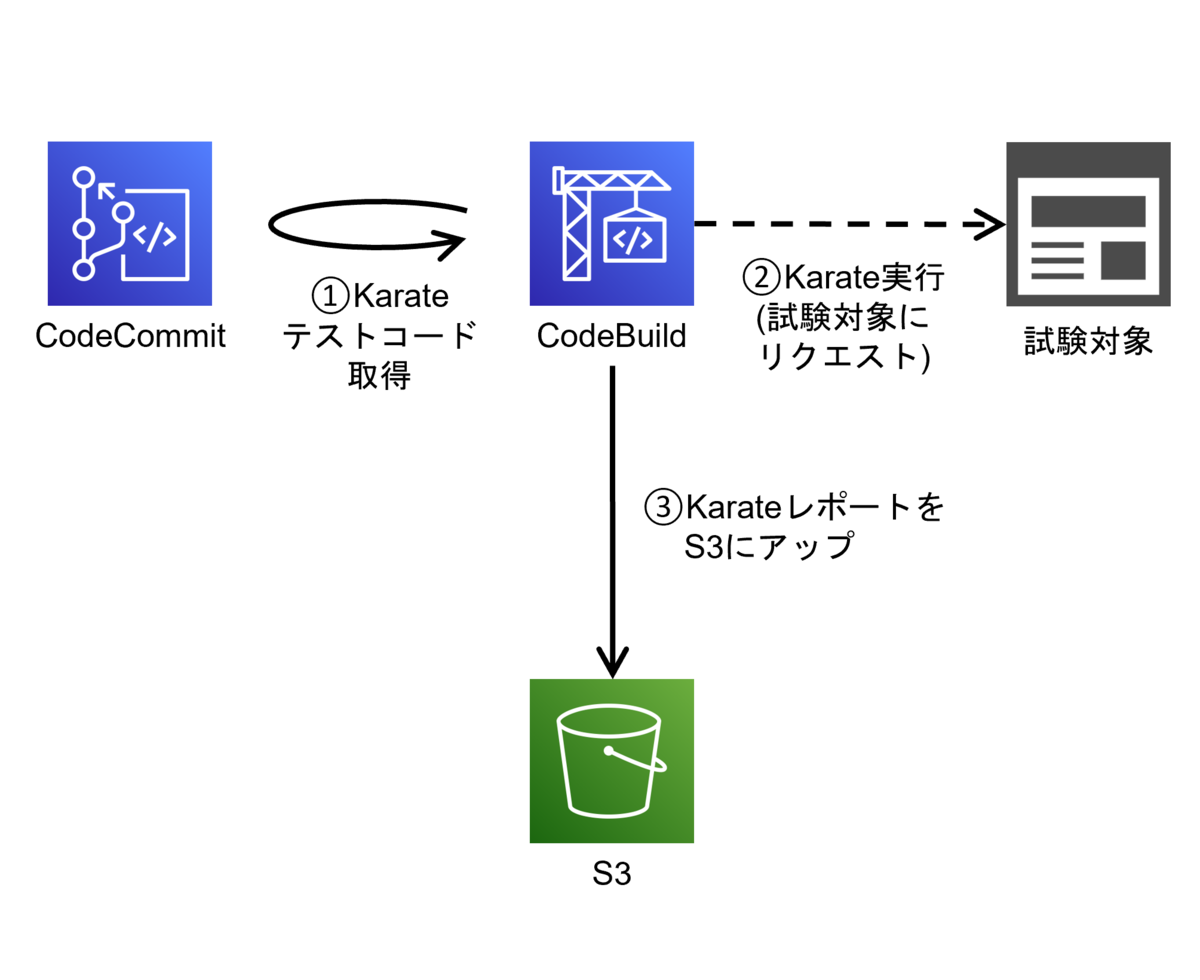
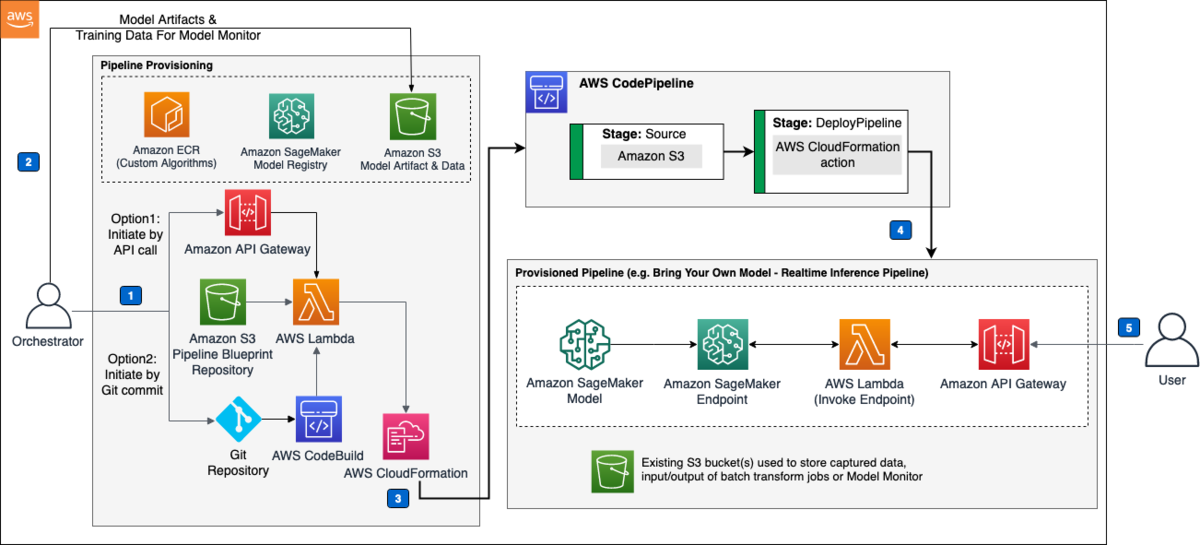
AWSで構築するデータレイクがテーマの本連載、今回は第3回目、最終回です。 前回は、AWS Lake Formationで構築したデータレイクとAmazon Athenaの連携を確認しました。今回は、Lake Formationの権限管理で、Athenaからのクエリにアクセスコントロールをかける部分を試していきます。
データレイクにはとにかくどんなデータも格納される、ということは誰がどのデータにアクセスできるか管理する必要がでてきます。 Lake Formationを使うと、データレイクにおけるアクセスコントロールを、要件に合わせ細かく設定することができます。
実際に権限管理を試してみると、確かに細かく権限管理できることが実感できました。他方、Lake Formationにおける権限管理の考え方が複雑なため、自分にとっては難しい部分もありました。 本記事では、実際に試してわかった、権限管理の具体的な設定方法、および権限管理の考え方をまとめてみたいと思います。
- 第1回:AWS Lake Formationでデータレイク体験! #1 何がうれしいのか?
- 第2回:AWS Lake Formationでデータレイク体験! #2 Athenaで簡単データ連携
- 第3回:AWS Lake Formationでデータレイク体験! #3 きめ細かな権限管理 (本記事)

