こんにちは。社内データサイエンスチームYAMALEXの@Ssk1029Takashiです。
最近はChatGPTが出て注目を浴びたり、BingにもChatGPTのように質問応答してくれるAIが搭載されるなど、OpenAIのGPTモデルが世の中を騒がせています。
私もChatGPT使ってみましたが、受け答え自体は人が書いていた文章と遜色なく、文章の自動生成もここまで来たか。。という感じでした。
そんなChatGPTの特徴の一つとして、回答には時々嘘が含まれるというものがあります。
ChatGPT自体は知識を持っているわけではないので、学習データにないことなどはそれっぽいけどでたらめな回答を返してしまいます。
ただし、最近追加されたBingのGPTでは、ChatGPTよりもはるかに正確な回答が返ってくるように感じます。

画面を見ると回答の根拠となっている詳細情報が出ています。
ここから推測すると、BingのGPTはまず回答の根拠となる情報を検索し、その情報をコンテキストとして質問に回答しているのではないかと思います。
GPTはQuestion Answeringというタスクも学習しているはずなので、回答の根拠となる情報をコンテキストに与えるとそこから回答を生成し、誤答を減らせるはずです。
今回はこの根拠を取得、質問回答という流れをOpenAIのAPIを使いながら、簡易的に実装してみます。
OpenAI APIとは
OpenAI APIとは、その名の通りですがOpenAIが提供している機械学習モデルを活用できるAPIのことです。
ユーザーはこのAPIを使って、GPT-3モデルでの推論やファインチューニングなどが可能になります。
詳細なドキュメントは以下にあります。
platform.openai.com
また、API経由でなくてもPlaygroundという画面からモデルへの入力を打ち込むだけで、結果が分かるページも用意されいます。
まず何ができるのか知りたいという方はこのページからいろいろ打ち込んでみるだけでも楽しいと思います。
platform.openai.com
今回利用する機能は以下の2つになります。
- 文章をベクトル化するEmbeddings
- 入力文の後ろに続く文章を出力するCompletions
また、各APIごとに利用できる事前学習モデルとして複数のモデルが用意されています。
例えばEmbeddingsだと以下の種類のモデルが利用可能です。
それぞれデータが作成された時期や精度、パラメータ数などが異なるため用途によって使い分ける必要があります。
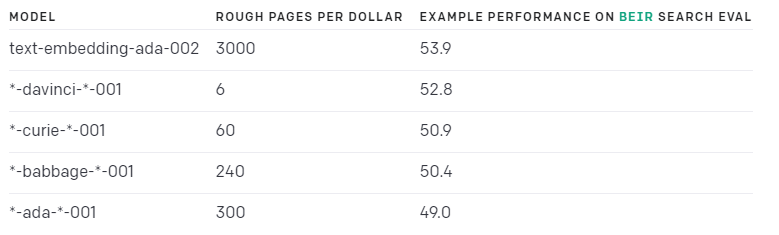
platform.openai.com
今回はEmbeddingsではtext-embedding-ada-002、Completionsではtext-davinci-003というモデルをそれぞれ使います。
概要
OpenAIのAPIからはChatGPTの元となったモデルであるGPT-3を使用することができます。
ChatGPTやGPT-3でなるべく誤りのない回答を取得する方法は回答を含む文章を一緒に与えることです。
例えば、GPT-3に何も情報を与えず、「Acroquest Technologyはどこにある会社ですか?」というと普通に嘘が返ってきます。

ここに、Acroquest Technologyの説明文を入力を加えると以下のように正確に回答できます。

つまり回答に関する文章を参照さえできれば、それを質問文とともにGPT-3の入力とすることで正確な回答を得られるということです。
ただし、正確な回答を得るためには入力する文章に質問の回答を示す内容が含まれている必要があります。
GPT-3には一度に入力できる文章量は限られているので、関連のある文章をすべて一気に入力するのではなく、回答を含む文章を見つける必要があります。
回答を含む文章を見つける方法は検索など様々な方法がありますが、今回はGPT-3を使って質問文から類似文章検索をすることで取得します。
OpenAI APIにはembeddingという、文章をベクトル化する機能があるので、これを利用します。
まとめると以下のようなステップになります。

今回はこの流れを厚労省が提供しているコロナウイルスのFAQサイトの一部を使用して検証してみます。
www.mhlw.go.jp
実際にやってみる
あまり説明を長くしてもしょうがないので、実際に試してみましょう。
OpenAI APIをPythonから利用する準備
OpenAI APIはPythonライブラリを用意しており、以下のコマンドでインストールできます。
pip install openai
インストールした後、API Keyを設定する必要があります
