こんにちは、アクロクエストテクノロジー株式会社でElastic Stackのコンサルティング業務を担当している吉岡です。本記事は、Elastic Stack (Elasticsearch) Advent Calendar 2020 の14日目の内容になります。
本記事では、2020/10/13~2020/10/15に開催されたElastic ON Globalで、個人的に最もエキサイティングに感じたセッション「Schema on read with runtime fields」を紹介します。
Elastic ON Global
www.elastic.co
Schema on read with runtime fields
セッション概要
Elasticsearch has always been fast, but required structuring and indexing your data up front. We're changing that with the introduction of runtime fields, which enable you to extract, calculate, and transform fields at query time. They can be defined after data is indexed or provided with your query, enabling new cost/storage/performance tradeoffs, and letting analysts gradually define fields over time.
- 発表動画
- 発表資料
www2.slideshare.net
セッションを読み解くための重要キーワード
Schema on Write と Schema on Read
- Schema on Write と Schema on Readの詳細にについては以下のブログが参考になります。
Runtime Field
これまで、Elasticsearchは主に「Schema on Write」のアプローチを採用してきました。検索/分析要件を先に決めて、Mappingを書いてからデータを投入する。スキーマレスと言いながら、最適な性能を得るには「Schema on Write」が必須でした。
Elasticsearch Ver.7.11から「Runtime Field」というデータ型が導入されます。一言で言うと、クエリ時にスクリプト(データ加工/抽出)を実行できるデータ型。スクリプトはMappingに記述(事前に定義)することも、クエリ自体に指定(実行時に定義)することも可能です。この「Runtime Field」と「非同期検索(Ver.7.7~)」を併用することで「Schema on Read」のユースケースが実現可能になります。
発表資料に関するコメント
以降はセッションの発表資料を抜粋しながらコメントしたいと思います。

- Schema on Write と Schema on Readの比較です。
- 左が従来の「Schema on Write」アプローチ。インデクシングする際にデータ加工を行うことで高速なクエリ/アグリゲーションを実現します。
- 右が新しくサポートする「Schema on Read」アプローチ。インデクシング時にデータ加工をせず、ほぼ生データをロードする形になるためインデクシングは高速です。データ加工は必要に応じてクエリ毎に指定すればOK。これは、投入するデータの詳細がよく分かっておらず、事前のスキーマ(Mapping)作成が困難なシーンで特に有効です。
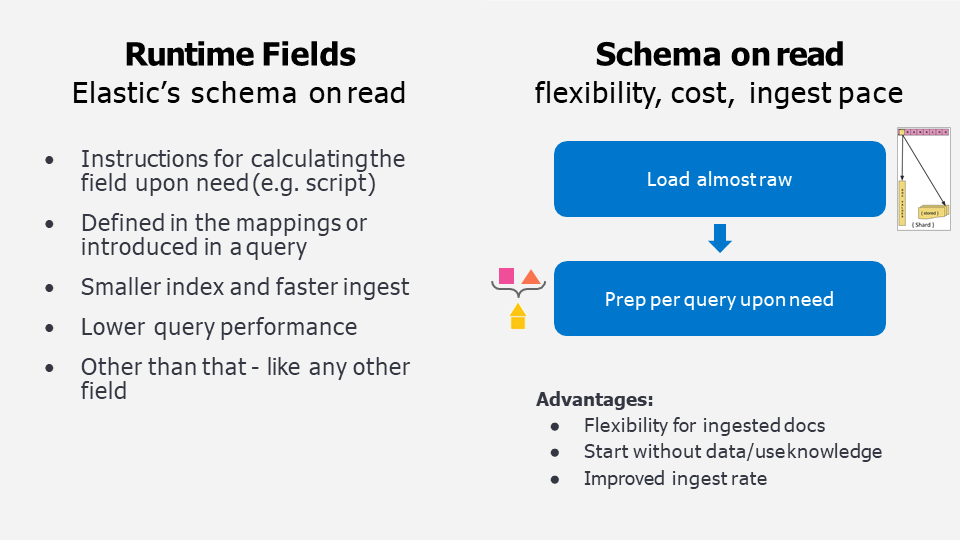
- Runtimeフィールドを利用した場合「Schema on Write」と比較してインデックスサイズ(消費ストレージ)は小さく、インデクシングは高速になります。ただし、クエリの速度は大きく下がります。(クエリ時にデータ加工するので当然です)

