皆さんこんにちは。@Ssk1029Takashiです。
この記事はElastic Stack (Elasticsearch) Advent Calendar 2019の13日目になります。
qiita.com
何か調べ物をしているとき、見つけた記事が古く使えないということが良くあります。
例えばElasticsearchのクエリを調べていたら、ver5時代の記事ですでに仕様が変わっていたりなど。。。
検索結果としては基本的には時系列が新しいものを優先して出してほしいことが多いです。
このように、検索システムでは基本的には新しい記事、なおかつ検索キーワードと関連度が高い記事を優先して出してほしいということがあります。
この時、単純に時系列でソートすると関連度を考慮できないため、検索スコアにいい感じに時系列情報を組み込む必要があります。
Elasticsearchでは、この問題をscript score queryを使って解決できます。
script score queryとは
Elasticsearch ver7から追加されたクエリで、scoreの値をpainless scriptで書くことができます。
www.elastic.co
例えば、以下のクエリで検索するとします。
GET /_search { "query" : { "script_score" : { "query" : { "match": { "message": "elasticsearch" } }, "script" : { "source" : "doc['likes'].value / 10 " } } } }
このクエリでは、各検索結果のscoreはlikeフィールドの値を10で割った値になります。
このように検索クエリの中で、scoreの値をカスタマイズできるのがscript score queryです。
script score queryで時系列を考慮するには
script score queryでは、いくつかデフォルトで使用できる関数があるのですが、今回はその中のdecay関数を使用します。
decay関数の簡単な説明
decay関数とは名前の通り、特定の値に基づいて検索スコアを減衰させる関数です。
decay関数は適用できるデータ型によって3種類に分けられます。
1. 数値に基づきスコアを減衰させる関数
2. 地理的な距離に基づきスコアを減衰させる関数
3. 時系列に基づきスコアを減衰させる関数
また、それぞれのdecay関数には減衰値の計算方法が3種類(線形、ガウス分布、正規分布)用意されています。
例えば、時系列に基づくdecay関数は以下の3つです。
1. decayDateLinear
2. decayDateExp
3. decayDateGauss
それぞれどのように値が減衰していくかのイメージが公式ドキュメントにあります。
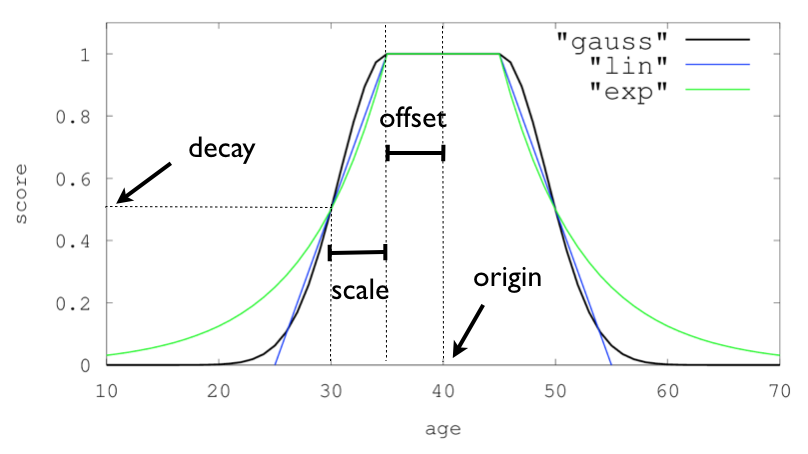
Function score query | Elasticsearch Reference [7.5] | Elastic
この中から、システム要件に合ったものを選びます。
実際のクエリは以下のような形になります。
{ "query": { "script_score": { "query": { "match_all": {} }, "script": { "source": "decayDateGauss(params.origin, params.scale, params.offset, params.decay, doc['timestamp'].value)", "params": { "origin": "2019-12-13T00:00:00Z", "scale": "60d", "offset": "0", "decay": 0.99 } } } } }
クエリ中で使用している引数は以下の4つになります。
origin: 減衰を計算する原点となる日時。この日時とドキュメントの日時がどれくらい離れているかでスコアが計算されます。
scale: 原点から距離を計算するときの単位。
offset: スコアを減衰させない範囲。
decay: どれくらいスコアを減衰させるか。
このようにscriptとして関数を呼び出すことで、scoreを調整することができます。
実際に試してみる。
データは以下の3つを投入します。
| timestamp | title | content |
|---|---|---|
| 2019-12-08 12:00:00 | Micrometerで取得したデータをKibanaで可視化してみました | Elastic Stackを活用しているAcroquestとしてはせっかくElasticsearchにも保存できるのにこれはもったいない…なら、うちで作るしかない!ということでMicrometer用のKibanaダッシュボードを作ってみました。 |
| 2018-12-20 12:00:00 | ElasticsearchのRanking Evaluation APIについて整理してみた | Ranking Evaluation APIは、検索クエリに対する検索結果の妥当性を評価するためのAPIです。Elasticsearchのバージョン6.2以降で利用することができます。 |
| 2018-05-08 12:00:00 | Elasticsearchの圧縮方式の比較 | Elasticsearchを使っているとストレージの使用量を節約したいと思う方は多いのではないでしょうか。Elasticsearchはデータを格納するときにデフォルトでLZ4という圧縮方式でデータ圧縮を行っていますが、実はLZ4よりも圧縮率の高いbest_compressionという圧縮方式を利用することもできます。 |
まずは、普通に検索してみます。
GET datetime_docs/_search { "query": { "multi_match": { "query": "elasticsearch", "fields": ["title", "content"] } } }
結果
