
こんにちは、DevOpsチームの@buzz_tkcです。
最近枕を「ヒツジのいらない枕」に買い換えました。2020年にクラウドファンディングで話題になっていた時から、キャッチーなネーミングと興味がそそられるフォルムが気になっていたはいたのですが、やっと重い腰を上げて買い換えました。弾力があり高さのある枕が好みの自分にとてもフィットしており、おかげさまで睡眠が捗っております。
さて、今回は AWSが公開している「MLOps Workload Orchestrator」を、試してみたいと思います。
機械学習プロジェクトにおいて、以下のような課題に直面したことがある人は多いのではないでしょうか?
- 学習リソース不足
- GPUマシンが足りず、並列実験ができない、、、
- ローカルで検証したモデルを本番環境へ適用するのに時間がかかる
- デプロイの自動化が大変、、、
- 実験が再現できず、品質保証ができない
- 何個か前の精度が良かった学習の再現が難しい、、、
そのような際に、MLOpsのプラクティスが有効とされていますが、自分も機械学習エンジニアではないため、何をどのようにすれば良いのか、イメージを持てていなかった部分があるので、「MLOps Workload Orchestrator」を試してみて、理解を深めていきたいと思います。
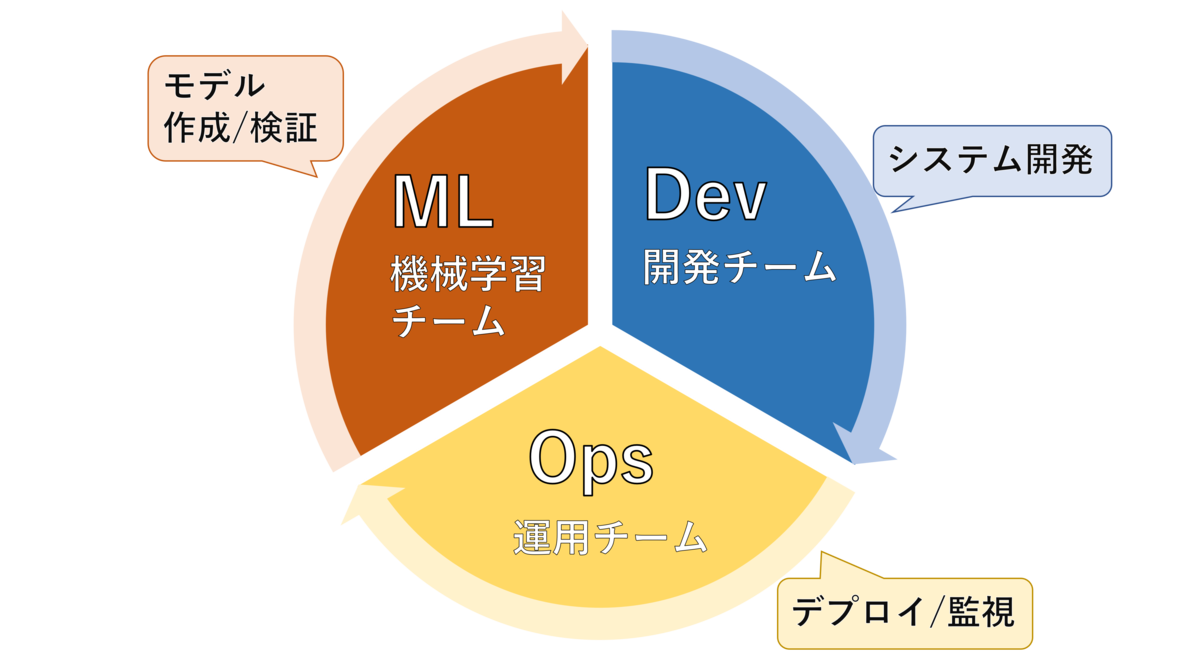
MLOps とは?