1. Lake Formationの権限管理
最初に、Lake Formationで、どのような権限管理ができるのか、簡単に見ていきます。
第1回の記事で書いたように、データレイクでは、事業・業務横断的にデータを管理するケースがあるかと思います。 データの中には、個人情報、業務上の秘匿情報など、自由にアクセスされたくないデータも混在していることも考えられます。 そのようなデータは、漏洩した際のリスクがあり、データレイク利用者すべてにアクセスを許可するのは非常にリスクが高くなります。
AWS Lake Formationは、データレイクに柔軟にきめ細かな「権限管理」を付与できることが特徴の一つです。
AWS Lake Formationは、
- データベース、テーブルレベルのアクセス管理
- 列、行、または行・列組み合わせによるセルレベルのアクセス管理
を提供しています。
例を通して、整理してみたいと思います。
「顧客マスタテーブル」と「販売実績テーブル」が存在し、セールスとアナリストがいる事業所を仮定します。
アナリストに、個々の顧客個人情報を見せないように、テーブルからデータを参照すること自体を禁止します。
また、販売時にサードパーティーの決済システムを利用していたとして、決済時に発行されるIDも必要ないでしょう。不要な列は、列レベルで参照を禁止します。
セールスには、担当地域の顧客情報は参照できても、それ以外の個人情報は参照させたくない。とすれば、担当販売地域のデータにのみアクセス可能にできます。
上記ケースのアクセスコントロール例を図示してみます。

