こんにちは、@shin0higuchiです😊
7/11~7/16に、情報検索のカンファレンスである ACM SIGIR 2021 がオンライン開催されました。
私も参加してきたので、概要や特に興味深かったセッションについてブログを書きます。
1. 概要
1. SIGIRとは
ACM(コンピュータ分野全般を対象とする国際学会)が主催するカンファレンスで、毎年一回開催されます。
ACMは毎年数多くのカンファレンスを主催しており、SIGIRは Special Interest Group on Information Retrieval の略で、毎年情報検索に関する様々な研究成果が寄せられます。
2. 今年のSIGIR
昨年のSIGIRは中国の西安で開催され、リモートでの参加が可能という形となっていましたが、
今年は完全オンラインということで、Underline / Zoom / Gather.Town などを駆使した催しとなっていました。
オンラインではありましたが、約1000人(46か国)が参加したようです。
Gather.Townは私自身初めて利用したのですが、
ポスターセッションなどもストレスなく回ることができてとても良いプラットフォームだと感じました。
仮想空間上を自由に歩き回ることができ、近くの人と会話したり、ポスターや企業ブースを回ったりと、かなり自由度が高かったです。
(~25人のスペースなら無料で作れるようなので、遊んでみるのも面白いかもしれません)
gather.town
Underlineでのセッション視聴も使いやすく快適でした。(オープニングセッションの様子)
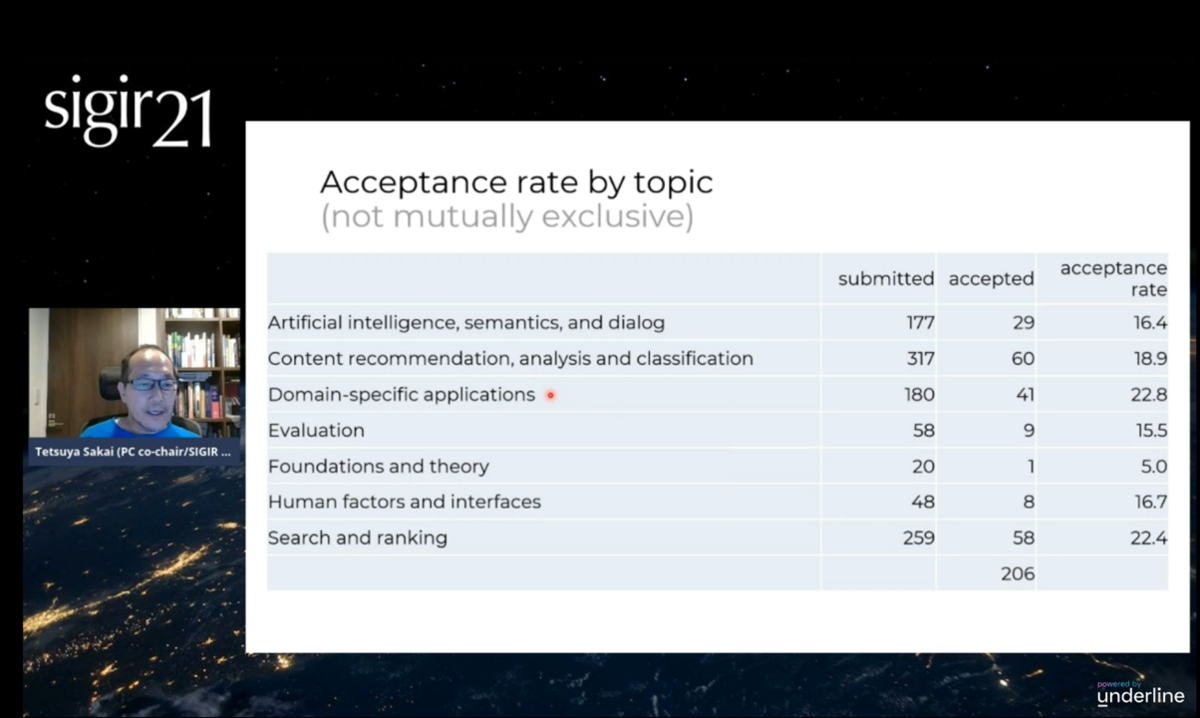
学会全体での論文傾向などはオープニングセッションで紹介されていました。
short paper なども含めると1410ものサブミッションがあり、382本が Accept されたそうです。
