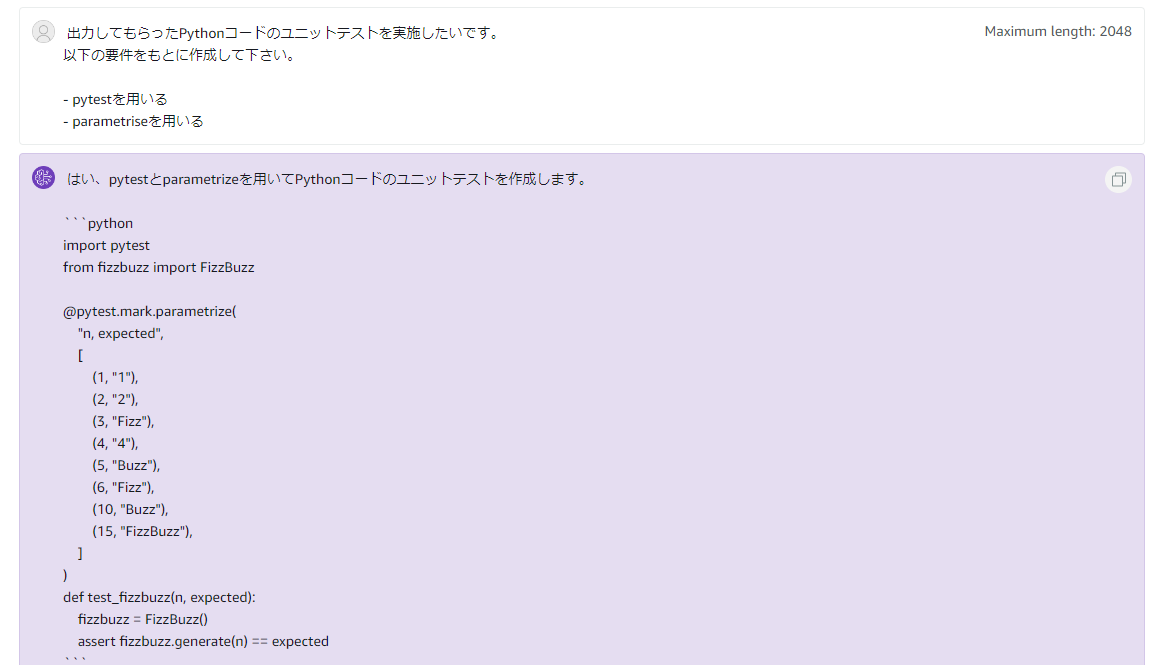
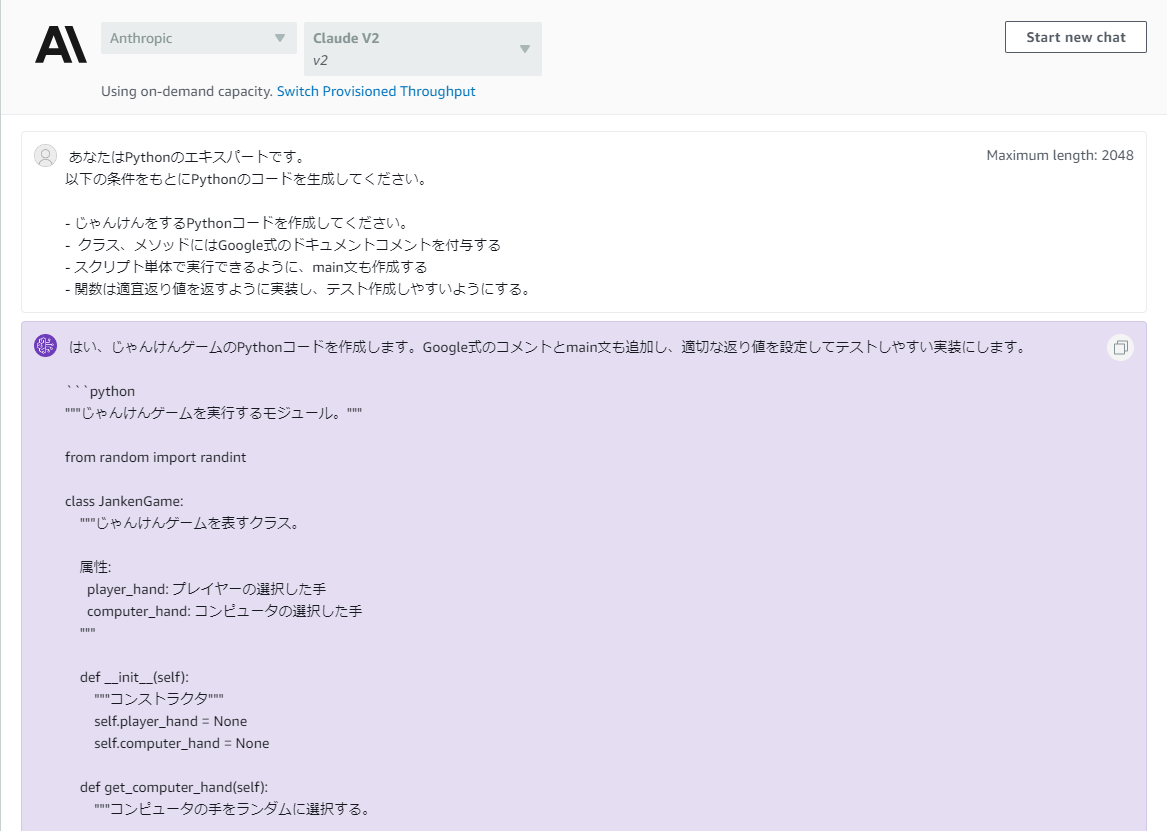
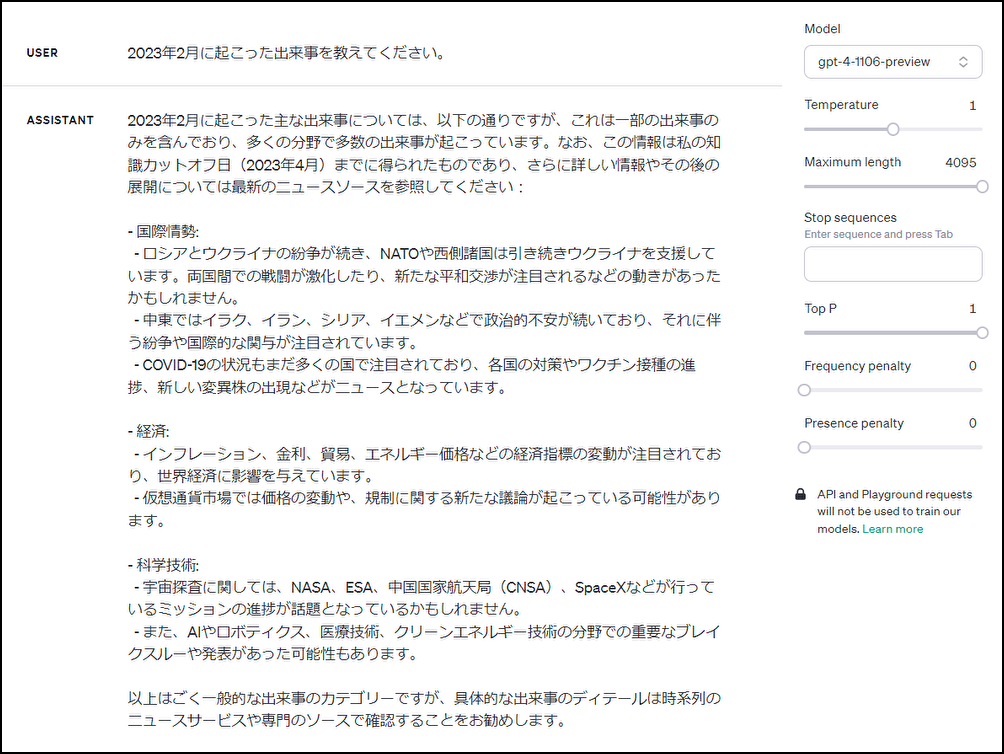
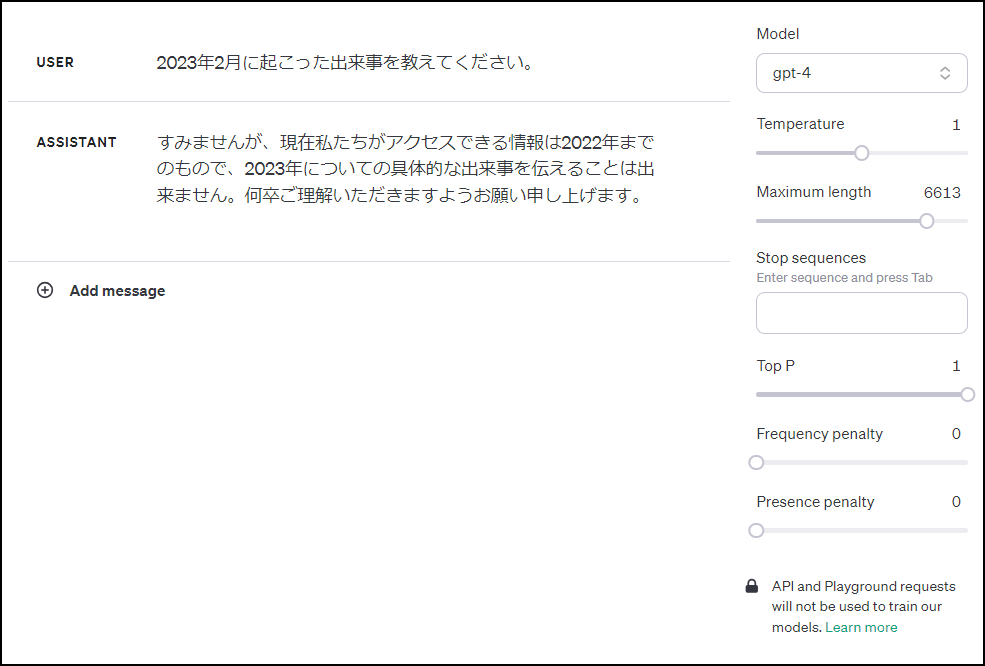
皆さんこんにちは。データサイエンティストチームYAMALEXのSsk1029Takashiです。
YAMALEXは Acroquest 社内で発足した、会社の未来の技術を創る、機械学習がメインテーマのデータサイエンスチームです。
Acroquestでは検索とAzure OpenAI Serviceを組み合わせたQAシステムを提供中です。
こういったシステムを運用していく中で課題になるのが精度評価と改善の仕組みです。
今年7月の記事でPrompt Flowを使った回答評価を検証してみましたが、今回はOSSのragasというツールを使って検証してみます。
ragasとは
ragasはRAG(Retrieval Augumented Generation)の仕組みの良し悪しを評価するためにOSSで作成されたライブラリです。
以下のリポジトリがあり、Pythonのライブラリとして使用することができます。
github.com
RAGを運用しているとよくあるのは、システムが誤答を出した場合に何が問題なのか切り分けるポイントが多く手間がかかることです。
誤答を出したとしても、検索結果のコンテキストが悪いのかプロンプトが悪いのかでとるべき対策が変わってきます。
一つの回答について調査するだけならログを見ればわかりますが、システムとして評価するときには全体の傾向を見る必要があります。
そこでragasはLLMを使用したRAGの評価に特化しているため、質問・参照元のコンテキスト・回答をもとにいくつかの指標に分けて回答品質を評価できます。
ragasで使える評価指標

ragasでは標準で以下の4つの評価指標が用意されています。
| 名前 | 説明 |
