皆さんこんにちは。データサイエンティストチームYAMALEXのSsk1029Takashiです。
YAMALEXは Acroquest 社内で発足した、会社の未来の技術を創る、機械学習がメインテーマのデータサイエンスチームです。
Microsoft Buildを経て、AzureにもGPTを利用したサービスが数多く発表されており、LLMをサービスとして利用できる使い方増えていてワクワクしますね。
今回と次回の記事を通して、その中のサービスの一つであるAzure Machine Learning Prompt Flowというサービスを使ってRAG(Retrieval Augmented Generation)の回答を自動評価するシステムを試してみます。
この記事では、まずはPrompt Flowを使って手動で回答を評価してみるところまでを検証します。
※RAGとは事前に知識を検索エンジンなどに蓄積して置き、その中から抽出した情報をコンテキストとして質問に回答する手法のことを指します。
目次
Prompt Flowとは
Prompt FlowとはAzure Machine Learningに追加された機能で、LLMを活用したアプリケーションを開発するためのツールです。
Flowと書いている通り、以下の画像のようにタスクを矢印でつないでフローを作成します。

各タスクにはLLMを使ったテキスト生成やプロンプト作成、Pythonの実行が可能で、それらを組み合わせて全体のフローを作成します。
Pythonで自分が実装したスクリプトを動かせるので、かなり自由度は高いです。
今回やること
今回はこのPrompt Flowを使って、RAGシステムの回答を評価するフローを組んでみます。
RAGを運用していると、期待していない回答に出くわすことも多くありますが、どれくらい期待する回答を返しているかは運用の中で評価が必要です。
そのためには以下のことをシステムとして実行する必要があります。
- 会話ごとに質問・コンテキスト・回答をログとして保存する
- 保存したログをもとに、質問・コンテキストから回答がどれくらい妥当なものが返せているか評価する。
システムとしては下図のような構成になり、そのうち赤の点線で囲っている範囲が今回お試しで検証する範囲になります。

Prompt Flowでシステムの回答を評価する
ギャラリーのサンプルを動かす
Prompt Flowは作成時にいくつか標準で使えるサンプルを用意しています。
その中にはGPTの回答を評価するためのサンプルもあるので、今回はそれを活用して検証します。
サンプルは以下のように新規フロー作成画面「ギャラリーから作成する」から選ぶことができます。

今回はこの中の、「QnA Relevance Evaluation」を利用します。
該当のフローを選択すると以下のようにフローの編集画面に移動します。

中身を簡単に見てみると以下の構成要素になっています。
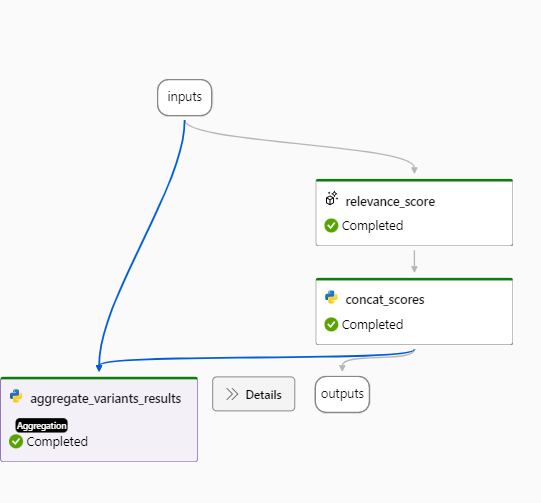
右のフロー図を見ると全体としては、以下の流れで処理されていることが分かります。
- 入力を受け取る
- relevance_scoreではGPTを使って評価値を生成する
- relevance_scoreで生成した評価値をconcat_scoreでPythonスクリプトから出力と集計に流すための成形を実施する
- concat_scoreで成形した出力を、aggregate_variants_resultsが受け取ってPythonスクリプトから集計する
それぞれの構成要素は以下のような設定になっています。
- フロー全体の入力には質問・コンテキスト・回答・行番号・候補IDを受け取る

- 入力を受け取ってGPTを使ってどれくらい回答が質問とコンテキストに関連があるかを生成する
プロンプトの内容としては、入力とコンテキスト、出力がどれくらい関連があるかを1~5の値で評価するプロンプトになっています。

- GPTの出力を後続が集計しやすいように成形する

- 評価結果の集計を出力する

上記の4つの構成要素をつなぎ合わせたフローになっています。
ためしに以下の例で動かしてみましょう
- 質問: Azure Openai Service上で利用できるGPT-4の最新版のモデルのバージョンは?
- コンテキスト: Azure OpenAI Serivceで利用できるGPT-4のバージョンは0301, 0613があり、自動でアップデートする設定が使用可能です。
- 回答: 最新版のモデルのバージョンは0613です。
これは質問とコンテキストから期待する回答を取得できているので、スコアとしては5が取れることを期待したいです。
実際に動かして成功すると、右側の図で最後のAggregationのタスクがCompletedになります。
そして最後の出力を見ると以下のJSONが出力されています。
[
{
"system_metrics": {
"duration": 0.006102
},
"output": {
"variant_0": {
"gpt_relevance": 5,
"gpt_relevance_pass_rate": 100
}
}
}
]上記でいうgpt_relevanceというのがGPTを使って評価した回答の関連度で、5が最高値なので期待通りの値を取得できていそうです。
まとめ
この前半記事では、RAGシステムの質問・コンテキスト・回答をもとにPrompt Flowを使って簡単に評価値を取得しました。
ここまで一切コーディングせずに動かせるのはありがたいですね。
ただし、このままだといちいち各回答に対して手動でフローを実行するのはあまりに効率が悪いです。
なので、次回の記事ではPrompt Flowの「一括テスト」という機能を使ってファイルから複数回答を自動で評価してみます。
それではまた。
「小企業が実践したノウハウを展開!中小企業でChatGPTどう活かすのか?」 近日開催します!