MLOpsとは、「機械学習チーム(Machine Learning)/開発チーム(Developers)」と「運用チーム(Operations)」がお互いに協調し合うことで、機械学習モデルの実装から運用までのライフサイクルを円滑に進めるための管理体制(機械学習基盤)を築くこと、またはその概念全体を指します。まさにDevOpsの機械学習版ですね。(MLOps = ML + Dev + Ops)
Wikipediaにも、DevOpsの概念がベースとなって、MLOpsが生まれたと書かれていますね。
ソフトウェア開発ライフサイクル全体におけるワークロードの管理は、従来からDevOpsの概念があった。機械学習プロジェクトにDevOpsを適用した場合、モデルトレーニング等を含むのCI/CDのプロセス管理やデータサイエンティストとデータエンジニアの職種の役割分担など多数の機械学習特有の課題を考慮する必要が生まれた。その結果DevOpsをベースに機械学習プロジェクトに合理化された手法がMLOpsとして概念化された。
機械学習で精度の高いモデルを作るためには、多くの時間を試行錯誤に費やしモデルを育てていく必要があります。しかし実際には、動作環境の構築、システム全体の開発など、モデル作成以外でもやるべきことが多く、モデル作成に時間を多く割けないことが多いです。MLOpsを実践し、機械学習ワークフローの自動化・効率化を進めていくことで、良いモデルを育てるというコアな部分に、多くの時間を費やすことができるようになります。
AWS MLOps Workload Orchestrator とは?
「MLOps Workload Orchestrator」は、AWS の機械学習サービスとサードパーティーサービスの機械学習パイプラインを管理するためのフレームワークで、機械学習モデルの運用向けにアーキテクチャのベストプラクティスを合理化および強制するのに役立ちます。