- Async search(非同期検索)での利用例。Rangeクエリで時間範囲を指定し、statusが「200」のドキュメントを検索しています。
- Rangeクエリでヒットする全ドキュメントに対して「Mappingのstatusフィールドに定義されたスクリプトを実行し動的にstatusの値を生成、statusが200のドキュメントに絞り込むクエリ。Schema on Writeアプローチでの時間感覚(検索は100ms以下が当たり前)からするとスロークエリそのものです。
- しかし、Schema on Readのユースケースはクエリの実行頻度が少ないシーンを想定しているので、非同期検索(デフォルトのタイムアウトは5日)でゆるやかに実行する形です。逆に、検索速度を求めるシーンでは、Runtimeフィールドではなく、通常のフィールドをSchema on Writeで使いましょう。

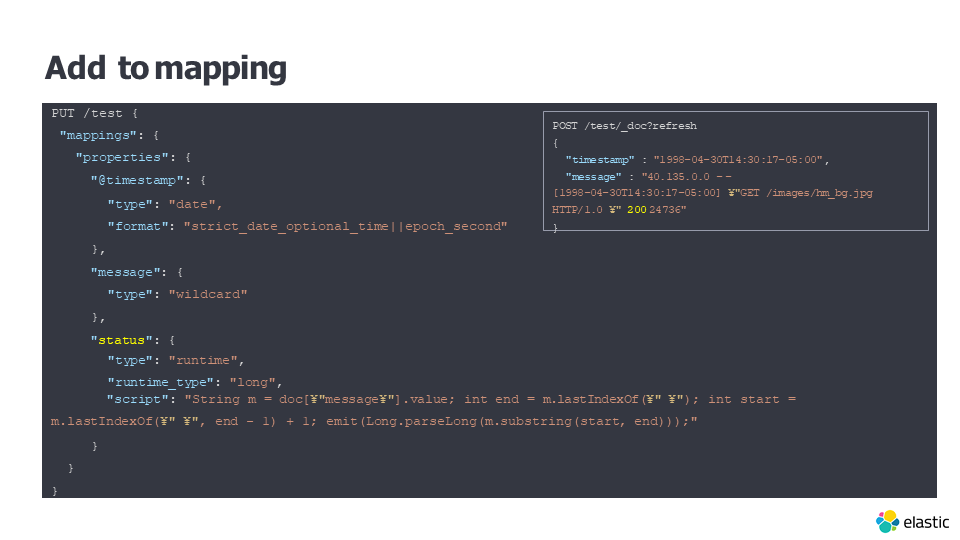
- クエリ時にスクリプトを定義する場合のサンプル。「runtime_mappings」というパラメータに、ipフィールドを生成するスクリプトを記述しています。
- MappingにRuntimeフィールドを定義していなくても、クエリで動的にフィールドを生成することができるのは非常に便利ですね。Schema on Writeではスキーマ設計/変更を管理者に集約する運用になると思いますが、Schema on Readでは各ユーザーがクエリを通して自由にスキーマ設計できることになります。

