皆さんこんにちは
機械学習チームYAMALEXの@tereka114です。
YAMALEXは Acroquest 社内で発足した、会社の未来の技術を創る、機械学習がメインテーマのデータサイエンスチームです。
(詳細はリンク先をご覧ください。)
日々、LLMが進化していて、画像が本職(のはず)の私ですら、ここ数年LLMの勉強をはじめています。
学習してモデル公開しましたといった記事はよく見ますが、今回は今、非常に注目されている日本に拠点があるAIスタートアップである「Sakana.ai」が公開した「Evolutionary Model Merge」を使う話をします。
Evolutionary Model Merge
「Evolutionary Model Merge」は「Sakana.ai」から発表された進化的モデルマージと呼ばれる技術です。
端的に言ってしまえば、複数のモデルを利用して新しいモデルを作ります。これにより、例えば数学の知識を持つモデルとECサイトの知識を持つモデルがあったときにECと数学の知識を持つモデルの生成ができます。
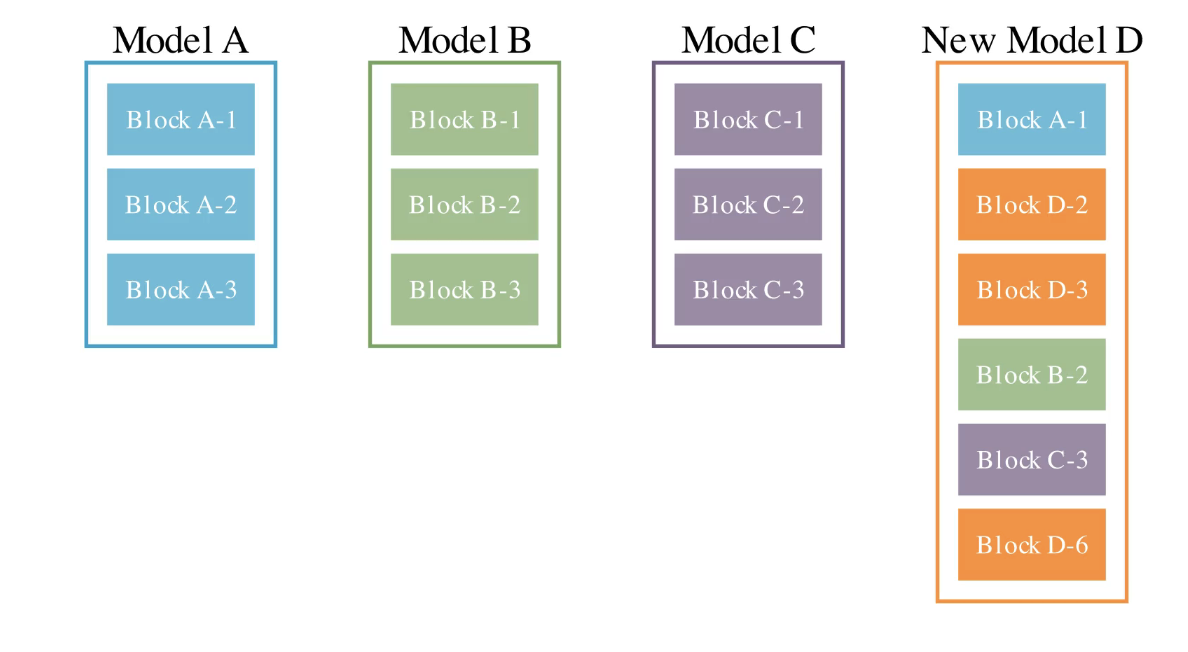
この方式では2つのマージ方式を使っています。
1. 既存モデルから層を採用する。
2. 既存モデルの重みを混ぜ合わせる。
しかし、この2つのマージ方式をどうするのか(混ぜ合わせパラメータやどの層を使うのかetc..)を人力で取り組んで成功させることは複雑すぎてできていませんでした。
「Evolutionary Model Merge」はこれらの複雑なマージをするために進化的な計算を取り入れるアプローチを組み込むことで、自動で複雑なマージを実施し、高精度化を実現しました。
構築済のものをマージすることで良い精度を出せるのはありがたく、一から学習するよりも容易です。今回実施するように個人環境でも十分動きます。
この技術を使ってドメイン特化のモデルを作りやすくなるのかなといった感触です。今回はこのEvolutionary Model Mergeをmergekitで試します。
※進化的な計算とは何か・と言った説明は公式の方で詳しくされていますので、次の公式ページを参照してください。この記事では実際の使い方などを解説します
sakana.ai
※Evolutionary Model Mergeオリジナルのリポジトリ、公式作成済モデル(EvoLLM-JPなど)も公開されています
github.com
EvoMergeを試す
Merge Kit
本手法は以下の「mergekit」に組み込まれています。
「mergekit」は、LLM学習済モデルのマージをする機能を持つ汎用ライブラリです。
github.com
開発元の次のブログを参考にして動かしてみますが、一部動作しないところがありましたのでその点をこの記事では修正しています。
blog.arcee.ai
インストール
まずは「merge-kit」のインストールです。
以下のコマンドを実行します。
git clone https://github.com/arcee-ai/mergekit.git cd mergekit pip install -e .[evolve]
設定ファイル
設定を次の通りに記述しました。
今回はspartqaのデータセットを利用しますが、データセットの量が多いので、サンプリングします。
import datasets ds = datasets.load_dataset("metaeval/spartqa-mchoice") slice_ds = ds["test"].select(range(200)) ds["test"] = slice_ds slice_ds = ds["train"].select(range(200)) ds["train"] = slice_ds ds.save_to_disk("./spartqa-mchoice-200")
次に以下の設定を記載します。
eval_tasks/spartqa_train.yaml
task: spartqa_train dataset_path: arrow dataset_kwargs: data_files: train: spartqa-mchoice-200/train/data-00000-of-00001.arrow test: spartqa-mchoice-200/test/data-00000-of-00001.arrow output_type: multiple_choice training_split: train validation_split: train test_split: train doc_to_text: !function preprocess_spartqa.doc_to_text doc_to_choice: [ 'A', 'B', 'C', 'D' ] doc_to_target: "{{answer}}" metric_list: - metric: acc aggregation: mean higher_is_better: true metadata: version: 1.0
次のPythonスクリプトも保存します。
これは、データセット1レコードを取得し、文章を構築して返す関数を定義し、与えられたデータの前処理を行います。
このパスは「eval_tasks/spartqa_train.yaml」のdoc_to_textの値に対応しています。
eval_tasks/preprocess_spartqa.py
def doc_to_text(doc) -> str: answer_chunks = [] for idx, answer in enumerate(doc["candidate_answers"]): letter = "ABCD"[idx] answer_chunks.append(f"{letter}. {answer}") answers = "\n".join(answer_chunks) return f"Context:\n{doc['story']}\n\nQuestion: {doc['question']}\n{answers}\nAnswer:"
そして、merge-kitで利用するモデル設定ファイルを作ります。マージ実行時にダウンロードがはじまります。
Mistral7Bを3種類のデータでInstruct Tuningをしたモデルに対して実施します。これにより3種類の特性を持ったモデルの作成を目指します。