具体的には、このサンプルテンプレートを使用し、トレーニング済みのモデル(自分で用意する)をデプロイすることで 、モデルのデプロイや運用/監視を簡単に実現することができます。モデルのデプロイや運用/監視を自動化することで、モデルの検証や更新のサイクルを高速に回すことができ、プロジェクト全体の俊敏性と効率を上げることができます。
aws.amazon.com
AWS MLOps Workload Orchestrator を使ってみる
このサンプルテンプレートでは、同アカウントへのデプロイと、マルチアカウントへのデプロイと大きく二種類対応しています。今回は同アカウントへのデプロイを扱います。アーキテクチャは以下になります。
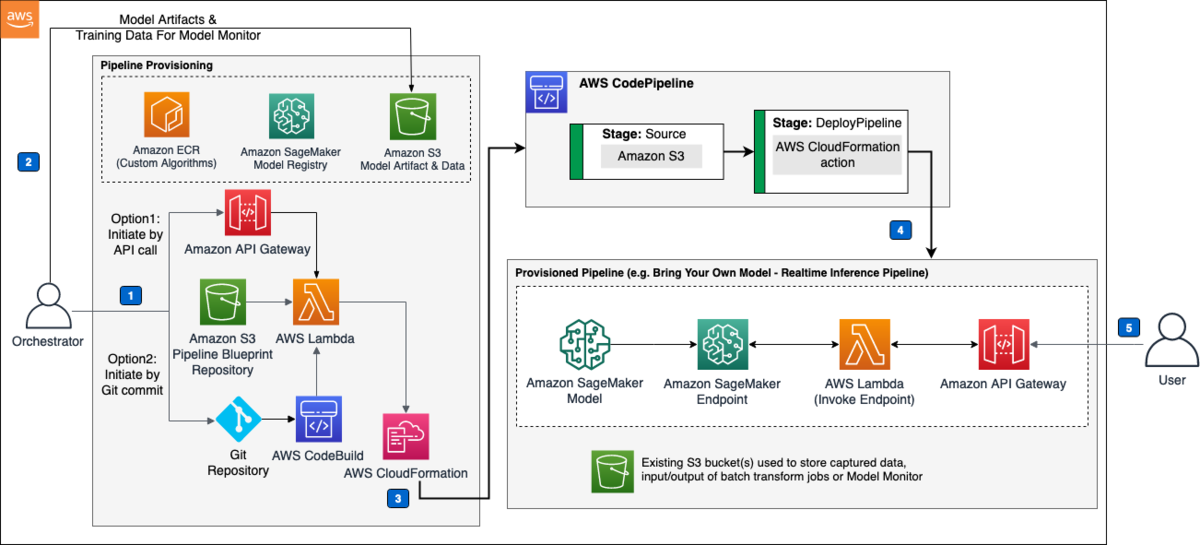
やることとしては、以下の3つです。
- CloudFormationテンプレートを実行してスタックを作成
- 通知用のメールアドレスを入力するだけでスタックを作成できます。
- パイプラインをプロビジョニングして機械学習モデルをデプロイ
- モニタリング用パイプラインのプロビジョニング
- 2.の実行が完了し、機械学習モデルがエンドポイントにデプロイされている状態で、実行する必要があります。
学習(モデルの作成)自体はスコープ外なので、事前準備として、学習済みモデルが必要です。今回は、AWSが公開している公式サンプルを実行して用意しました。
1. CloudFormationテンプレートを実行してスタックを作成
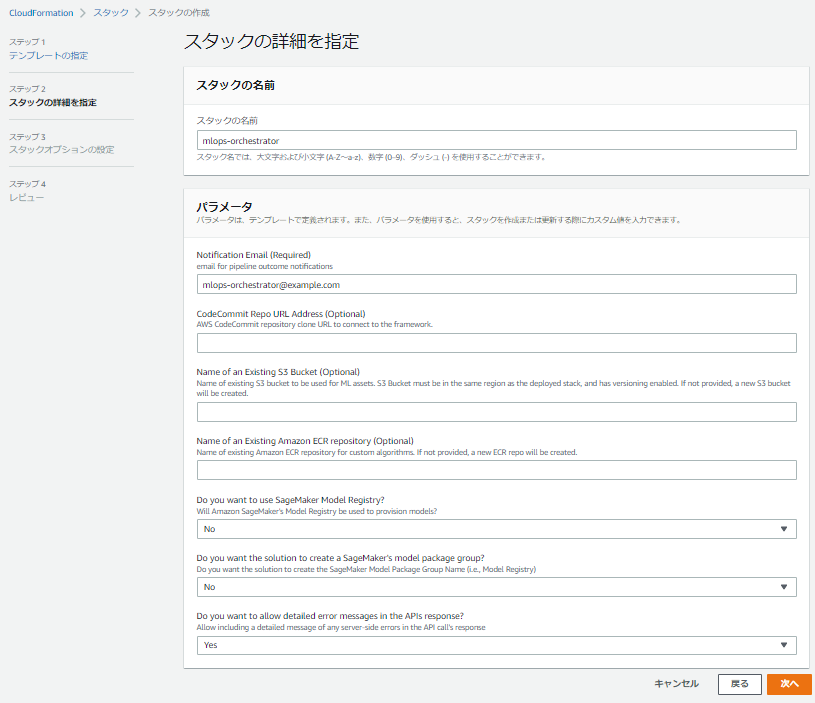
CloudFormationのManagement Consoleに移動し、CloudFormationテンプレートから、「mlops-workloadorchestrator-single-account-framework.template」を選択します。
以下のパラメータの中から、必須項目の通知用メールアドレスを入力して、スタックを作成します。
この段階で、赤枠の部分が作成されます。
