assistants.retrieve(assistant_id='asst_4TCRFV6BAULCpsCjXhAEuf3X') # Threadの実行 run = client.beta.threads.runs.create( thread_id=thread.id, assistant_id=assistant.id ) # アシスタントが回答のメッセージを返したら表示する wait_response(client, thread.id, run.id) print_thread_messages(client, thread.id)
回答待ちとメッセージの出力用関数は、以下のように作りました。
実際にサービスに組み込む際などは、返答を一気に表示するのではなく1文字ずつ出力するなどの工夫をするかと思いますが、ここでは単に回答を待ち、結果を全て出力するという処理にしています。
def wait_response(client, thread_id, run_id): """アシスタントが回答を返すまで待つ""" while True: time.sleep(5) # 実行ステータス取得 run = client.beta.threads.runs.retrieve( thread_id=thread_id, run_id=run_id ) status = run.status if status in ["completed", "cancelled", "expired", "failed"]: break def print_thread_messages(client, thread_id): """メッセージを出力する""" msgs = client.beta.threads.messages.list(thread_id=thread_id) for message in msgs: print({"role": message.role, "message": message.content[0].text.value})
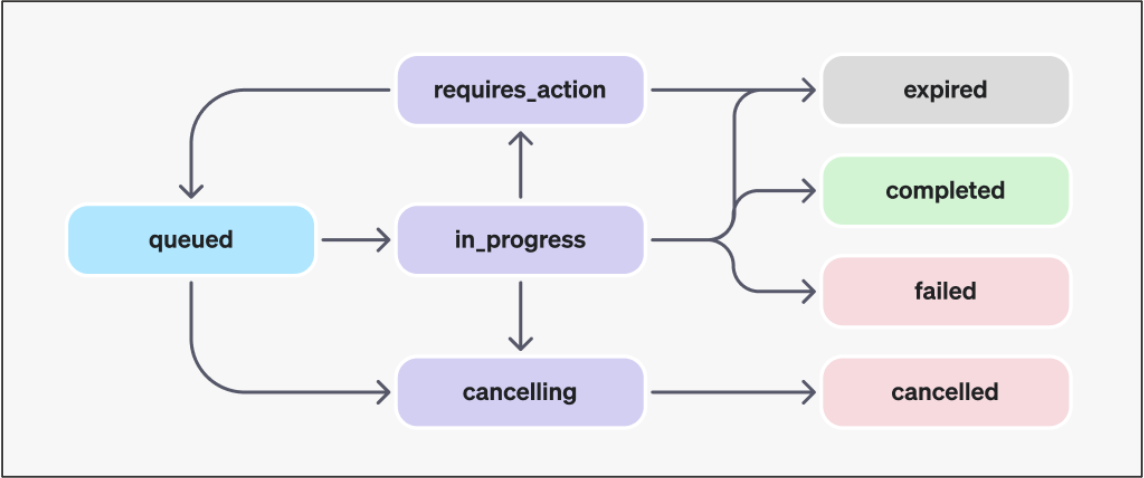
ちなみに、Runのライフサイクルは以下のようになっており、"completed"や"cancelled"など完了のステータスになったところで結果を出力するようにしております。
こちらを実行した結果は、次のようになりました(メッセージ部分だけ載せています)。
論文「Attention Is All You Need」は、従来の系列変換モデルが複雑な再帰的(RNN)や畳み込みニューラルネットワーク(CNN)をベースにしており、 それらがエンコーダとデコーダを経由して接続される場合、その接続に注意機構が使われることが多いと指摘しています【7†source】。 これらのモデルの計算は基本的に連続して行われるため、トレーニング時の並列化が制限されるという問題がありました【8†source】。 この論文では、全体に渡って自己注意機構だけに依存する新しいネットワークアーキテクチャである「Transformer」を提案し、再帰や畳み込みを完全に排除しています。 これにより、モデルはより並列化可能で、トレーニング時間も大幅に短縮されると共に、品質も向上することを示しています【7†source】【8†source】。 