こんにちは、エンジニアの駿です。

最近AcroではWordleが流行っており、親の仕事の都合で中学3年間をアメリカで過ごし英語が得意を売りにしている身としては2回くらいで当てたいと思っているところ。
ですが、なかなかうまくいきません。。。
普段、サーバーレスでの開発をしており、私自身は、QuickSightの利用はまだ経験が浅いのですが、BIで異常検知もできる、ということで、どのようなことができるのか、試してみました。
 Amazon QuickSightとは
Amazon QuickSightとは
Amazon QuickSight はAWSが提供する可視化用のツールで、 各種AWSサービス、サードパーティクラウド、オンプレのデータに接続し可視化できるだけでなく、 機械学習の統合、Qを用いた自然言語の質問を使ったクエリなど、必要な情報を簡単に手に入れることができます。
QuickSightの機械学習機能、ML Insightsには3つの主要機能があります。
異常検出
機械学習を用いて、時系列データを分析し、異常を検出します。
また、異常につながった主な要因の特定、Eメールでのアラートなどを行うことができます。予測
機械学習を用いて、時系列データの予測を行います。
追加の設定不要で、季節性や欠損値など複雑なシナリオにも自動で対応します。自動説明文生成
最大/最小をはじめとするデータの内容を、自動でわかりやすい説明文として表示することができます。
必要な情報を得るためにチャートや表を調べる必要がなくなり、また、組織内でデータの理解を共有することができます。
下の画像は公式のQuickSight紹介ページに載っているIoTデバイスの情報を可視化したデモダッシュボードです。
可視化するだけでも必要な情報を一目で見られるようにできて、さらにML Insightsを使うことで異常検出と予測の情報を付け加えることができる、と考えると、非常に強力なツールになりそうです。

異常検出してみる
今回は、周期性のある時系列データと複数の要素を含む時系列データを使って、QuickSightの異常検出を実際に試してみます。


周期性のある時系列データ
QuickSightのML Insightsを使って異常検出をするためには大きく3つのステップが必要です。 (1) QuickSightにサインアップする、 (2) データをアップロードする、そして最後に (3) ビジュアル/インサイトを追加します。
まずは周期性のある時系列データで各ステップを説明します。
(1) QuickSightにサインアップする
AWS ConsoleからQuickSightを初めて開くとき、サインアップを求められます。 ダイアログに従ってサインアップを行ってください。
なお、Editionを選択するダイアログでは、「Enterprise」を選択してください。 「Standard」を選択してしまうと、ML Insightsの機能が利用できません。
(2) データをアップロードする
QuickSightコンソール右上の「新しい分析」>「新しいデータセット」の順にクリックして、データをアップロードします。
今回は single-anomalydata.csv という名前のファイルを用意しました。 中身は下記の様にセンサーID、日時、値が約10分起きに記録されたシンプルな物になっています。
| id | timestamp | value |
|---|---|---|
| sensor01 | 2018-11-28 00:00:00 | 151.87 |
| sensor01 | 2018-11-28 00:09:56 | 157.66 |
「ファイルのアップロード」をクリックし、ファイル選択ダイアログで single-anomalydata.csv を選択すると、プレビューが表示されるので、「次へ」をクリックしデータセット作成を完了します。
「設定の編集とデータの準備」を使うと、別のCSVとの結合やフィルタ、列の削除などが行えます。 今回は編集せずにそのまま扱います。

(3) ビジュアル/インサイトを追加
ファイルをアップロードし、データセットを作成した後は、ビジュアルを追加して可視化を行います。
左上の「+追加」>「ビジュアルを追加」を選択し、可視化する要素として「timestamp」と「value」を選択します。
この時、それぞれの要素をクリックするだけで、QuickSightが自動でtimestampをx軸、valueをy軸に設定してくれます。
デフォルトだとtimestampの集計間隔は「日」になっていますが、今回は10分間隔のデータを扱うため、集計間隔を「分」に変更します。
また、y軸の値の集計方法は「合計」「平均」「最大/最小」などから選択することができます。
データに応じて適した集計方法を選択してください。
可視化した結果を図に示します。
今回用意したデータには2018/12/19 7:30前後に異常なデータがあることが分かりました。
次にインサイトの異常検出を使って、この異常を検出できるか試してみます。