本記事では、テーブルレベルのアクセスコントロール、および列レベルのアクセスコントロールまでを扱っていきます。
2. 構築時のポイント
具体的な設定方法に移る前に、権限管理する際のポイントをまとめてみたいと思います。
ポイントは(1) IAM権限範囲、(2) ペルソナ、(3) 権限管理方式の3つあります。 それぞれ簡単に見ていきます。
(1) IAM権限範囲
Lake Formationは、データソースへのアクセスコントロールを行います。同様に、IAMもアクセスコントロールを実現するために利用されます。 したがって、それぞれ権限を細かく設定するか、粗く設定するか、組み合わせを考慮することが必要になります。
基本シナリオは、以下の2通りです。
| 方法 | Lake Formation | IAM |
|---|---|---|
| 方法1(デフォルト) | アクセスコントロールしない | きめ細かにアクセスコントロールする |
| 方法2(推奨) | きめ細かにアクセスコントロールする | 粗くアクセスコントロールする |
このうち、AWSの推奨は「方法2」になります。 「方法1」は、IAM、S3バケットポリシーなど、複数のサービスにまたがり、複雑に権限管理する必要があります。その上、リソースの変更、追加時、全設定を見直す必要が出てきてしまいます。
ゆえに、「方法2」が推奨されています。しかし、Lake Formationのデフォルト設定は「方法1」になっています。
これは、AWS Glue データカタログの既存動作との互換性を保つためのようです。
したがって、Lake Formationの設定で、「方法2」に切り替える必要があります。
具体的な切り替え方法は後述します。
ここでの話は、以下のドキュメントにより詳細が書かれています。 docs.aws.amazon.com
(2) ペルソナ
どの属性のユーザに何のIAMポリシーを付与するか、その類型のことを、AWS Lake Formation ペルソナと呼びます。
例えば、データレイクの管理者や、データアナリスト、などです。 それぞれに、どの程度の権限を付与するか事前に設計することが重要になります。
