最近ソーダストリームを買い、炭酸水を飲むのにはまってます。機械学習エンジニアの@yktm31です。

以前に「AWS Lake Formationでデータレイク体験!」という記事を書いてみて、データ基盤アーキテクチャに興味が湧いてきました。
データレイクハウスは、「データウェアハウス」と「データレイク」を統合したようなアーキテクチャで、 2020年にDatabricks社により提唱され、新しいデータ基盤アーキテクチャとして注目されているようです。
そこで今回、「データレイクハウス」について調べてみたことをまとめてみたいと思います。
なぜデータレイクハウスが注目されているのか?
データ基盤アーキテクチャは、以下のような変遷をたどっていて、データレイクハウスが最新のアーキテクチャという流れのようです。 それぞれの登場時期、利用用途を以下にまとめて見ました。
| アーキテクチャ | 登場時期 | 利用用途 |
|---|---|---|
| データウェアハウス | 1980年代 | ビジネス意思決定のためのデータ分析 (BI) |
| データレイク | 2000年代 | 非構造化データを使う機械学習 (ML) |
| データレイクハウス | 2020年 | BIとMLの両立 |
最新のデータ基盤アーキテクチャであるデータレイクハウスの必要性を理解するために、 まず、データウェアハウスとデータレイクそれぞれの特徴・課題を見ていきたいと思います。
データウェアハウスの特徴・課題
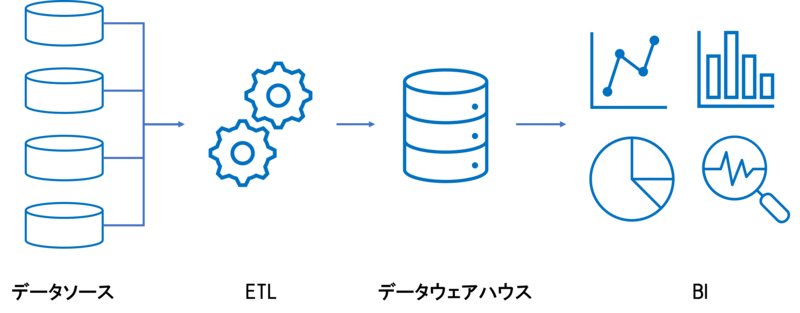
データウェアハウスは、ビジネス意思決定のためにデータを一つの場所に集約・保管し、分析に利用するためのデータ基盤アーキテクチャで、1980年代に考案されたそうです。 (私が生まれたのは1997年なので、生まれる前からこうしたデータ基盤アーキテクチャが考えられていたのは驚きでした。) 例えば、「Amazon Redshift」はデータウェアハウスを提供しているサービスとして有名だと思います。
データウェアハウスの特徴として、以下のような点が挙げられていることが多かったです。
- 複数のソースから取得したデータにETL処理を施し、構造化データを蓄積する。
- スキーマが決まっていて、トランザクションもサポートされることでデータ一貫性が担保されている。
- 権限管理が行え、データへのアクセスコントロールが効く。
しかし反面、ビジネスで扱うデータの多様化により、データウェアハウスだけでは新たなニーズに応えられなくなっていったそうです。 とくに、非構造化データを使う機械学習の発展に、データウェアハウスのスキーマが決まっているという点が大きな制約となったようです。
データレイクの特徴・課題

画像やテキストなど非構造化データの分析という新たなニーズに合わせ、データレイクというデータ基盤アーキテクチャが2000年代に入り誕生したそうです。
例えば、「Amazon S3」や「Azure Data Lake Storage」といったクラウドストレージシステムと周辺サービスを組わせるとデータレイクとなります。
データレイクの特徴として、以下のような点がよく挙げられています。
- 未加工のデータが格納され、主にデータ分析や機械学習で利用されることが多い。
- データの形式に制限がなく、テキストデータやセンサーデータ、画像、テキストなど、構造化データ以外のデータも格納できる。
他方、以下の2点がリスク・課題としてもよく挙がります。
- データレイクはトランザクションはサポートされないためデータ品質が保証されない。
- 自由にデータが配置できる反面、本当に必要なデータが見つかりづらくなる、データスワンプとなるリスクがある。
トランザクションがサポートされないというデータレイクの欠点を補う必要がある場合は、データレイクとデータウェアハウスを併用するようです。
データレイクのデータを直接扱うだけでなく、ETL処理を施しデータウェアハウスにデータを登録することで、トランザクションを実現する試みです。 しかしその方式では、データ一貫性を保つのが難しいなど、デメリットも残っている現状のようです。
ここまでで、データウェアハウス、データレイクの比較をまとめてみました。
| 特徴 | データウェアハウス | データレイク |
|---|---|---|
| 扱えるデータ形式 | 構造化データのみ、加工・整形済みデータ | 構造化データ、半構造化データ、非構造化データ、生データ |
| 代表的な利用用途 | BI (過去データの分析) | ML (将来予測) |
| データ一貫性 | 〇 | × |
| データの自由度 | × | 〇 |
| コスト | データ保持・構築ともにコストがかかる | データサイズに対して比較的安価 |
| 主な利用者 | ビジネスアナリスト | データサイエンティスト |
データレイクハウスの特徴
データレイクハウスが登場したのは、データウェアハウス・データレイクそれぞれの特徴を活かしつつ、 課題をうまく解決するためでした。
まず、データレイクハウスはどのような特徴を持ち、既存の課題をどう解決したのかをまとめてみたいと思います。
データレイクハウスのアーキテクチャ
ここからは、データレイクハウスのアーキテクチャについて具体的に見ていきます。 データレイクハウスのアーキテクチャは、概ね以下のようなレイヤー構造からなっているようです。