今度は「インサイトを追加」を選択し、表示されるプルダウンから「異常値検出(ML駆動型インサイト)」を選択します。
続いてビジュアルと同様に「timestamp」と「value」を選択します。
集計間隔と集計方法もビジュアルと同じ設定を行います。
「今すぐ始める」ボタンが現れるため、それをクリックし、異常検出の設定を行います。
「異常検出をセットアップ」画面で異常検出の設定を行うことができます。
今回はすべてデフォルトのままでよいので、右上の「保存」を選択します。
次に「今すぐ実行」ボタンが表示されるので、クリックします。
「異常値の分析中…」と表示されたら、解析が終わるのを待ちます。
5分ほど待つと異常検出の結果が表示されます。
2018/12/19 05:03に異常が見つかったようです。
「異常の探索」を選択し、詳細を見てみます。
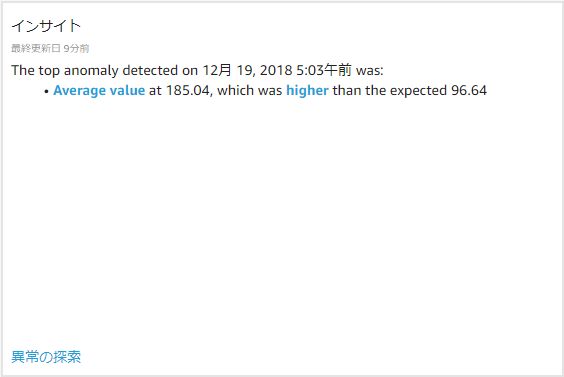
ビジュアルを作成して、目視で確認できた7:30前後の異常が確かに検出できていました。
普段であれば、正常データを機械学習モデルに学習させて、そのモデルを使って異常検出をしていたところ、QuickSightのML Insightsを使えば画面をポチポチするだけでカンタンにできてしまいました。

複数の要素がある時系列データ
次に要素の多いデータでもML Insightsを試してみました。
先ほどのデータセットでは値を1つしか使いませんでしたが、今度は、気温、湿度など5つの要素を持つデータを準備しました。
こちらのKaggleのデータセットを元にしています。
表の様に5つの要素を縦持ちにしたセンサーデータです。
また、値は各要素毎に値が0-1の範囲に収まるように正規化してあります。
| Time | SensorType | Value |
|---|---|---|
| 2021-06-15 18:21:46 | Temperature | 0.314 |
| 2021-06-15 18:21:46 | Humidity | 0.386 |
| 2021-06-15 18:21:46 | Air Quality | 0.0 |
| 2021-06-15 18:21:46 | Light | 0.380 |
| 2021-06-15 18:21:46 | Loudness | 0.161 |
Time列がUnix時間となっており、このままだとQuickSightが日時と認識してくれないため、「設定の編集とデータの準備」で計算フィールドを追加し、Unix時間から日時文字列への変換を行いました(epochDate({Time}))。
可視化した結果がこちらです。

また、時間にTime、値にValue、カテゴリにSensorTypeを設定して異常検出を実施したところ、下記のように各要素で異常が発生した箇所を見つけることができました。 線が紺色になっている部分が、異常が検出された部分です。また、異常の開始時刻は紺色の点で示されています。



下の様に、各要素で異常が発生した日時をまとめて確認することもできるため、同時期に他にどのような異常が発生しているのかを一度に確認することができます。

ただし、上記の様に各要素毎に異常がある部分を検出することはできましたが、要素間の異常検出は現状できないようです。
例えば可視化した図を見ると、TemperatureとLightに相関があり、TemperatureとHumidityに負の相関があることが分かりますが、
この相関が崩れた時に異常と判定する、といったことはできません。
あくまで一度に異常を検出できる時系列データはひとつだけの様です。

