こんにちは、機械学習チーム YAMALEX の駿です。 
YAMALEX は Acroquest 社内で発足した、会社の未来の技術を創る、機械学習がメインテーマのデータサイエンスチームです。
(詳細はリンク先をご覧ください。)
皆さんは、飼っている猫が寂しそうだから兄弟みたいな犬を連れてきてあげようかな、と思ったことはありませんか?
私は猫も犬も飼ったことがないので何とも言えませんし、なぜ犬かはさておき、マルチモーダル検索を使えばそんな要望にも応えることができます。
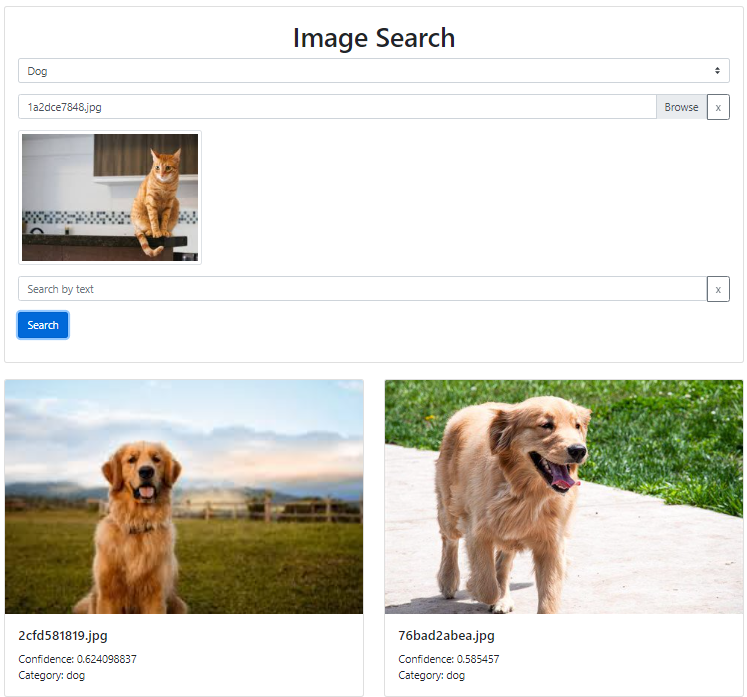
茶トラにはレトリーバーがお似合い
概要
マルチモーダル検索
マルチモーダル検索とは、テキストだけではなく、画像や音声などのデータも利用して情報検索を行う技術です。
例えば、画像を元に検索したり、テキストと画像を合わせて検索したりすることができるようになります。
今回は Amazon Bedrock 上で使える Titan Multimodal Embeddings と、外部サービスの Pinecone を組み合わせて、マルチモーダル検索を実現します。
Titan Multimodal Embeddings
Titan Multimodal Embeddings は Bedrock 上で利用可能な埋め込み(Embedding)モデルです。
入力としてテキスト、画像、またはその両方を受け取り、特徴を埋め込んだベクトルを出力(ベクトル化)します。
テキストに基づいた画像検索や、画像間の類似度検索など、複雑な検索クエリに応答できます。
Pinecone
Pinecone はベクトルデータを高速かつ安価で扱うために設計されたマネージドのベクトルデータベースです。
Python クライアントが用意されており簡単に利用できるだけでなく、他のベクトルデータベースと比べて最大で50倍も安くデータベースを利用できるそうです。
構成
下記処理を行うシステムを構築しました。
① 検索用画像を受け取る
② Bedrock の Titan Multimodal Embeddings でベクトル化する
③ Pinecone で類似画像を検索する
④ 検索結果をユーザに返す
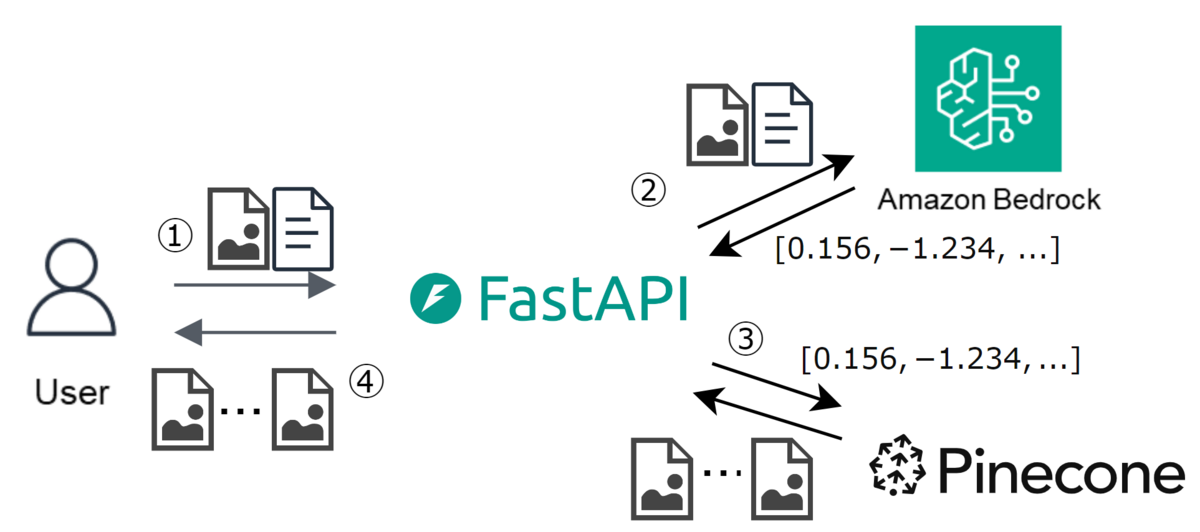
構成図
なお、検索対象のデータとして、こちらのデータセットをあらかじめベクトル化し、Pineconeに保存しました。
全部入れると安価とは言えど高額になってしまうため、犬、猫、ハムスターを各70枚ほどずつに絞ってあります。
Titan Multimodal Embeddings でベクトル化する
下記のコードを用いて、画面から受け取ったBase64文字列化された画像をベクトル化しました。
出力ベクトル次元は1024、384、256のいずれかを選択できますが、今回はデフォルトの1024次元にしました。
入力する画像/テキストには下記制限があるため適宜画像のリサイズなどが必要になる場合があります。
なお、画像は制限に収まっている限り、画像サイズや比率に制限はありません。
| # | 形式 | 上限 |
