こんにちは、機械学習エンジニアの駿です。
 データサイエンスチームYAMALEXの一員としても活動しています。
データサイエンスチームYAMALEXの一員としても活動しています。
最近、ビジネスシーンや日常会話でのちょっとしたフレーズを英語では何と言う?という内容で、会社でYouTuberを始めました。
Short 動画を上げているので是非ご視聴ください。
最近のおすすめはこちら。 「明日も頑張ろう!」を英語で!
さて、今回は QuickSight の機能、 1-Click 埋め込みを試してみました。
自分のサイトで QuickSight のダッシュボードを共有したいときに、ワンクリックで埋め込み用 HTML コードのコピー&ペーストが可能です。
SDK 、 API を使ったプログラム実装が不要で気楽に共有できるようになります。
Web サイトに埋め込むだけでなく、Cognito認証ありの場合の 1-Click 埋め込みの URL の挙動なども検証してみました。
 Amazon QuickSight
Amazon QuickSight
Amazon QuickSight は AWS が提供する BI ツールで、各種 AWS サービス、サードパーティクラウド、オンプレのデータに接続し可視化することができます。
以前 QuickSight の異常検出を試した記事も上げているので、興味がある方はこちらもご覧ください。
QuickSight の外部サイト埋め込み
QuickSight には作成したダッシュボードを Web サイトや Wiki に埋め込むための URL を API を利用して生成する機能があります。
API を利用した埋め込みではユーザが Web サイトにアクセスした際に、アプリケーションサーバが QuickSight の API を呼び出し、埋め込み用 URL を取得します。
Web サイトは取得した URL を埋め込むことで、ユーザに QuickSight ダッシュボードが埋め込まれたページを表示することができます。
QuickSight の 1-Click 埋め込み
1-Click 埋め込みは2022年5月に GA となった機能です。
従来の外部サイト埋め込みと違い、コーディングや開発をすることなく、 Web サイトや Wiki にダッシュボードを埋め込むことができます。
1-Click 埋め込みを活用することで、より素早くダッシュボードを共有し、ユーザにインサイトを提供することが可能になります。
それでは実際に Web サイトに 1-Click 埋め込みを使って取得した HTML コードを使ってダッシュボードを表示できるのか試してみます。
事前準備
1. QuickSight アカウント作成
QuickSight アカウントを作成します。
このとき、エンタープライズ版を選んでください。
スタンダードと比べて、料金は高くなりますが、スタンダード版には含まれない、
組み込みダッシュボードなどの機能を使うことができるようになります。
初めて利用する場合は無料枠もあります。
作成時に選びそびれてしまった/既にスタンダード版で作成したアカウントを持っている場合は、設定からエンタープライズ版に変更してください。
2. ダッシュボード作成
まず、 Web サイトに埋め込むためのダッシュボードを作成します。
今回はサンプルで用意されている分析 Web and Social Media Analytics analysis からダッシュボードを作成します。
分析を開いたら、右上の共有メニューから「ダッシュボードを公開」を選択することで、ダッシュボードを作ることができます。
「1-Click埋め込みテスト」という名前でダッシュボードを作成しました。


3. CloudFront + S3 で静的ホスティング
次にダッシュボードを埋め込むための Web サイトを作成します。 S3 に静的ファイルを配置し、 CloudFront で配信することで実現します。
(1). 静的ファイルを配置
S3 バケットを作成し、次の HTML コードを index.html としてアップロードします。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>1-Click埋め込み</title>
</head>
<body>
<h1>↓QuickSight 1-Click埋め込み↓</h1>
<!-- ここにコピーしたHTMLコードをペーストします -->
</body>
</html>
(2). CloudFront で配信
CloudFront のコンソールから「ディストリビューションを作成」を選択します。
オリジンドメインの入力を求められますが、クリックするとドロップダウンで候補が表示されるため、その中から先ほど作成したS3バケットのドメインを選択します。
そのほか、S3 バケットアクセスを Origin access control settings (recommended) に設定、ビューワープロトコルポリシーを Redirect HTTP to HTTPS に設定しました。

ブラウザで {ディストリビューションドメイン名} + "/index.html" にアクセスして下のような画面が表示されたら成功です。
まだ QuickSight のダッシュボードを埋め込んでいないため、タイトルのみが表示されています。