https://waseda.app.box.com/v/sigir2021opening
セッションのカテゴリは以下の通りで、
私は主に「Recommendation」、「Searching and ranking」、「Question answering」などを中心に聞いていました。

3. 昨年との傾向比較
今年のトピック一覧を見てみると、「Content recommendation, analysis and classification」「Search and ranking」などが多いことがわかります。
ちなみに、昨年のAccepted Papersのトピック分布はこちらです。昨年は圧倒的にRecommendationが多かったですが、この分野は引き続き研究が盛んであることがわかりますね。
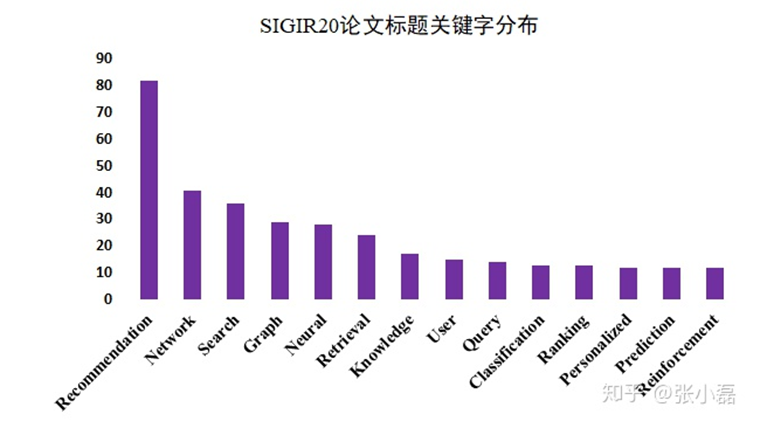
2. 興味深かったセッション
1. Reinforcement Learning from Reformulations in Conversational Question Answering over Knowledge Graphs (Magdalena Kaiser, Rishiraj Saha Roy, Gerhard Weikum)
Question Answering(以下QA)で、会話を通して強化学習するというトピック。
良い質問応答のシステムを作るためには、良い応答と悪い応答を適切に判断して学習させる必要があります。
システム側は常に「良い応答」だと思って応答を出力するので、良し悪しの判断は原則外部(質問者)からフィードバックされることが必要です。
一般的に、会話で期待通りの答えが返ってこない時、自分の質問を言い換えることがあると思いますが、
QAのシステム側から見れば、ユーザーが言い換え(Reformulation) を行った場合は、適切な回答ではなかったと考えることができます。