Transformerモデルはエンコーダとデコーダから構成され、それぞれが自己注意機構と点ごとの全結合層のスタックで構成されています【10†source】。 この自己注意機構は、クエリと一連のキー・値のペアを出力にマッピングする関数として説明されており、出力は値の加重和として計算されます【11†source】。 2つの機械翻訳タスクでの実験により、このモデルは既存の最高の結果を上回り、英語からドイツ語への翻訳タスクにおいて28.4 BLEU、 英語からフランス語への翻訳タスクにおいては新しい単一モデルの最高スコアである41.8 BLEUを達成しました。 さらに、英文構文解析など他のタスクへの応用も成功しており、Transformerが幅広く汎用的に利用可能であることが確認されています【7†source】。
メッセージ内の【7†source】のような表記は、引用を表しています。引用された文章一覧は、message.content[0].text.annotationsで取得できます。
詳細は以下のドキュメントをご覧ください。
https://platform.openai.com/docs/assistants/how-it-works/message-annotations
4. 価格
Assistants APIの料金発生は、使用モデルに基づくトークンベースの課金と、Retrievalなどツールの使用にかかる課金とがあります。
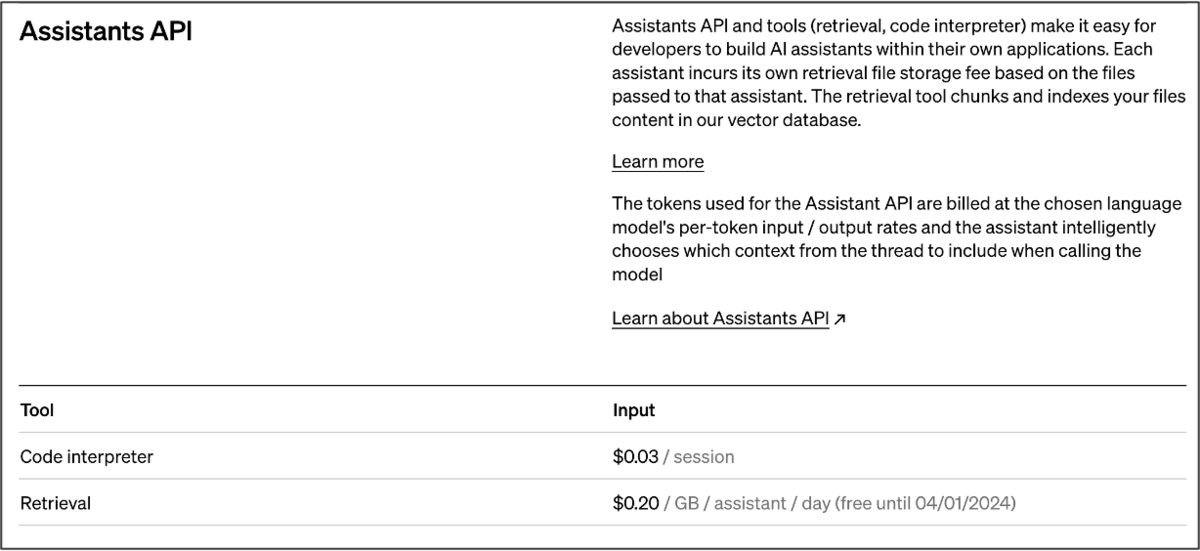
Retrievalの課金は、あくまでも保存しているファイルサイズとそれにアクセスしたアシスタントの数で決まり、Thread数などは関係ありません。 お試しでアシスタントをいくつも作成していると、いつの間にか保存しているファイルサイズが大きくなっていたということもあるので、不要なファイルはこまめに消すよう注意しましょう。
また、Thread上でアシスタントへの問い合わせをすると、過去の問い合わせの全てを含めた内容が送信される仕組み(だからこそ過去のやり取りの文脈を踏まえた回答をしてくれるわけですが)ですので、問い合わせを繰り返すたびに雪だるま式にコンテキストトークンが増えていってしまいます。そうするとトークンベースの課金が大きく膨らむことになるので、対策が必要です。
(ちなみに、Threadから過去のメッセージを削除するAPIは提供されていません。)
例えばWebアプリケーションに組み込んでいる場合などは、上限メッセージ数を定数としてシステムに持たせておき、会話のたびに過去のメッセージ一覧を取得して上限を超えていたら新しい方の一部メッセージのみを持った新たなThreadを作成し、古いThreadは削除する、というようなことをすれば回避できそうです。
まとめ
今回は、Assistants APIの基本的な使い方を見てきました。
APIで、ファイルに対する処理や、Function callingなどを実行できるようになり、できることが増えますね!
Acroquest Technologyでは、キャリア採用を行っています。少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。 www.wantedly.com
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長