以下、AWSが提案しているペルソナの例です。 docs.aws.amazon.com
(3) 権限管理方式
Lake Formationは2つの権限管理方式を提供しています。
名前付きリソースアクセスコントロールは、「ユーザAは、テーブルXにアクセス可能である」のように、ユーザごとに設定する権限管理方式です。
TBACは、「開発者タグを持つユーザは、テーブルXにアクセス可能である」のように、タグ付けによる権限管理方式です。
推奨されているのは、TBACです。理由は2つあります。
つまり、「ユーザの数 + 管理対象データソース数」のみ管理するだけになります。
他方、名前付きリソースアクセスコントロールでは、「ユーザの数 x 管理対象データソース数」となります。
TBACに関するドキュメントは、以下になります。 docs.aws.amazon.com
3. 権限管理してみる
ここまで、権限管理に関する考え方を見てきました。ここからは、実際にLake Formationで権限管理していきたいと思います。
まず、権限付与されていない状態でのクエリ実行を試します。権限管理されていない状態では、どのテーブルにもアクセスできない状態となります。
次に、テーブルレベルのアクセスコントロールをかけていきます。この時、許可されたテーブルからデータを取得できるようになります。
最後に、列レベルのアクセスコントロールを試していきたいと思います。許可された列のみ参照できるようにしていきます。
権限付与されていない場合
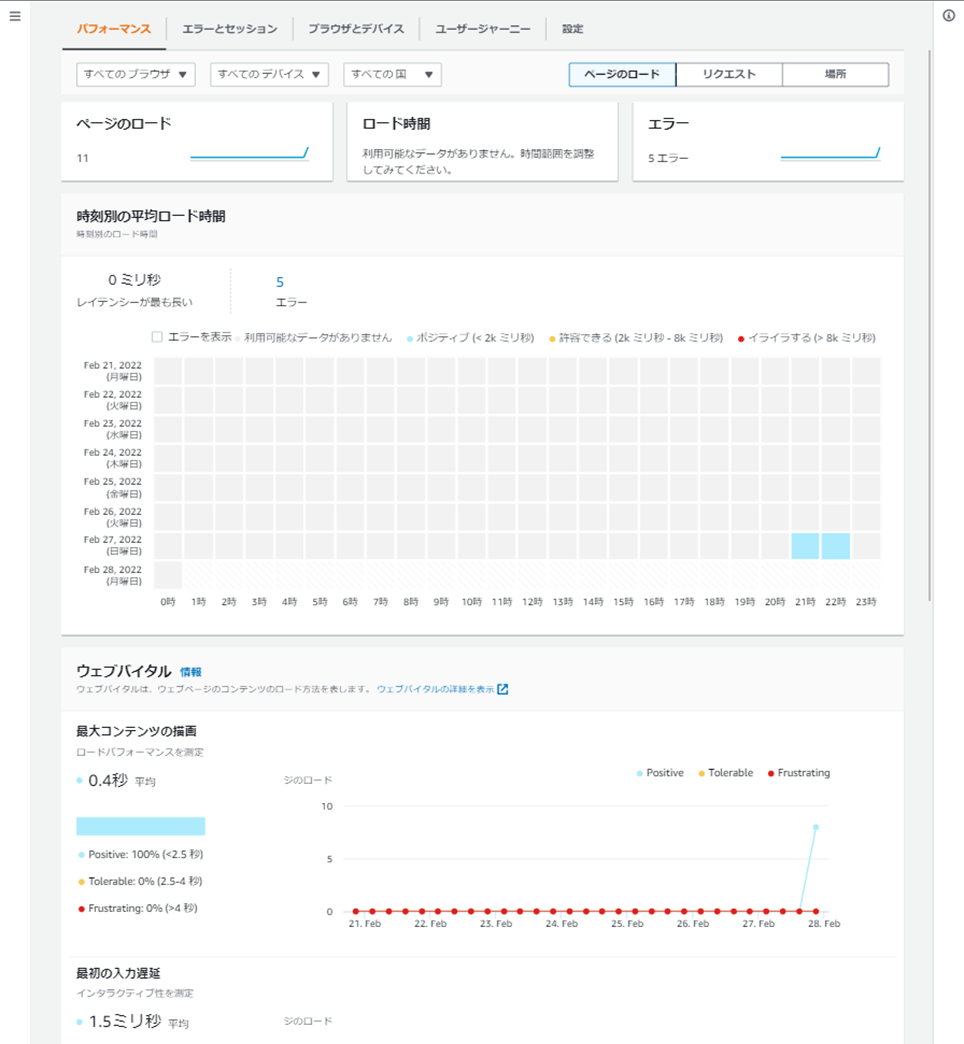
1回目の記事で作成した「データアナリスト」のIAMユーザでログインします。 Athenaコンソールを開き、salesテーブルからデータ取得するクエリを発行してみます。
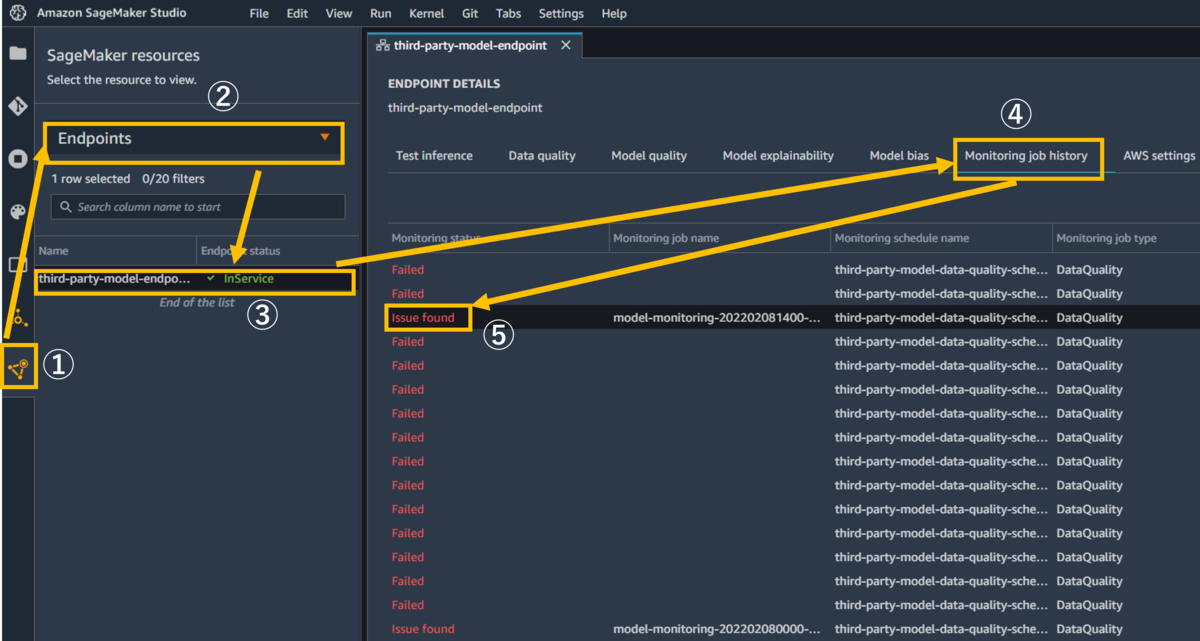
以下に添付するキャプチャは、クエリ発行の結果です。 ここから、①テーブルの候補が出てこないこと、②SELECT文の結果データを取得できていないことがわかります。