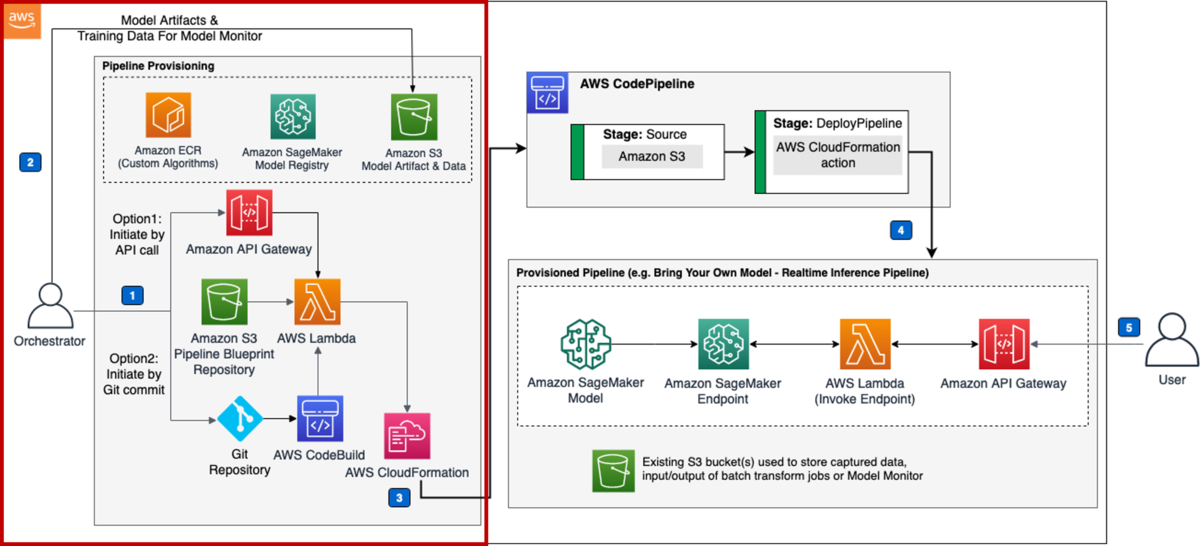
2. パイプラインをプロビジョニングして機械学習モデルをデプロイ
続いて、機械学習モデルデプロイのワークフローを実行します。Code Commitのレポジトリルート直下にmlops-config.jsonをコミットするか、APIにリクエストを送ることで、ワークフローを実行できます。今回はAPIへのリクエストを試してみます。
先程実行したCloudFormationで「/provisionpipeline」と「/pipelinestatus」二つのエンドポイントが作成されているので、「/provisionpipeline」に対して、学習済みモデルをエンドポイントにデプロイするためのリクエストを投げます。「/pipelinestatus」は「/provisionpipeline」実行後、パイプラインのステータス確認用として使用できます。
EndPoint:/provisionpipeline
Method:POST
Body:
{ "pipeline_type" : "byom_realtime_builtin", # Sage Makerが用意しているビルトインアルゴリズムを使用してのリアルタイム推論を行うパイプラインをプロビジョニング "model_framework": "xgboost", # モデル作成時に使用したフレームワーク "model_framework_version": "1", # フレームワークのバージョン "model_name": "my-model-name", # Amazon SageMaker modelや、エンドポイント作成時に使用されるモデル名 "model_artifact_location": "path/to/model.tar.gz", # 事前に学習し、S3に格納しておいたモデルパス "data_capture_location": "<bucket-name>/<prefix>", # エンドポイントへの推論結果のデータキャプチャを保管S3へのパス "inference_instance": "ml.m5.large", # エンドポイントで使用するインスタンスタイプを指定 "endpoint_name": "custom-endpoint-name" # エンドポイント名を指定 }
「byom_realtime_builtin」用のパイプラインがプロビジョニングされ、エンドポイントが立ち上がり、推論を行うことができるようになりました。簡単に推論を行える環境が用意できるので、非常に便利ですね!
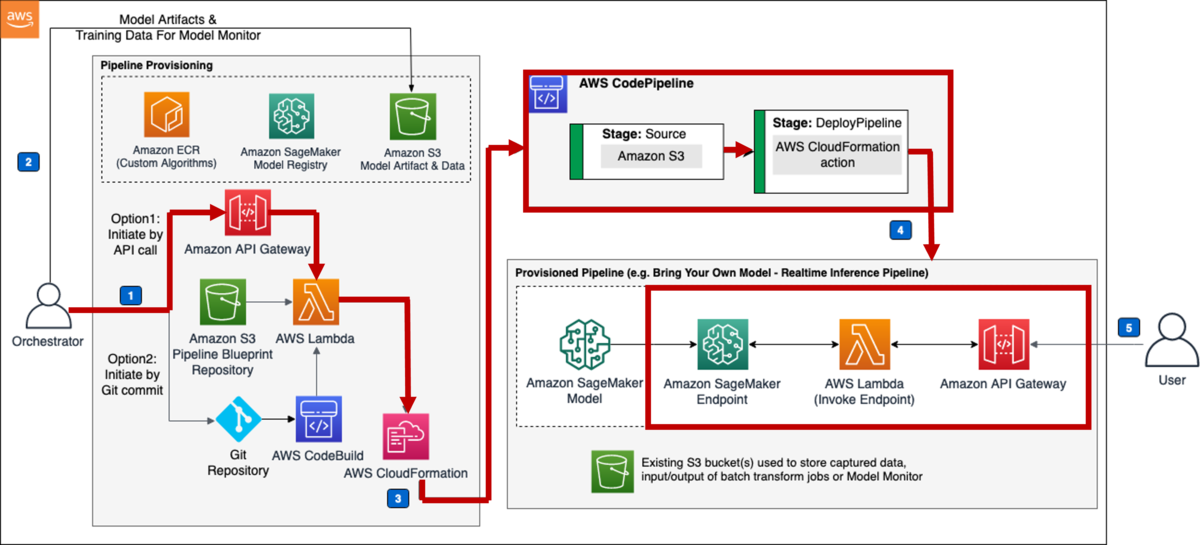
3. モニタリング用パイプラインのプロビジョニング
さきほど作成したエンドポイントのモニタリングを行うワークフローを実行し、モニタリング用のパイプラインをプロビジョニングします。エンドポイントにデプロイされたモデルに対し、ベースとなるデータセットを実行し、実際に飛んできている推論データとの統計情報を可視化することで、モデルがビジネスゴールを満たしているかどうかの指標を得ることができます。
EndPoint:/provisionpipeline
Method:POST
Body:
{ "pipeline_type" : "byom_data_quality_monitor", # 推論やテストデータの評価を行うパイプラインをプロビジョニング "model_name": ""my-model-name"", # モデル名(リソース作成時に命名として使用されます) "endpoint_name": "xgb-churn-prediction-endpoint", # 評価対象のエンドポイント名 "baseline_data": "path/to/data_with_header.csv", # S3に格納してある評価用データ(ヘッダー付きcsvファイル)へのパス "baseline_job_output_location": "<bucket-name>/<prefix>", # モデルデータ評価を行うジョブ結果を格納するS3へのパス "data_capture_location": "<bucket-name>/<prefix>", # エンドポイントへの推論結果のデータキャプチャを保管S3へのパス "monitoring_output_location": "<bucket-name>/<prefix>", # モニタリング結果のアウトプットを格納するS3へのパス "schedule_expression": "cron(0 * ? * * *)", # 評価ジョブ実行タイミングのスケジューリング "instance_type": "ml.m5.large", # 評価ジョブ実行で起動するインスタンスタイプ "instance_volume_size": "20", # 評価ジョブ実行で使用するボリュームサイズ "baseline_max_runtime_seconds": "3300", # 評価ジョブの起動時間上限 "monitor_max_runtime_seconds": "3300" # モニタリングジョブの起動時間上限 }
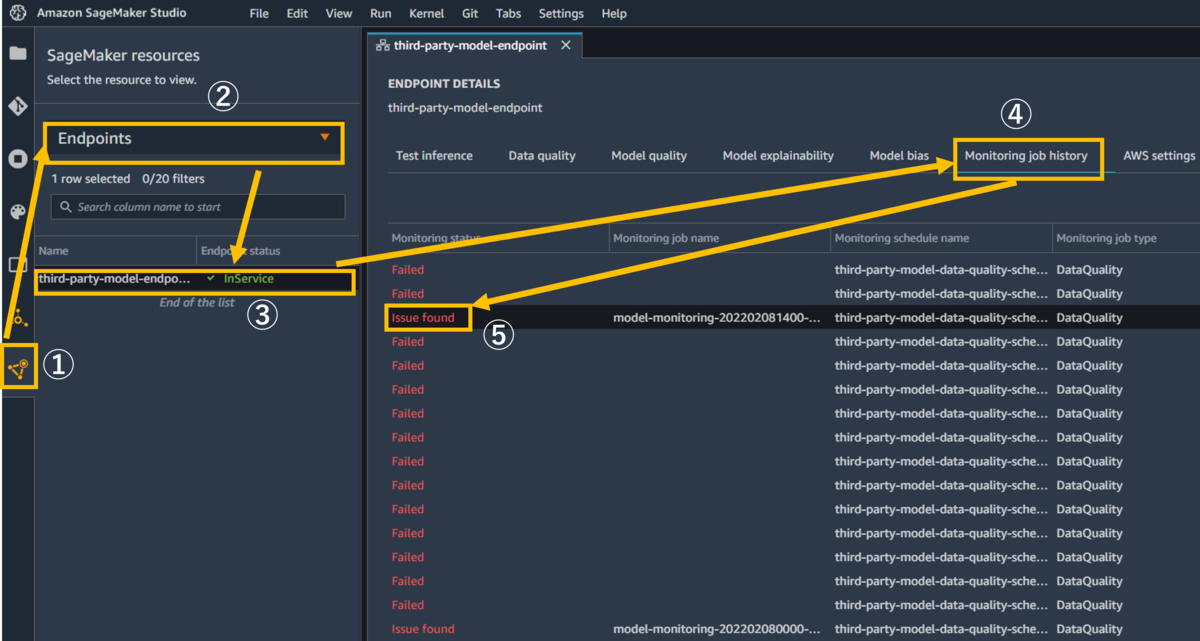
モニタリングの結果を確認します。 Sagemaker Studio左メニューから SageMaker resourcesを選択 >プルダウンからエンドポイントを選択 >エンドポイント名をダブルクリック >Monitoring job historyタブを選択 >「issue found」をダブルクリックして下さい。
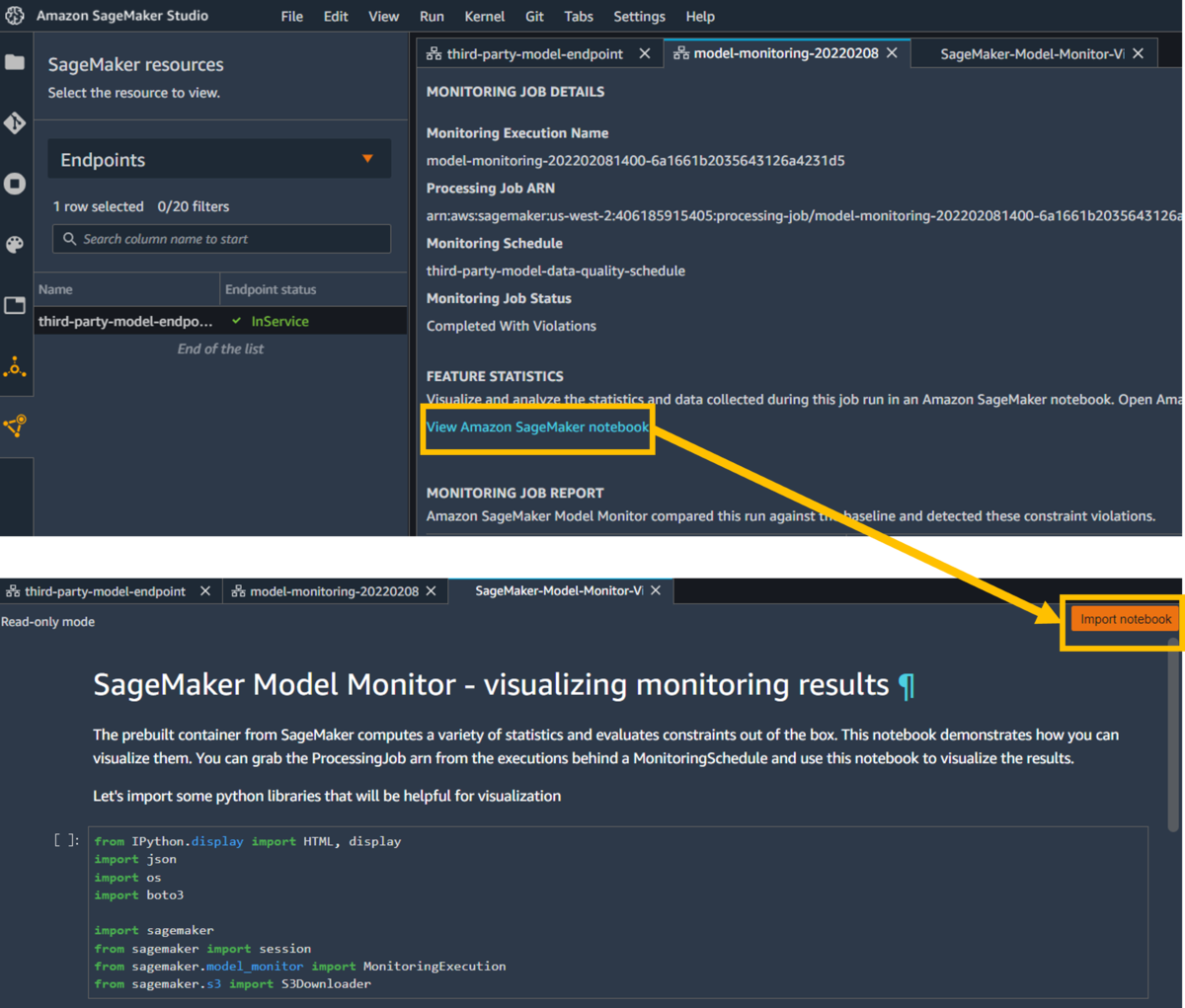
続いて、「View Amazon SageMaker notebook」リンクをクリック > 「Import notebook」ボタンをクリックすることで、モニタリング結果を可視化してくれるnotebookが実行できるようになりました。