|---|---|---|
| 1 | 画像 | 25MB × 1枚 |
| 2 | テキスト | 128トークン |
bedrock = boto3.client("bedrock-runtime") model_id = "amazon.titan-embed-image-v1" def invoke(image_base64: str = None, text: str = None) -> list[float]: """画像とテキストをベクトル化する""" body = {} if image_base64: body["inputImage"] = image_base64 if text: body["inputText"] = text response = bedrock.invoke_model( body=json.dumps(body), modelId=model_id, ) # 1024次元のベクトルが取得できる return json.loads(response["body"].read())["embedding"]
Pinecone で類似画像を検索する
下記コードを用いてTitan Multimodal Embeddingsが出力したベクトルで画像を検索します。
Titan Multimodal Embeddingsが出力するベクトルが1024次元なので、Pineconeの設定も1024次元で作成してあります。
なお、Pineconeには画像のベクトル化された配列と、メタデータとして元画像のファイルパスが保存されており、元画像本体は保存していません。
検索後にメタデータのパスを参照し、画像を画面に表示します。
index = Pinecone(api_key=API_KEY).Index(INDEX_NAME) def upsert(vectors: list[list[float]], paths: list[str]): """ベクトル化した画像を保存する 各リストの同一番目の要素は同じ画像の情報を保持しているものとする """ entries = [ { # IDは何でもいいが、同じ画像に対して同じ値になるといい "id": path, # これが検索対象のベクトル "values": vector, # metadataの中身も特に規定はないため、検索時や検索後に使いたい情報を入れる "metadata": {"path": path}, } for vector, path in zip(vectors, paths) ] index.upsert(vectors=entries) def query(vector: list[float]) -> list[dict]: """ベクトル値で検索を行う ここでは上位5件の検索結果を返却している """ response = index.query( # 検索するベクトル vector=vector, # 取得件数 top_k=5, # 検索結果のベクトル値をレスポンスに含めない include_values=False, # 検索結果のメタデータはレスポンスに含める(画像パスを取得するため) include_metadata=True, ) results = [] for result in response.get("matches", []): results.append({ "path": result["metadata"]["path"], "score": result["score"], }) return results