メダリオンアーキテクチャとは、データレイクのデータ配置を、データの質によって3つのレイヤーに分けるアーキテクチャということらしいです。 3つのレイヤーはそれぞれ、Bronze、Silver、Goldとなっています。

Azure
Azureでドキュメントで提示されているデータレイクハウスアーキテクチャを見ていきます。

Azureのこのレファレンスアーキテクチャのポイントを3つ挙げてみました。
- Azure Synapse Analyticsを中心としたアーキテクチャ
- Azure Synapse サーバーレス SQL プールとPowerBIによるデータ可視化
- Azure Machine Learningを利用した機械学習利用
Azure Synapse Analyticsを中心としたアーキテクチャ
Azure Synapse Analyticsとは、データウェアハウス・ビッグデータ解析を統合したデータ分析プラットフォームです。 Azure Synapse Analyticsを利用することで、SQL / Apache Sparkによるデータ分析が用意に実現できるようになります。
Azure Synapse サーバーレス SQL プールとPowerBIによるデータ可視化
Azure Synapse サーバーレス SQL プールを利用し、Azure Data Lake Storageに保存されたParquetファイルに対し、 SQLベースでデータ探索を行い、Power BIに結果を可視化します。
Power BIとSynapseを連携する際、Power BI Linked Serviceで直接連携することも可能ですが、 その方式では、ワークスペースが1つのみに制限されてしまいます。 そのため、サーバーレス SQL プールを利用することが一つのポイントになります。
Azure Machine Learningを利用した機械学習利用
Azure Machine Learningを利用し、推論した結果をデータレイクに保存し、PowerBIで可視化することが出来ます。 学習するデータの取得、整形のためにはAzure Synapse サーバーレス Apache Spark プールが利用できます。 Azure Machine Learningによる推論結果は、データレイク中のゴールドレイヤーに保存されることになります。
参考
Azure Databricksを利用した代替案
ここまで、Azure Synapse Analyticsを利用したデータレイクハウスアーキテクチャを見てきましたが、 代替アーキテクチャとして、Azure Databricksを利用する方法もあるようです。
Azure Databricksは、SQL / ML / データ分析をするためのプラットフォームです。 Azure Databricksを利用したデータレイクハウスのアーキテクチャは以下のドキュメントが参考になりそうでした。 learn.microsoft.com
AWS
次に、AWSにおけるデータレイクハウスのアーキテクチャを見ていきます。ここでは、AWS Big Data Blogで提示されているアーキテクチャを参考にしていきます。

AWSのこのレファレンスアーキテクチャのポイントをまとめると、以下のような点が分かりました。
- メタデータレイヤーとして、AWS Lake Formationを利用
- Amazon S3とAmazon Redshiftのネイティブな連携
- Amazon Athena / Amazon QuickSight / Amazon SageMakerなどのサービスから、統一されたインターフェースでデータ利用できる
メタデータレイヤーとして、AWS Lake Formationを利用
AWS Lake Formationは、データの行/列レベルの権限管理や、ACIDトランザクションを提供しています。 Amazon S3やAmazon Redshiftに格納されているデータ本体と、メタデータをレイヤーとして分離することで、スキーマオンリードを実現します。
データレイク単体では、データのスキーマが変更されても、変更を検知することは難しいです。 そのため、読み込むデータがどのようなスキーマか確認することが必要になり、このスキーマオンリードの考え方が重要になってくるようです。
また、データレイクは、データのスキーマが変わることが考えられますが、 AWS Glueを通じて、中央データカタログは更新されていくので、変更に追従できるということのようです。
Amazon S3とAmazon Redshiftのネイティブな連携
データをBIで利用する場合、整理された構造化データが分析パフォーマンスの上で重要になります。他方、機械学習では非構造化データを扱うことになります。
例えば、大量の履歴データがデータレイク(Amazon S3)に保管され、BIでの分析対象分のデータは、データウェアハウス(Amazon Redshift)にAmazon Redshift Spectrumを通じて展開、 そして、逆にデータウェアハウス(Amazon Redshift)で不要になったデータは、データレイク(S3)にオフロードするという使い方ができるらしいです。 データウェアハウス(Amazon Redshift)からデータレイク(Amazon S3)にオフロードされたデータも同じクエリでアクセスすることができるようです。
Amazon Athena / Amazon QuickSight / Amazon SageMakerなどのサービスから、統一されたインターフェースでデータ利用できる
以下のようなサービスから、データレイクハウスのデータを扱うことができます。
| サービス | 用途 |
|---|---|
| Amazon Athena | SQL |
| Amazon QuickSight | BI |
| Amazon SageMaker | ML |
| Amazon Redshift Spectrum | データ分析 |
まとめ
機械学習やビッグデータ系のプロジェクトをやっているとき、データをどうやって管理する?という課題がよく出てくる実感があります。 今回見てきたデータレイクハウスは、ぜひデータ管理アーキテクチャの設計に活かしていきたいと感じました。
ただ、データレイクハウスは、自前で0から構築するとなると、かなり大変そうな印象を受けました。 なので、クラウドサービスで簡単に構築できそうなところは、有難いなと思いました。
Acroquest Technologyでは、キャリア採用を行っています。少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。 www.wantedly.com
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長