| Faithfulness | コンテキストと回答の一貫性を評価する指標です。 回答の中にコンテキストから推測できない情報が含まれているほどスコアが下がります。 |
| Context Precision | 質問とコンテキストの関連度をスコアにします。 コンテキストの中に質問に関係ない情報が含まれているほどスコアが下がります。 |
| Context Recall | 検索結果のコンテキストが期待する回答に対してどれくらいの情報をカバーできるかをスコアにします。 この指標を測る場合には、質問に対して期待する回答を事前に定義する必要があります。 |
| Answer Relevancy | 質問と回答の関連度をスコアにします。 質問に対して関係ないことが回答に含まれているほどスコアが下がります。 |
使ってみる
今回は以下の記事で使用した例を使ってragasによる評価を試してみましょう。
acro-engineer.hatenablog.com

動作させるのは非常に簡単で、datasetを作成→evaluateで評価を実行するだけです。
注意点としてragasはOpenAIのAPIを使用するため、事前に取得して、OPENAI_API_KEYという環境変数に設定して置く必要があります。
datasetを作成する
from datasets import Dataset questions = [ "Azure OpenAI Service上で利用できるGPT-4の最新版のモデルはバージョンは?", "Azure OpenAI Service上で利用できるGPT-4の最新版のモデルはバージョンは?", "text-embedding-ada-002モデルの次元数は?" ] contexts = [ ["Azure OpenAI Serviceで利用できるGPT-4のバージョンは0301, 0631があり、自動でアップデートする設定が使用可能です。"], ["Azure OpenAI Serviceで利用できるGPT-4のバージョンは0301, 