{ "_index" : "datetime_docs", "_type" : "_doc", "_id" : "3", "_score" : 0.5543933, "_source" : { "title" : "Elasticsearchの圧縮方式の比較", "content" : """ Elasticsearchを使っているとストレージの使用量を節約したいと思う方は多いのではないでしょうか。 Elasticsearchはデータを格納するときにデフォルトでLZ4という圧縮方式でデータ圧縮を行っていますが、 実はLZ4よりも圧縮率の高いbest_compressionという圧縮方式を利用することもできます。 """, "timestamp" : "2018-05-08T12:00:00" } }, { "_index" : "datetime_docs", "_type" : "_doc", "_id" : "2", "_score" : 0.46122766, "_source" : { "title" : "ElasticsearchのRanking Evaluation APIについて整理してみた", "content" : " Ranking Evaluation APIは、検索クエリに対する検索結果の妥当性を評価するためのAPIです。\nElasticsearchのバージョン6.2以降で利用することができます。", "timestamp" : "2018-12-20T12:00:00" } }, { "_index" : "datetime_docs", "_type" : "_doc", "_id" : "1", "_score" : 0.150402, "_source" : { "title" : "Micrometerで取得したデータをKibanaで可視化してみました", "content" : " Elastic Stackを活用しているAcroquestとしてはせっかくElasticsearchにも保存できるのにこれはもったいない…なら、うちで作るしかない!\nということでMicrometer用のKibanaダッシュボードを作ってみました。", "timestamp" : "2019-12-08T12:00:00Z" } }
結果としては、キーワードが頻繁に出てくるドキュメントが上位に来ていますが、古いものが上位に来てしまっています。
これを、新しいドキュメントがより上位に来やすくします。
GET datetime_docs/_search { "query": { "script_score": { "query": { "multi_match": { "query": "elasticsearch", "fields": ["title","content"] } }, "script": { "source": "_score + decayDateGauss(params.origin, params.scale, params.offset, params.decay, doc['timestamp'].value)", "params": { "origin": "2019-12-13T00:00:00Z", "scale": "30d", "offset": "0", "decay": 0.99 } } } } }
script内の_score変数にはquery内で実行した単語検索によるスコアが入ります。
つまり、このクエリでは単語検索のスコア+時間で減衰したスコアの値を最終的なスコアにしています。
こちらの結果は以下のようになります。
{ "_index" : "datetime_docs", "_type" : "_doc", "_id" : "1", "_score" : 1.1501759, "_source" : { "title" : "Micrometerで取得したデータをKibanaで可視化してみました", "content" : " Elastic Stackを活用しているAcroquestとしてはせっかくElasticsearchにも保存できるのにこれはもったいない…なら、うちで作るしかない!\nということでMicrometer用のKibanaダッシュボードを作ってみました。", "timestamp" : "2019-12-08T12:00:00Z" } }, { "_index" : "datetime_docs", "_type" : "_doc", "_id" : "2", "_score" : 0.7012034, "_source" : { "title" : "ElasticsearchのRanking Evaluation APIについて整理してみた", "content" : " Ranking Evaluation APIは、検索クエリに対する検索結果の妥当性を評価するためのAPIです。\nElasticsearchのバージョン6.2以降で利用することができます。", "timestamp" : "2018-12-20T12:00:00" } }, { "_index" : "datetime_docs", "_type" : "_doc", "_id" : "3", "_score" : 0.57671785, "_source" : { "title" : "Elasticsearchの圧縮方式の比較", "content" : """ Elasticsearchを使っているとストレージの使用量を節約したいと思う方は多いのではないでしょうか。 Elasticsearchはデータを格納するときにデフォルトでLZ4という圧縮方式でデータ圧縮を行っていますが、 実はLZ4よりも圧縮率の高いbest_compressionという圧縮方式を利用することもできます。 """, "timestamp" : "2018-05-08T12:00:00" } }
新しいドキュメントを上位に出すことができました。
あまりにも新しいものが上位に来すぎてしまう場合には、scaleやdecayの値を調整することで、検索結果をチューニングすることができます。
まとめ
script score queryのdecay関数を使用して、文書の新しさを考慮した検索を簡単に実現しました。
クエリで簡単にスコアを調整できるのは、検索システムの運用上非常に便利ですね。
script score queryにはほかにも便利な関数がいくつか実装されているので、ぜひ活用してみてください。
それではまた。
明日は、mac_akibaさんの記事になります。ぜひお楽しみに!