Webサイトにアクセスできた
4. QuickSight で CloudFront のドメインを許可
Web サイト上で QuickSight の埋め込みを表示するためには、 QuickSight 側で Web サイトのドメインを許可する必要があります。
QuickSight の埋め込みはアクセスした分課金されるため、他の人のサイトに勝手に張り付けられるなどして意図せずアクセスが増え、課金されてしまう、などの事故を防ぐことができます。
「QuickSight の管理」画面で「ドメインと埋め込み」を選択してください。
「ドメイン」に先ほど作成した CloudFront のディストリビューションのドメイン名を入力し、「追加」ボタンを押します。
下のリストに CloudFront のドメインが表示されれば成功です。

ダッシュボードの 1-Click 埋め込み
以上で事前準備が完了したので、ここからは実際に 1-Click 埋め込み機能を使って Web サイトに埋め込むための HTML コードを作成し、 Web サイトに埋め込みます。
1. URL 取得
右上の共有メニューから「ダッシュボードの共有」を選択します。
共有画面の上部に「埋め込みコードをコピー」というリンクがあります。
これをクリックすると自動でクリップボードに、埋め込むための HTML コードがコピーされます。
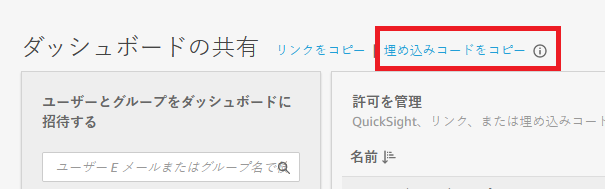
埋め込みコードをコピー
2. HTML に張り付け
先ほど作成した index.html の <!-- ここにコピーしたHTMLコードをペーストします --> 部分にペーストしてください。
<iframe width="960" height="720" src="https://us-west-2.quicksight.aws.amazon.com/sn/embed/share/..."> </iframe>
貼り付けられたら保存して、 index.html を S3 にアップロードしましょう。
3. 表示
あとは CloudFront の URL にアクセスするだけです。
初回表示時は QuickSight へのログインが必要です。
ポップアップが表示されるので、QuickSight アカウントでログインしてください。
(ブラウザの設定によってはポップアップがブロックされている可能性があります。)
次回以降はログインされた状態が保持されます。
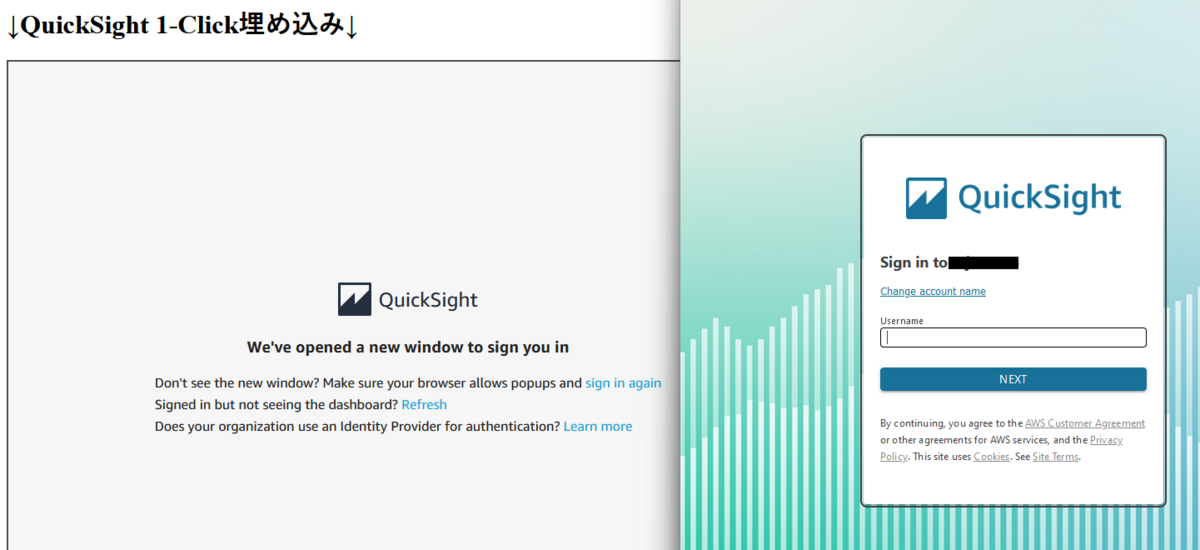
ログインを求められる
作成したダッシュボードを簡単に Web サイトに埋め込むことができました。
埋め込み完了
動作を確認してみる
1. 公開のダッシュボードを共有してみる
公開ダッシュボードを共有することで、ログイン不要でインターネット上の全ユーザがダッシュボードを埋め込んだ Web サイト上で分析を閲覧することができます。
なお、公開ダッシュボード機能は $250/月(2022/09/03 現在)かかるセッションキャパシティーを使用するため、試す際は費用にお気を付けください。
まず、非公開のダッシュボードではログインが必要なことを再度確認するため、プライベートブラウザで CloudFront のページにアクセスします。
(普通のブラウザでは先ほどすでにログインしているため、そのまま開けてしまうため、プライベートブラウザを使います。)
上と同じ、初回表示時のログインを促されました。いったん、ログインはせずにそのまま置いておきます。
それでは、公式のドキュメント に従って、インターネット上の全員にダッシュボードへのアクセスを許可します。