0631があり、自動でアップデートする設定が使用可能です。"], ["text-embedding-ada-002はOpenAIから利用できる文章をベクトル化できるモデルで,1536次元のモデルを出力することが可能です。"] ] answers = [ "最新版のモデルのバージョンは0613です", "モデルは自動でアップデートする設定が使用可能です", "1536です" ] dataset = Dataset.from_dict( { "question": questions, "answer": answers, "contexts": contexts, } )
評価を実行する
評価を実行するにはスコアを出す評価指標を指定して実行するだけです。
評価指標は指定しない場合はFaithfulness、Context Precision、Context Recall、Answer Relevancyの4つが実行されます。
※ただし、今回の検証ではContext Recallに必要な期待する回答はない想定なので、Context Recall以外の3つを指定します。
from ragas import evaluate from ragas.metrics import answer_relevancy, context_precision, faithfulness # 評価 result = evaluate(dataset, [answer_relevancy, context_precision, faithfulness]) print(result)
こちらを実行すると以下の結果が得られます。
{'ragas_score': 0.7888, 'answer_relevancy': 0.7673, 'context_relevancy': 1.0000, 'faithfulness': 0.6667}まずはこれで、全体のスコアは出せました。
ragas_scoreはそれぞれの評価指標での結果の調和平均をとったものになります。
調和平均というのは極端に値にペナルティを与えてスコアを計算する手法になります。