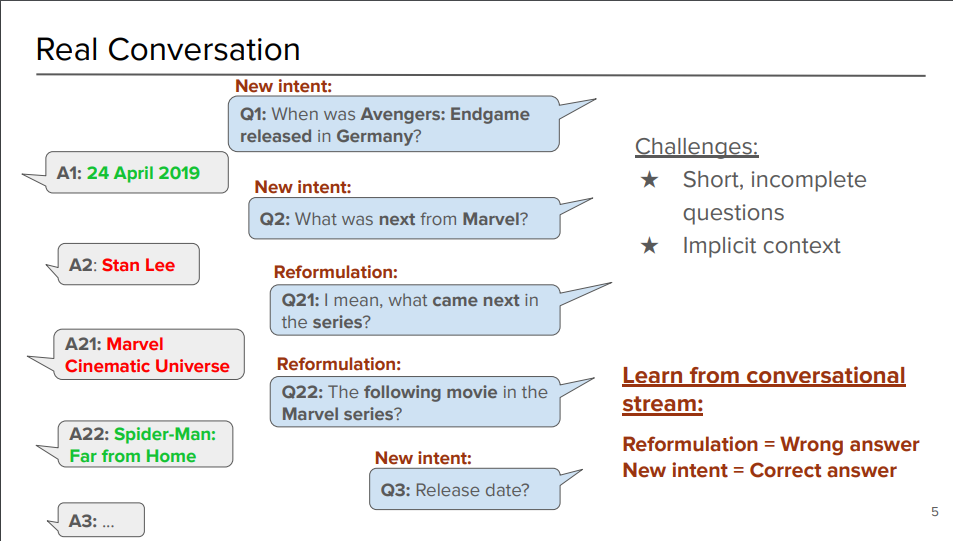
この研究では、入力される発話が「新たなインテント」「言い換え」のどちらであるのかを推論し、
言い換えであった場合は reward = -1、新たなインテントであった場合は reward = 1 とすることで、回答を生成する強化学習モデルにフィードバックすることが提案されています。
「インテント」というのは、目的・意図といった意味で、ここではユーザーが「何を訊きたいか」を意味します。
つまり、訊きたいことに対する適切な回答が得られた場合は次の質問(=新たなインテント)、得られなかった場合は言い換えをするという仮説に基づいた考えです。
Reformulationの判定にはファインチューニングされた BERTモデルを利用しているそうです。
モデル全体のアーキテクチャは下図のようになっています。
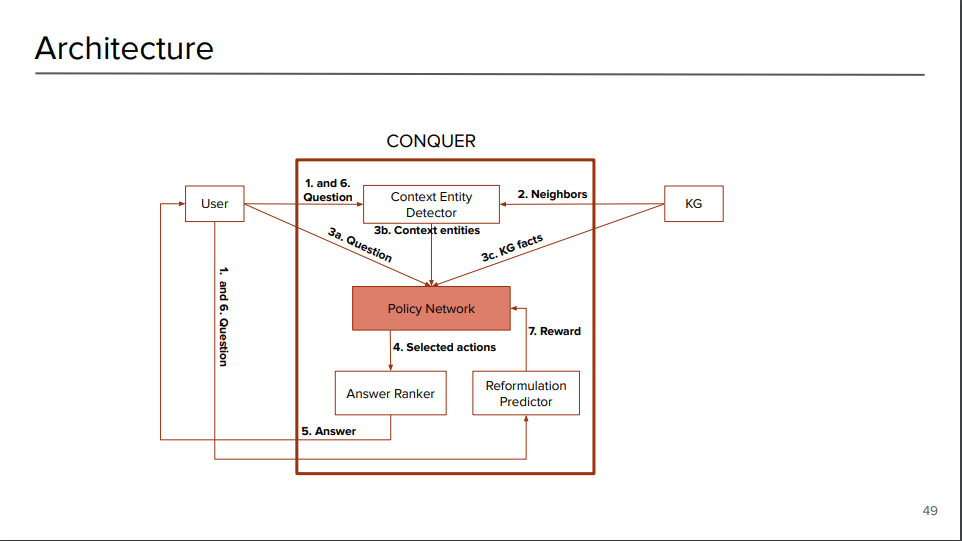
コードはこちらで公開されています。
github.com
QAは個人的にかなり興味のある分野だったのでためになりました。
2. Personalized News Recommendation with Knowledge-aware News Interactions (Tao Qi, Yongfeng Huang, Chuhan Wu, Fangzhao Wu)
ニュースのレコメンデーションに関するトピックでした。ニュースをレコメンドする際には、
- ユーザーの関心
- 推薦候補記事同士の関連性
を紐づけることでユーザーごとに適切な記事を推薦する必要があります。
一般的に、上記をそれぞれ別個のモデルで学習し、組み合わせる手法が多いのですが、
ユーザーの関心(≒クリックや検索の傾向)と、推薦候補の記事傾向を別々に学習すると、適切なマッチングが難しいという問題があります。
