こんにちは。タイの気温がほぼ日本と同じでちょっとげんなりしている@Ssk1029Takashiです。
私は自然言語処理の国際学会であるACL2024に参加するため、タイのバンコクに来ています。
2024.aclweb.org
今アクロクエストではRAGを用いたプロダクトを開発しており、LLMを含むNLPの最新の動向を追うためにACLに参加することにしました。
本記事ではTutorialから本会議2日目までの内容を記載していきます。
ACLとは
ACLとは正式名称「Association for Computational Linguistics」という学会で、自然言語処理を扱うトップカンファレンスとして知られています。
毎年、世界各地でカンファレンスが開催されており、今年はタイのバンコクでの開催となりました。

初日(Tutorial)
初日は本会議ではなく、Tutorialから開始でした。
講習会のような形で、言語処理系の特定の技術について担当する人が説明してくれます。

私は以下2つのTutorialに参加しました。
- Automatic and Human-AI Interactive Text Generation
- Watermarking for Large Language Model
特に「Watermark for Large Language Model」の内容が印象に残ったので、少しだけ紹介します。
Watermarking for Large Language Model
このTutorialでは「Text Watermark」と「Model Watermark」という2つのWatermarkをメインで紹介されていました。
この章では「Text Watermark」についてメインで紹介します。
Watermarkというのは日本語で言うと「透かし」になりますが、LLMが生成したテキストに対して透かしのような概念を取り入れられないかという取り組みになります。
Text WatermarkはLLMで生成された文章かを判別できるように、LLMによる誤報やデマを防ぐための技術として注目されている技術です。
ベーシックは手法として「Green-Red Watermark」というものが紹介されていました。
この手法では、ランダムに生成されたTokenをLLMが選びやすくなるように、モデルの後段で処理を入れることで、生成されたテキストがWatermarkを入れて生成されたものかを判別するというものです。