まずは、権限付与されていなければ、アクセスできないことがわかりました。
権限管理用のタグ作成 (LF-Tag作成)
「LF-Tag」とは、Lake Formationのタグベース権限管理で利用するタグのことです。 このタグをテーブルや列に付与することで、同じタグを持つユーザのみアクセスできる、といった具合にアクセスコントロールを実現することができます。
タグベースでの権限管理方式については、権限管理方式で触れました。本記事では、LF-Tagを利用して、権限管理していきます。
以下、roleというキーに対し、「leader」と「analyst」という2つの値をもつLF-Tagを作成していきます。

「Add LF-Tag」を押下します。

「key」と「value」に値を入れ、「Add LF-Tag」を押下します。

LF-Tag作成後、一覧に作成したタグが表示されます。

続いて、「データアナリスト」のIAMユーザに、「role=analyst」のタグを付与します。
「Permissions」 > 「Data lake permissions」 > 「Grant」を選択し、権限付与画面に移動して以下のように設定します。

テーブルレベルのアクセスコントロール
続いて、許可されたテーブルにのみアクセスできることを確認していきます。 まず、「データレイク管理者」のIAMユーザで、Lake Formationコンソールを開きます。
データベースへのアクセス権限付与
少なくともデータベースに対してDESCRIBEを実行できなければ、テーブルの一覧も取得できません。したがって最初に、データベース自体へのアクセス権限を付与します。
「Permissions」 > 「Data lake permissions」 > 「Grant」を選択し、権限付与画面に移動して以下のように設定します。

この段階で、データアナリストはAthenaからデータベースを参照できるようになり、テーブルは参照できない状態になります。

テーブルにLF-Tagを付与
次に、roleがanalystのユーザに許可するテーブルを設定します。 「Data catalog」>「Table」から、アクセス許可するテーブルを選択し、「Actions」>「Edit LF-tags」からLF-tags編集画面に移動します。

「role」タグの値を「analyst」に設定します。

Athenaから権限設定結果を確認
タグの設定が完了すると、データアナリストはAthenaからsalesテーブルを参照できるようになります。SELECT文を実行した結果が以下です。

列レベルのアクセスコントロール
ここまで、テーブルレベルでアクセスコントロールできることは確認できました。 次に、より細かなコントロールの例として、例レベルのアクセスコントロールをかけていきたいと思います。
テーブルレベルのアクセスコントロールと同様に、LF-Tagを使って、列レベルのアクセスコントロールを設定していきます。
テーブルの権限を「leader」に変更。