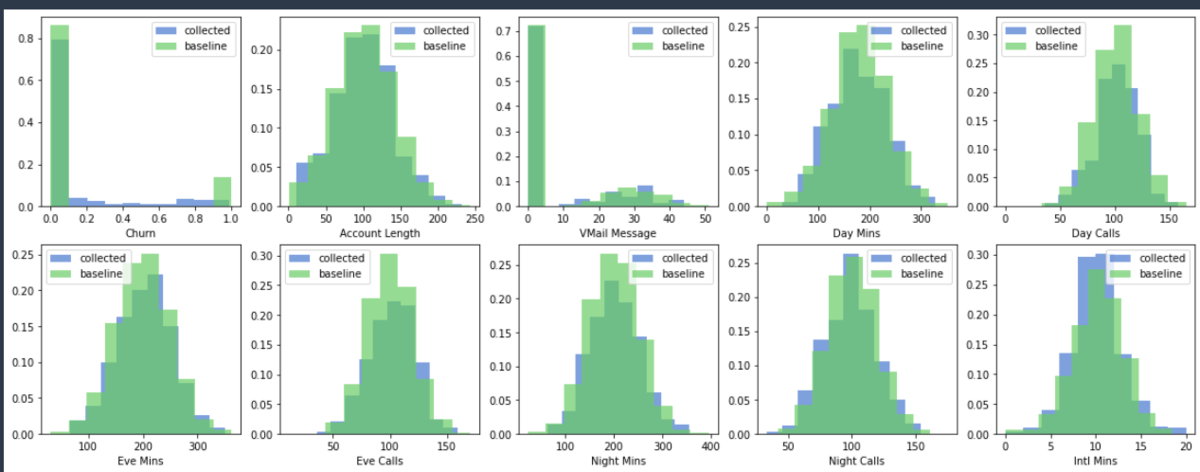
notebookを実行することで、モニタリング結果の可視化を行うことができました。グラフのところで、collectedが推論で飛んできているデータで、baselineが事前にベースとして用意していたデータです。データの差分や、偏り、傾向等が、感覚ではなく視覚的に確認できるのは嬉しいですね!

利用してみての所感
「AWS MLOps Workload Orchestrator」を利用してきましたが、学習したモデルを簡単にデプロイできたり、状態を可視化できたりと非常に便利でした。特に、モニタリングのワークフローでは、データセットやモデルの統計情報を可視化することで、モデルがビジネスゴールを満たしているかを確認することが容易にできるので、効果的にモデルを育てていくというライフサイクルを回すことができそうだと感じました。
後は、一般的なMLOPsだと、
- モデルの精度を評価(テスト)して、承認者が精度で問題ないことを確認した後、当該モデルをデプロイする
- 継続的にモデルの精度劣化等をモニタリングして、必要であれば再学習を行う
ということもよくやるみたいですね。
どこまで自動化・効率化していくのかは、プロジェクトの目的や規模などによって変わるとは思いますが、今回学んだことを活かして、自分達の組織やプロジェクトに合ったMLOPsというものを考えていきたいと思います。
それでは。
Acroquest Technologyでは、キャリア採用を行っています。
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。
Kaggle Grandmasterと話したいエンジニアWanted! - Acroquest Technology株式会社のデータサイエンティストの採用 - Wantedlywww.wantedly.com