できること
今回は上記構成のFastAPIアプリをローカル実行して、どんな検索が可能になるのかを確認してみました。
テキストでの検索
「茶色」で検索すると茶色い動物たちの画像がヒットしました。

茶色い動物を検索できる
画像での検索
マルチモーダルなので、テキストだけではなく画像もベクトル化できます。
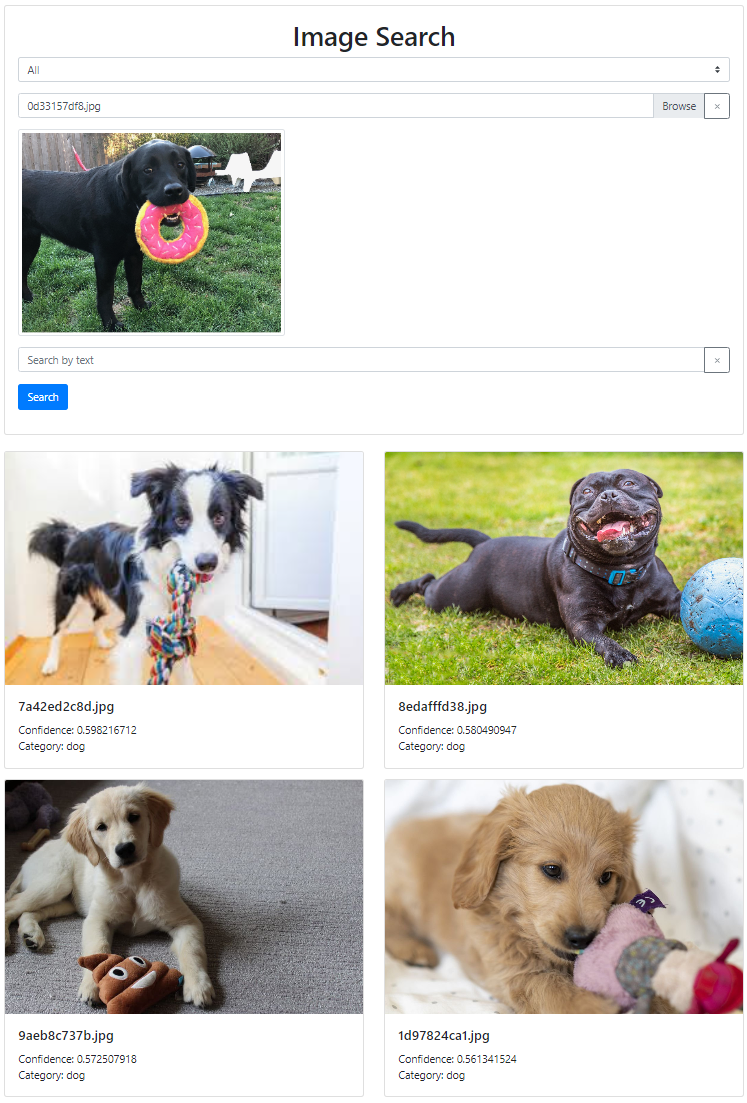
おもちゃを持った犬を検索できる
カテゴリを指定した検索
今回は③「Pineconeで類似画像を検索する」の部分でカテゴリ(犬、猫など)によるフィルタを設けることで、単に似ている画像というだけでなく「この猫に似ている犬の画像」の検索も実現しました。
[再掲]茶トラにはレトリーバーがお似合い
処理時間
下記条件で実行した際の処理時間を表に示します。
- Bedrockで処理している画像のサイズは800x800
- Pineconeは1024次元のベクトルで220件の中から検索する
- PineconeはAWS上のServerless タイプを使用
| # | 検索方法 | Bedrock レスポンス |
Pinecone レスポンス |
合計 | 画面に返るまで | |
|---|---|---|---|---|---|---|
| 1 | テキスト | ~0.9s | ~1.0s | ~1.9s | ~3.5s | |
| 2 | 画像 | ~1.4s | ~1.0s | ~2.4s | ~4.0s |
テキストをベクトル化するのよりも、画像をベクトル化するほうが時間がかかるようです。 直感とも一致しますね。
Pineconeで検索するときには、どちらも1024次元のベクトルに埋め込まれているため、実行時間に差はありませんでした。
なお「画面に返るまで」の時間には、画像のリサイズなどのデータ変換の時間を含みます。
まとめ
Titan Multimodal EmbeddingsとPineconeを使ったマルチモーダル検索エンジンを構築し、遊んでみました。
それぞれのAPIをただ呼び出しているだけですが、想定していたよりも求めていた結果が得られて驚いています。
素晴らしい!
Acroquest Technologyでは、キャリア採用を行っています。少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。 www.wantedly.com
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSやクラウドサービスを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長