「Tables」 > 「テーブル名」 > 「Edit schema」を選択します。

アクセス許可する列に「analyst」のタグを付与
analystが参照可能とする列を選択し、「Edit tags」を選択します。

roleをanalystに変更し、「Save」します。

Athenaから権限設定結果を確認
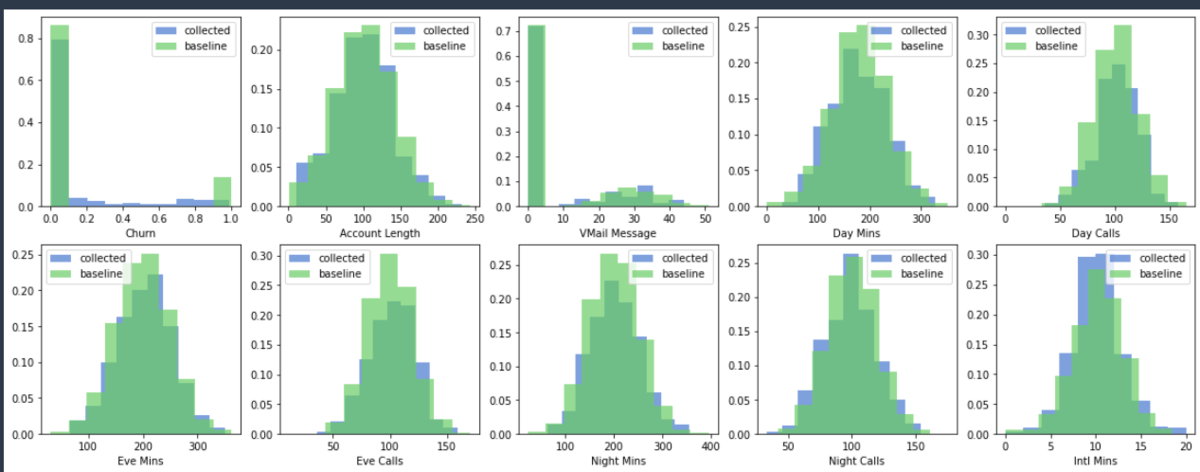
列単位での設定は以上になります。データアナリストIAMユーザでログインし、Athenaコンソールを開くと、指定した列のみが参照できるようになっています。 SELECT文でも、許可された列のみが参照できるようになっています。

5. 最後に
AWS Lake Formationを試してみて、LF-Tagを使った設定はかなり簡単で、柔軟に設定できるなと感じました。
ただ、気を付けておきたい点として、権限を付与、制限する要素それぞれの、「役割・作用」の理解が重要なのだと思いました。
データレイクにおいて、過剰なアクセスコントロールは使い勝手を著しく損ない、「データスワンプ」になってしまうと言われています。 過剰な権限管理を避けながらも、スケーラブルかつ、安全にアクセスコントロールを設計するのは、エンジニアとしての力量が試されるな、と感じます。
ここまで全三回に渡りLake Formationを使ったデータレイク構築を試してみた感想として、 Lake Formationは難しい部分はあれど、Lake Formationなしで同じことはしたくない、と感じました。
ユーザごとの権限管理にせよ、テーブル・列レベルのアクセスコントロールにせよ、Lake Formationなしで構築することは技術的には可能と思います。 しかし、Lake Formationを使う方が簡単にかつ一元的に管理できるのは間違いなく、 Lake Formationの謳い文句である、「安全なデータレイクを数日で簡単にセットアップできる」も、その通りだった、と感じました。
本連載では、Lake Formationの基本的な使い方と、権限管理に注目してきましたが、AWS Lake Formationには魅力的な機能がまだまだ備わっています。 例えば、行、セルレベルの権限管理、Governed Tableが提供するACID トランザクションのサポートなどです。
今後、AWS Lake Formationの他の機能も試していければと思います。
Acroquest Technologyでは、キャリア採用を行っています。少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。 www.wantedly.com
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長