以下のようにコードの先頭に記述することで、ライブラリが参照するKeyを設定します。
import openai openai.api_key = "<自分のアカウントのAPI Key>"
API Keyは以下の記事などを参考に作成できます。
auto-worker.com
①関連文書をベクトル化
まずは、一つ目のステップである関連文書、今回で言えばFAQサイトの文章をベクトル化します。
Pythonでベクトル化する場合以下のようなコードでベクトル化することができます。
text = "これまで、ワクチン接種、検査、治療薬等の普及による予防、発見から早期治療までの流れをさらに強化するとともに、最悪の事態を想定した対応を進めてきました。" embedding = openai.Embedding.create(input = [text], sentences, model="text-embedding-ada-002")['data'][0]['embedding']
APIを呼び出す際に注意が必要なことは、入力できる文章の長さにAPI・モデルの種類ごとに制限があることです。
例えば、Embeddingsでtext-embeddings-ada-002モデルを利用するときには、最大token数は8192が制限になります。
日本語は基本的には一文字が1tokenなので、8192文字の文章までしか入力できません。
なので、今回はFAQサイトの質問文は使わずに、一つの回答文をそれぞれベクトルに変換します。
変換したベクトルは検索できるように蓄積しておく必要があります。
今回はFaissを使用して検索を試してみるので、通しだと以下のようなコードになります。
(関連文章のリストはsentences変数にすでに格納済みとします)
FaissとはPythonでベクトル検索をするためのライブラリです。
詳細な説明は省略するので、詳しく知りたい方は以下のサイトに詳細が載っているので参照してみてください。
qiita.com
import faiss import numpy as np # 文章をベクトル化 sentences = [x.replace("\n", " ") for x in sentences] embeddings = openai.Embedding.create(input = sentences, model="text-embedding-ada-002")['data'] # 初期化 d = 1536 index = faiss.IndexFlatL2(d) # faissで扱えるようnumpyのarrayに変換 embeddings = np.array([x["embedding"] for x in embeddings], dtype=np.float32) #FaissのIndexに追加 index.add(embeddings)
②質問文をベクトル化して検索
次のステップを質問文も同じくベクトル化して、質問文と意味が似た回答文を検索します。
今回は簡易的にするため、最も近い文章のみを取得します。
# ベクトル化 query = "コロナウイルスは主にどのように感染しますか?" query_embedding = np.array([openai.Embedding.create(input = [query], model="text-embedding-ada-002")['data'][0]["embedding"]], dtype=np.float32) # ベクトル検索 k = 1 D, I = index.search(query_embedding, k) result = sentences[I[0][0]] print(result)
例えば、「コロナウイルスの基本的な感染防止策は?」という質問の結果は以下のようになります。
'\n\n\n長期間にわたって感染拡大を防ぐために、飛沫感染や接触感染、さらには近距離での会話への対策を、これまで以上に日常生活に定着させ、持続させなければなりません。それを「新しい生活様式」と呼ぶこととし、具体的な実践例は以下にある通りです。\nなお、実践例については、令和2年5月4日に新型コロナウイルス感染症専門家会議から提言があった以降も、移動自粛の緩和や、夏場の熱中症対策との両立などの記載内容を更新しております。\nまず、1.身体的距離の確保(できるだけ2m)、2.マスクの着用、3.手洗い、の3つを、一人ひとりの方の基本的な感染防止策としています。\nまた、日常生活では、上記に加えて、「3密」の回避や、換気、まめな体温・健康チェックが効果的です。(換気については、2方向の窓を開け、数分程度の換気を1時間に2回程度行うことが有効です。体温・健康チェックは、毎朝行うなど決まった時間に行ってください。)\n働き方については、テレワークや時差通勤を進め、オンラインで可能なことはオンラインで行って下さい。\n\n【3つの密を避けるための手引き】\nhttps://www.mhlw.go.jp/content/10900000/000622211.pdf\n\n新型コロナウイルス感染症対策にあたっては、全都道府県において、基本的な感染防止策の徹底等が必要であるとともに、感染の状況等を継続的にモニタリングし、その変化に応じて、迅速かつ適切に感染拡大防止の取組を行う必要があります。その土台となるのは、こうした新しい生活様式の定着ですので、ご協力をお願いします。\n\n'