evol_merge_config.yml
genome: models: - NousResearch/Hermes-2-Pro-Mistral-7B - PocketDoc/Dans-AdventurousWinds-Mk2-7b - HuggingFaceH4/zephyr-7b-beta merge_method: task_arithmetic base_model: mistralai/Mistral-7B-v0.1 layer_granularity: 8 # sane default allow_negative_weights: true # useful with task_arithmetic tasks: - name: spartqa_train weight: 1.0
実行
次のコマンドを実行します。
mergekit-evolve ./evol_merge_config.yml \ --storage-path evol_merge_storage \ --task-search-path eval_tasks \ --in-memory \ --merge-cuda --wandb
進化的計算を行っているログが表示され、計算されていきます。
Wandbを見ると、精度向上した段階の精度が記録されます。10回に一度ぐらい更新されていき、全体で1〜2時間ほど実行時間がかかります。

なお、データはサンプリングしないと時間がかかるので、可能であればデータをサンプリングして実施するのが望ましいです。
感動的なのは、私のマシン構成であるRTX3090x2の構成で十分動いたので、7Bをそのまま学習するよりは簡単だったことです。すごいです。推論だけならまだしも7Bの重み全ての学習は通常GPUメモリが不足し、動きません。
適切な学習データを準備してモデルの候補並べて、「Evolutionary Model Merge」をするとドメイン特化の良いモデルが手軽に作れそうです。
トラブルシュート
1. ログインを要求された場合
実行途中途中、Mistralのダウンロードがありますが、事前にcliの設定によるhuggingfaceアカウントへのログインが必要となります。
APIKeyを作成して、ログインしましょう。
huggingface-cli login
2. Flash Attentionのバージョン不足
以下の例外が発生した場合、flash-attnのライブラリのバージョンが低すぎることを示します。
ImportError: FlashAttention2 has been toggled on, but it cannot be used due to the following error: you need flash_attn package version to be greater or equal than 2.1.0. Detected version 2.0.4. Please refer to the documentation of https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-2 to install Flash Attention 2.
以下のコマンドを実行して、アップグレードしましょう。
pip install flash-attn --upgrade
実行
最後に「Evolutionary Model Merge」の結果で得られたモデルを実行します。
まずは、「Evolutionary Model Merge」のベストなパラメータは「evol_merge_storage/best_config.yaml」に保存されています。
その設定に従ってまずは、次のコマンドでマージ後のモデルを生成します。マージ後のモデルは「merge」ディレクトリに保存されます。
mergekit-yaml evol_merge_storage/best_config.yaml merge
後はhuggingfaceと同じ使い方で推論可能です。
import torch from transformers import AutoTokenizer, AutoModelForCausalLM device = "cuda" # the device to load the model onto model = AutoModelForCausalLM.from_pretrained("merge", device_map="auto") tokenizer = AutoTokenizer.from_pretrained("merge") messages = [ {"role": "user", "content": "What is your favourite condiment?"}, {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"}, {"role": "user", "content": "Do you have mayonnaise recipes?"} ] encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt") model_inputs = encodeds.to(device) generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True) decoded = tokenizer.batch_decode(generated_ids) print(decoded[0])
最後に
LLMを一から全て学習させるのは非常に高いコストがかかります。
LoRAによる追加学習も(比較して)スタンダードな低コストなアプローチの代表例ですが、Model Mergeによるベースモデルの改修といった観点は今までになく非常に面白いアプローチに思えます。
今後、業務の中でモデルのマージ技術も使って精度向上の検討をしていきたいと思いました。とても今後の「Evolutionary Model Merge」の進化に期待しています。
Acroquest Technologyでは、キャリア採用を行っています。
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。Azure OpenAI Serviceを活用したいエンジニア募集! - Acroquest Technology株式会社のデータサイエンティストの採用 - Wantedlywww.wantedly.com