なぜ単純平均ではなくこの手法にしているかというと、一つの軸だけ極端によいという場合に全体のスコアに影響を出さないためです。
例えば評価結果でfaithfulnessが1でcontext_relevancyが0の場合を例にしてみましょう。
この場合コンテキストと回答は非常に一貫性が高いですが、質問とコンテキストが全く関係ないという状況なので、回答の質としては望ましいものではありません。
これを単純平均で計算すると0.5になりますが、調和平均にすると1.0という極端なスコアにペナルティをつけて0.0という結果になります。
このように、上記の指標は全体的に高いことが望ましいので、調和平均を使用しているようです。
また、全体のスコアだけでなく個別のQAについても評価軸ごとに結果を見ることができます。
result.to_pandas()

このようにto_pandas()を呼び出すことでDataFrameとして各QAごとの今回指定した3つの評価結果を得ることができます。
2問目のanswer_relevancyが低くなる想定ですが、結果としては3問目よりも高く出ています。
あくまで質問と回答の関連度なので、3問目が簡潔に回答しすぎなのと、2問目はモデルのバージョンについて言及しているという関連度が見られてスコアが高くなっているようです。
このようにOSSということもあり、評価方法については改善の余地はありそうです。
とはいえ、ローカルでここまで簡単に充実した回答評価を動かせるのはうれしいですね。
まとめ
今回はragasというライブラリを使用してRAGの回答を定量的に評価する仕組みを検証しました。
全面的に信用するというよりも考え方や、部分的に評価指標を利用するのが現実的な使い方になりそうです。
とはいえ、ここまで簡単にできる仕組みがあるのはうれしい部分でした。
それではまた。
Acroquest Technologyでは、キャリア採用を行っています。
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
www.wantedly.com