確かにトピックとして聞きたい内容が載っているように見えます。
③回答を生成する
最後に回答を生成します。
回答の生成の場合は、CompletionというAPIの入力に、検索結果の文章と質問文を入力することで回答を取得できます。
result = result.replace("\n", " ") answer = openai.Completion.create(engine="text-davinci-003", prompt=f"{result}\n\nQ: {query}\n", max_tokens=256)["choices"][0]["text"] print("質問") print(query) print("元文章") print(result) print("回答") print(answer)
こうすることで以下の出力を得られます。
質問 コロナウイルスの基本的な感染防止策は? 元文章 長期間にわたって感染拡大を防ぐために、飛沫感染や接触感染、さらには近距離での会話への対策を、これまで以上に日常生活に定着させ、持続させなければなりません。それを「新しい生活様式」と呼ぶこととし、具体的な実践例は以下にある通りです。 なお、実践例については、令和2年5月4日に新型コロナウイルス感染症専門家会議から提言があった以降も、移動自粛の緩和や、夏場の熱中症対策との両立などの記載内容を更新しております。 まず、1.身体的距離の確保(できるだけ2m)、2.マスクの着用、3.手洗い、の3つを、一人ひとりの方の基本的な感染防止策としています。 また、日常生活では、上記に加えて、「3密」の回避や、換気、まめな体温・健康チェックが効果的です。(換気については、2方向の窓を開け、数分程度の換気を1時間に2回程度行うことが有効です。体温・健康チェックは、毎朝行うなど決まった時間に行ってください。) 働き方については、テレワークや時差通勤を進め、オンラインで可能なことはオンラインで行って下さい。 【3つの密を避けるための手引き】 https://www.mhlw.go.jp/content/10900000/000622211.pdf 新型コロナウイルス感染症対策にあたっては、全都道府県において、基本的な感染防止策の徹底等が必要であるとともに、感染の状況等を継続的にモニタリングし、その変化に応じて、迅速かつ適切に感染拡大防止の取組を行う必要があります。その土台となるのは、こうした新しい生活様式の定着ですので、ご協力をお願いします。 回答 A: コロナウイルスの感染防止策として、「身体的距離の確保(できるだけ2m)」、「マスクの着用」、「手洗い」、「3密の回避」、「換気」、「まめな体温・健康チェック」を基本的な感染防止策として推奨しています。
回答も実際の事実と正しいですし、元となる情報も参照できるため、真実かどうか確認することもできます。
ここまでで、GPT-3を使って、根拠付きで質問の回答を得ることができました。
もちろん、実際はこんな簡単ではなく、検索結果の文章が必ずしも正しいわけではなかったり、質問の回答の精度も100%ではなかったリなど様々な課題があります。
これらは今後の改善ポイントではありますが、OpenAIのAPIを用いて簡単に実現できました。
まとめ
GPT-3を使って根拠付きでなるべく正確な回答を返す方法を検証しました。
実際少量のデータで、簡単な問であれば、ベクトル検索と文章生成を組み合わせることで可能になります。
GPT-3などのモデルはまだまだこれからも進化していきそうなので、より便利なものを簡単に作れるようになりそうです。
それではまた。
2月17日追記:GPT-4に関しては出典が明確ではない情報だったため、記述を削除しています。
2月24日追記:embedding作成のコードに一部記載ミスがあったため修正しています。
Acroquest Technologyでは、キャリア採用を行っています。
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。