- 将来的にはPainless以外にもGrokやその他のエンリッチをサポートするようです。
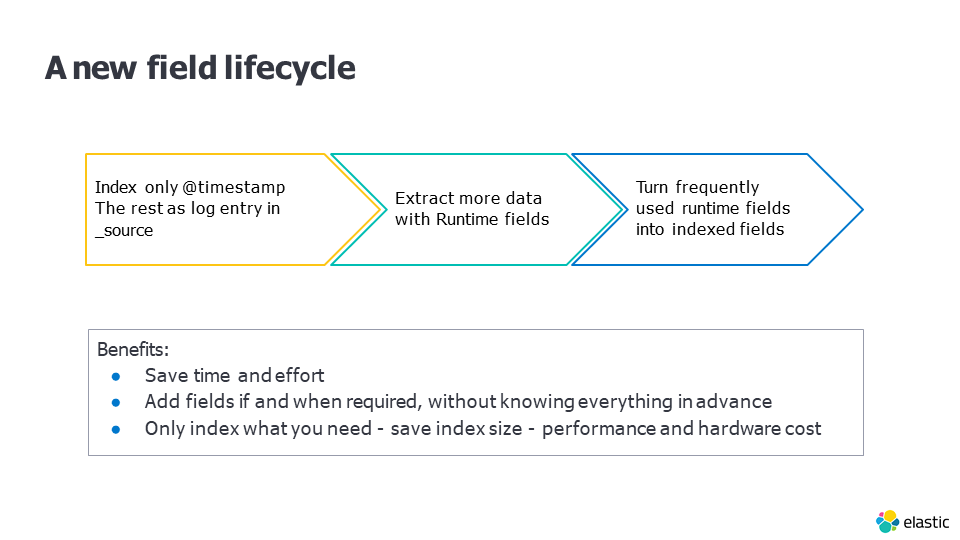
- Schema on Readにおけるフィールドライフサイクルは以下のようになります。
- インデクシング時に@timestampだけを抽出し、時刻以外をmessageフィールドに入れておく。
- データを抽出したい時にクエリに抽出スクリプトを記述し、必要なデータ取得する(Mappingの変更が不要)。Schema on Writeでデータ加工をしようとすると、その都度Reindexが必要ですが、Schema on Readでは、データ加工の試行錯誤をするのにReindexが不要です。
- 頻繁に利用するフィールドは、通常のフィールド(Indexed Field)に移行する。具体的には、インデックステンプレートにIndexed Fieldを追加、次に生成される(日単位インデックスであれば翌日、月単位インデックスであれば翌月)インデックスからはSchema on Write用フィールドになります。
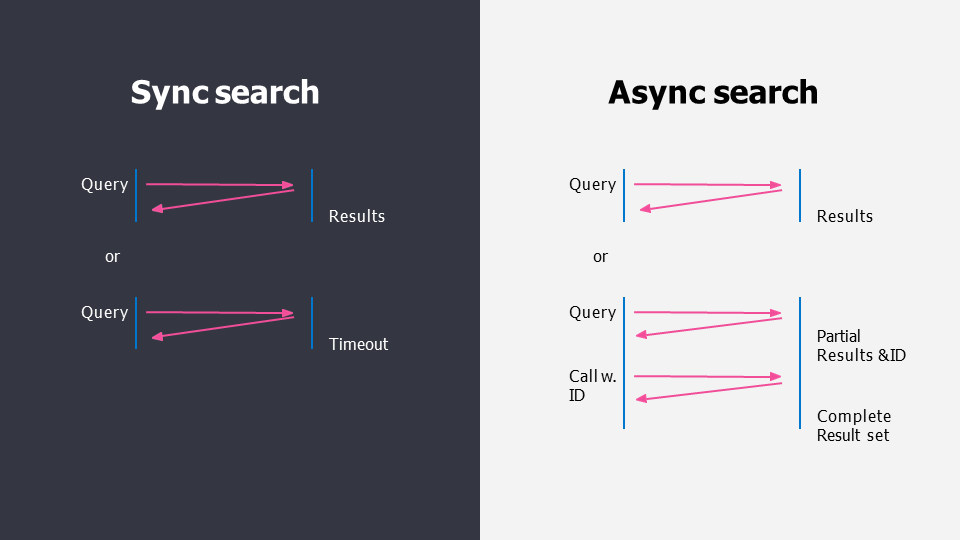
- 通常の検索(左)と非同期検索(右)の仕様の比較。非同期検索は長時間かかるクエリを実行するもので、クエリが完了する前でも、途中までの検索結果を取得することが可能です。

- まとめを意訳。
- Schema on Readの導入により、Elasticsearchのスキーマ設計が大きく変わります。従来のように一気にスキーマを完成させてからデータ投入するのではなく、スキーマを大雑把に決めてデータ投入をしてしまい、必要に応じてフィールドを作成し、徐々にスキーマを確定していくことになります。また各フィールドは、検索、可視化、アドホックな調査、バッチ処理など、コンテキスト毎に設計するのが主流になるでしょう。
Acroquest Technologyでは、キャリア採用を行っています。
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。【データ分析】
Kaggle Masterと働きたい尖ったエンジニアWanted! - Acroquest Technology株式会社のデータサイエンティストの求人 - Wantedlywww.wantedly.com