公開ダッシュボードに設定しても 1-Click 埋め込みの URL は変わりません。
先ほどログインを求められていたプライベートブラウザをリロードしてみると、今度はログインを求められずに表示することができました。
(キャプチャは先ほどログインして表示したダッシュボードと変わらないため、割愛します。)
2. ドメインを許可していないサイトで表示してみる
ドメインを許可していないサイトで表示しようとしても、表示できないことを確認します。
事前準備4. で許可したドメインの右にあるごみ箱マークを押して、ドメインの許可を削除します。


ドメインを削除した状態で Web サイトを開くと このページは開けません とエラーページが表示されました。
確かにドメインを許可した Web サイトでないとダッシュボードを表示できないことを確認できました。

3. Cognito でログインした状態で表示してみる
最後に Cognito ユーザとしてログインしたサイト上に埋め込まれたダッシュボードは、追加でログインする必要があるのかどうかを検証します。
検証用に作成した Amplify でログイン機能を付けたサイトに、今まで通り 1-Click 埋め込みの URL を貼り付けて、公開しました。
Cognito ユーザでログインすると QuickSight の認証はどうなるのか確認してみます。
Cognito ユーザでログインする

ログインのポップアップが表示される
Cognito ユーザとしてログインしていても、 QuickSight ユーザとしてログインを求められることが分かりました。
1-Click 埋め込みで取得した URL には認証情報が入っていないため、当然ともいえるかもしれません。
もちろん、 QuickSight ユーザでログインすればダッシュボードを表示することができます。
ログインすれば表示できる
1-Click 埋め込みと API を利用した埋め込みの違い
有効期限
API を利用した埋め込みでは URL に5分間の有効期限があります。
そのため Web サイトにアクセスするたびに API を呼び出してURLを取得し、 Web サイトにその URL をプログラム的に埋め込む必要があります。その反面、 1-Click 埋め込みの URL は分析者が無効にするまで利用することができます。
一度取得した URL を静的に HTML に埋め込むだけでいいので、 Web サイトの開発コストが少ないのが利点です。認証方法
1-Click 埋め込みの URL はユーザ固有のものではなく、同一の URL にアクセスすると、 QuickSight による認証にリダイレクトされる仕組みになっています。
Web サイトのログインと QuickSight のログインが別で必要になってしまいますが、 QuickSight のログイン情報は次回以降も保持されるため、一度ログインしてしまえば再度ログインする必要はありません。API を利用した埋め込みでは特定のユーザ用の URL を生成する方法とユーザ認証のない URL を生成する方法があります。
ユーザ固有の URL を生成する場合も、 Web サイトへのログイン情報をもとに URL を生成できるため、 QuickSight による認証は必要ありません。
まとめると下のようになります。
それぞれに向き不向きがあるため、ユースケースに合ったやり方を選択する必要があります。
| 方式 | 有効期限 | 認証方法 |
|---|---|---|
| 1-Click 埋め込み | なし | QuickSight による認証 |
| API を利用した埋め込み | 5分間 | 特定ユーザの認証情報を含んだ URL /ユーザ認証のない URL |
まとめ
今回は開発不要で Web サイトに QuickSight のダッシュボードを簡単に埋め込むことができる、 1-Click 埋め込みを使ってみました。
QuickSight の API を学習する必要がなく、画面をクリックしていくだけで実現できました。
あまりに簡単だったので、ほんとにこれでいいの?と思ってしまいました。
それでは、
Let's keep up the good work tomorrow!
Acroquest Technologyでは、キャリア採用を行っています。少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。 www.wantedly.com
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長