同様に、Temperatureに異常があったときに、どの要素がその異常に最も寄与しているかを産出させることもできません。
QuickSightの異常検出には「上位の寄与要因」といって、異常の背後にある主要な要因を見つける機能があるのですが(「異常検出をセットアップ」で設定可能)、
この機能はカテゴリデータのみに対応しており、時系列データは扱えません。
この寄与要因はチュートリアルやサンプルを見る限り、「会社の売り上げが大きく下がったときに、どの地域の売り上げがよくなかったのか、どの分野の売り上げがよくなかったのか」といった要因を調べるための物の様でした。
このような相関分析ができるようになると、活用の幅がさらに広がりそうです。
料金
ML Insightsを用いるには、評価されたメトリクス数に応じて料金がかかります。
| 評価されたメトリクス | 料金/1,000 評価されたメトリクス |
|---|---|
| 1~1,000,000 | $0.5 |
| 1,000,001~10,000,000 | $0.25 |
| 10,000,001~100,000,000 | $0.1 |
| >100,000,000 | $0.05 |
評価されたメトリクス数は、メトリック数x評価回数を元に計算されます。 評価方法などはQuickSight料金計算ツールの例を参考にしてください。
If you set up one alert to run hourly, that would bill as 24 metrics per day (or 720 metrics per month).
If you set up an Anomaly Detection job to watch “sales”, and then added break-downs by region (four regions) and product category (let’s assume 10 categories),
that could be up to 55 metrics (1 sales + 4 regions + 10 categories + 4*10 region-categories, depending on if you choose to run it for all combinations of the data).
If you ran that anomaly job daily, you’d expect to run 1.65 per thousand metrics (55 * 30 = 1,650) per month.
それ以外に、ユーザーごとの料金として、Enterprise Edition だと、Authorユーザー(ダッシュボードの作成者)で$24/月、Readerユーザー(ダッシュボードの閲覧者)で最大$5/月の料金がかかります。
今回は評価されたメトリクスが1,000に満たないため、Authorユーザの料金と合わせて、$24.5ほどでQuickSightとML Insightsを利用することができました。
上の例のように55のメトリクスを一日一回異常検出に使用したとすると、ひと月に異常検出にかかる料金は$1弱になる計算なので、非常に安く利用できると思います。
注意点
形式
いくつか、ML Insightsの異常検出を利用するにあたって注意が必要な箇所がありました。
解析されるデータは時系列データである必要がある。
時折、時系列データでも日時ではなく、インデックスが振ってある物がありますが、 インデックスが日時カラムと認識されないため、QuickSightが時系列データとして扱ってくれません。
また、日時カラムが文字列ではなくUnix時間になっている場合は、上で紹介したように、データ読み込み時に変換する必要があります。横持ちより縦持ちの方が扱いやすい。
カラムに各要素の値を持つ横持ちのデータも、要素毎に行が分かれている縦持ちに変換することで、カラム名をカテゴリとして活用できるようになります。
横持ちのデータも分析はできますが、複数の要素がある時系列データで示したようにまとめて異常検出をすることや、 ML Insightsの機能の一つである、「上位の寄与要因」の分析ができない、といったデメリットがあります。
縦持ちデータの例
日時 センサ種類 値 2021-06-15 18:21:46 温度 20.5 2021-06-15 18:21:46 湿度 30.5 2021-06-16 18:21:46 温度 21.5 2021-06-16 18:21:46 湿度 28.5 横持データの例
日時 温度 湿度 2021-06-15 18:21:46 20.5 30.5 2021-06-16 18:21:46 21.5 28.5
データ量
異常検出を実行する前に要件を確認してください。
- 少なくとも1つの日付ディメンションが必要
- 異常検出のトレーニングに最低15のデータポイントが必要
などの要件があります。
まとめ
今回はAmazon QuickSightのML Insightsを使って異常検出をしてみました。
低コストで簡単に異常検出を行うことができ、びっくりしました。
1つ目に紹介した、周期性のある時系列データを用いた内容を実施するのに30分ほどしかかかりませんでした。
これだけ簡単にできるのは、学習データの準備など煩わしいことをしなくても、 ML Insightsが教師なし学習をしてくれるからで、専門知識がない人でも適用できると思われました。
また、現状、相関分析まではできないようですが、複数の系列データを一度に分析できるのも、実用的だと感じました。
是非皆さんも一度試してみてください。
Acroquest Technologyでは、キャリア採用を行っています。少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。 www.wantedly.com
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長