この研究ではこれらを統合的に学習することで、精度を改善する手法が提案されています。
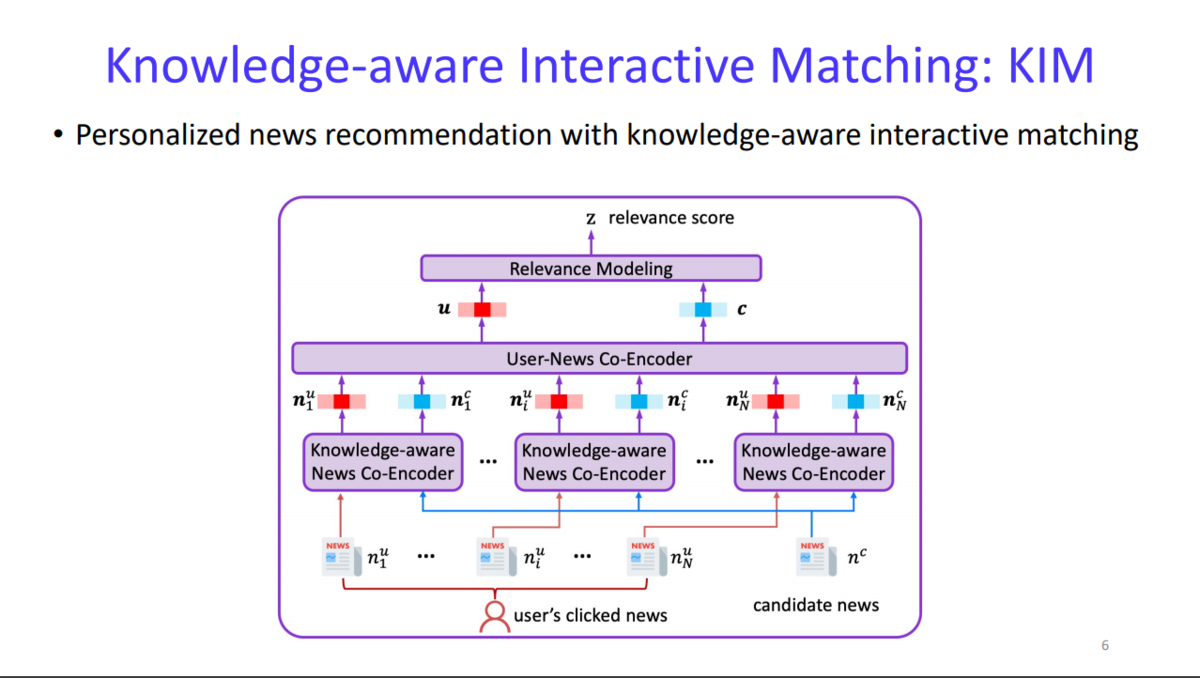
論文はこちら:arxiv.org
3. Meaningful Answer Generation of E-Commerce Question-Answering (Shen Gao)
E-Commerceにおける質問応答システムに関する発表でした。
「この商品は辛いですか?」といったような、商品に関する質問に対して応答を自動生成するシステムがテーマです。
応答は基本的にユーザーのレビューをもとに生成するのですが、中には間違った情報が含まれていたり、レビュアー間で観点が異なっていたりという問題があります。(たとえば、ほとんどの人が「辛くない」と言っている中で、ひとりだけ「とても辛い」とレビューしている場合など)
データソースに誤った情報や関係のない情報が混ざっている場合に、それに引っ張られず適切な応答を返すのは難しいだけに、勉強になりました。

この研究では、レビューを事前にクラスタリングし、それぞれについて回答を推論してから統合する形を取っています。
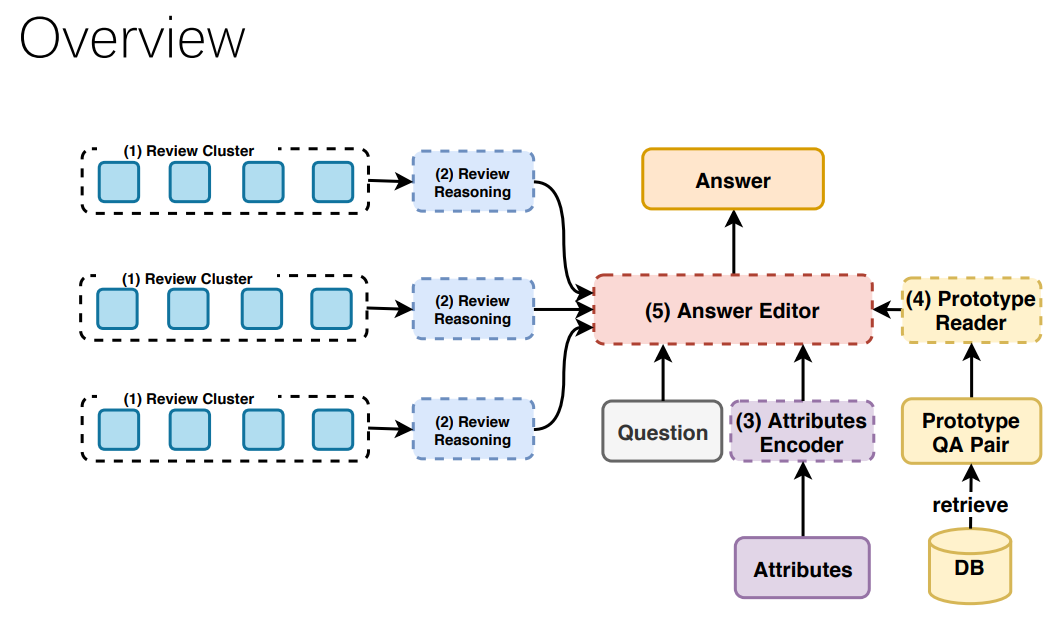
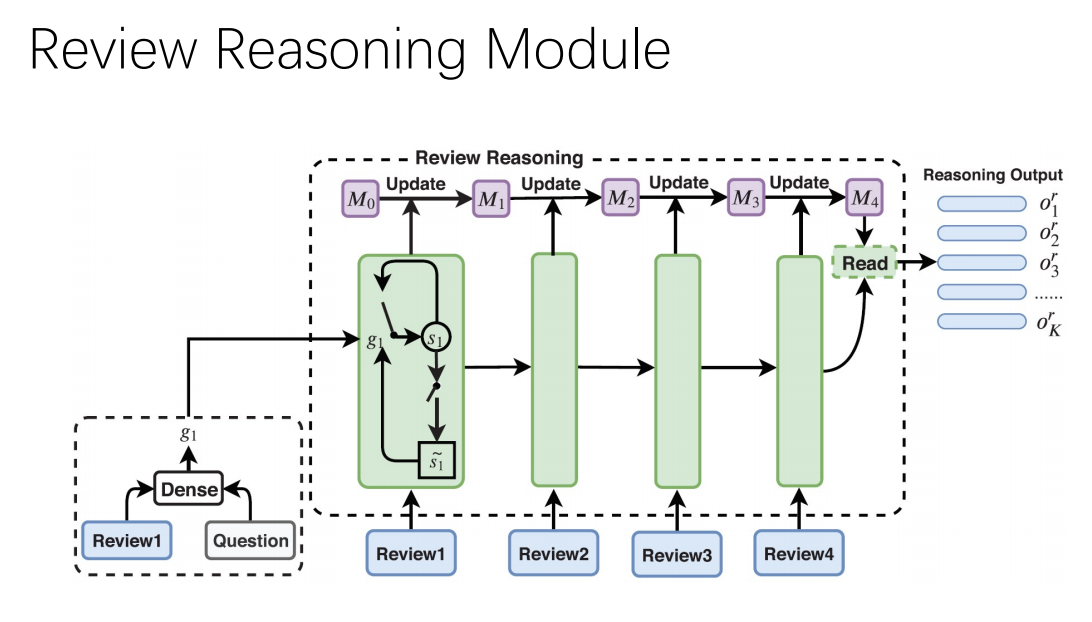
また、クラスタ毎の推論部分は以下のような構成を取っており、これによって少数派の間違った情報から影響を受けにくくなるようです。
4. その他
今回のAwardは以下の通りでした
- Best Short Paper: Contextualized Offline Relevance Weighting for Efficient and Effective Neural Retrieval by Xuanang Chen, Ben He, Kai Hui, Yiran Wang, Le Sun and Yingfei Sun
- Best Student Paper: Dynamic Modality Interaction Modeling for Image-Text Retrieval by Leigang Qu, Meng Liu, Jianlong Wu, Zan Gao and Liqiang Nie
- Best Paper: Computationally Efficient Optimization of Plackett-Luce Ranking Models for Relevance and Fairness by Harrie Oosterhuis
- SIGIR Test of Time Award: Exploiting geographical influence for collaborative point-of-interest recommendation by Mao Ye, Peifeng Yin, Wang-Chien Lee, Dik-Lun Lee, SIGIR 2011
興味のあるかたは是非読んでみてください。
3. 最後に
上記で挙げた以外にも、沢山の面白いセッションがあり、非常に良い刺激を貰えた一週間でした。
運営の皆様、発表者の皆様お疲れさまでした。
以上となります。お読みいただきありがとうございました。
Acroquest Technologyでは、キャリア採用を行っています。
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。
Kaggle Masterと働きたい尖ったエンジニアWanted! - Acroquest Technology株式会社のデータサイエンティストの求人 - Wantedlywww.wantedly.com