上記画像はText Watermarkを入れた場合に、LLMの出力からWatermarkありなしを判定できている様子です。
この手法を使うことで、LLMから生成した文章を判定して追跡することが可能になるとのことです。
LLMが出てきたからこその技術という感じがあり、面白いですね。
上記のようなベースの手法を紹介した後、後続のWatermarkの手法や評価方法について解説があり、これまでの研究を抑えられる面白いTutorialでした。
2日目(本会議初日)
2日目から本会議が始まり、Opening CelemonyとKeynoteから始まりました。
Opening Celemony
今年のカンファレンスの概要や採択の傾向などが説明されました。
論文の投稿数は年々増えている傾向にありますが、やはりLLMが出た影響からか去年が一番跳ねていますね。
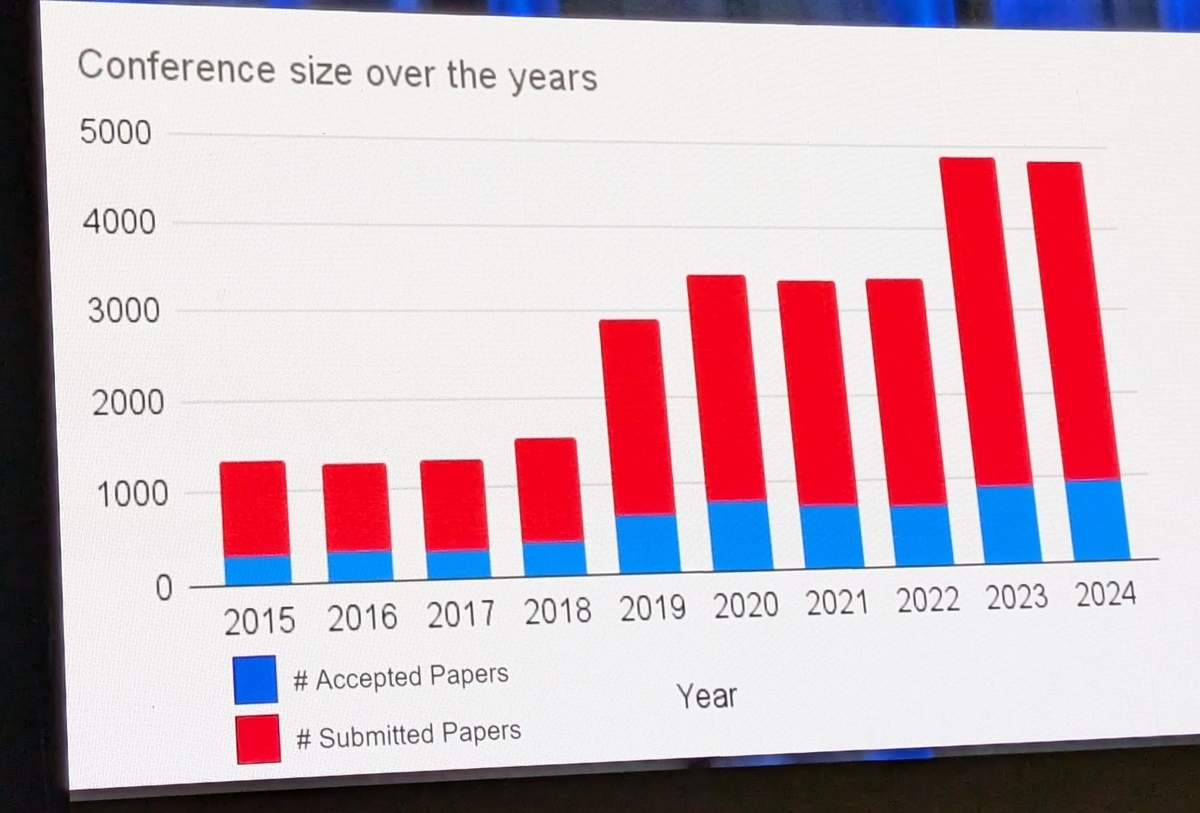
採択率は21.3%とのことで、全体が多い分下がってはいるそうです。
分野として、Resources and EvaluationやEfficient/Low-Resource Methods for NLPのトラックでの投稿が増えているとのことなので、LLMを使う・評価する方向での研究が増えた結果のようです。
Keynote1
最初のKeynoteは「Does In-Context-Learning Offer the Best Tradeoff in Accuracy, Robustness, and Efficiency for Model Adaptation?」というIn-Context-Learningについて扱った発表でした。
元々、In-Context-Learningは複数のモデルを組み合わせるなど複雑な学習、推論が必要なタスクだったが、今のGPT相当のLLMが事前学習+Few Shotで様々なタスクに簡単に適用するようになったのはなぜか、ということを様々な面で検証しようという内容でした。
自分自身、LLMを使っているとなぜそれができる?と感じる場面が多いので、それの一部を解き明かすための取り組みは興味深いものでした。
Session
2日目からは本会議に入るので、Keynoteの後は各分野に分かれてSession がありました。
Question AnsweringとInformation Retrieval and Text Miningを中心に聞きましたが、面白い論文ばかりで楽しかったです。
当記事では後述で3日目と合わせてまとめて、いくつか特に興味を引かれた論文を紹介しようと思います。
3日目(本会議2日目)
本会議2日目も最初はKeynoteから始まりました。
また、今日はSession自体は少なめになり、代わりに夜にSocial Galaというイベントが開かれました。
Keynote 2
2つ目のKeynoteは「Can LLMs Reason and Plan?」になります。
題名の通り、LLMでPlanningタスクをどのように扱えるかということについてになります。
今でもGPT−4などで、CoTをベースにした、Planninはいくつかサンプルなど紹介されていますが、Keynoteの中ではLLM単体では精度の高いPlanningはまだできない、と言われていました。
ただし、LLMをToolのように活用してフレームワークを組めば改善できるということも行っており、いくつかの改善手法の例を出してくれていました。
完全な自動化は難しく、人手を補助する役割などで、使うことが必要とのことでした。
Planningがそこまで精度良くないのは自分で試している中でも3,4ステップになると期待通りの動きをしてくれることが難しいのはまだまだある実感にもあっており、実際の実験結果を見れたのはよかったです。

気になった論文
まず前半までで気になった論文をいくつか挙げていきます。
自分が普段RAGを使ったプロダクトを開発していることもあり、Question AnsweringやGenerationなどのカテゴリをメインで見ていました。
A Chain-of-Thought Is as Strong as Its Weakest Link: A Benchmark for Verifiers of Reasoning Chains
arxiv.org
この論文では、Chain-of-Thoughtタスクの性能を測るためのベンチマークを提案する内容でした。
この論文ではCoTでのエラー要因はFactual Error(事実の間違い)とLogical Error(論理の間違い)があるから、その2点を計れるベンチマークを作ったとのことです。
実際に質問を入力にして、CoTのステップを出力し、各ステップごとに事実、論理的に正しいかを測ることでCoT性能を計るというベンチマークです。
アノテーションツールなどを作ってラベリング作業をして、約900個の質問に対して、CoTのステップとそれに対するラベル付を実施したそうです。
結果として、CoTでは間違いがちな事実的な正しさも含めて確認できるベンチマークが作れたようです。
CoTはLLMが出てきてから認識されたタスクであり、まだ手法や妥当性自体も研究されている所ですが、このようにベンチマークが出てくるとさらに普遍的な評価が進むので、今後の広がり方に期待ですね。
D2LLM: Decomposed and Distilled Large Language Models for Semantic Search
arxiv.org
この論文ではSemantic Searchに注目して、既存の手法の問題点を解決するためのLLMを使った手法を提案していました。
Semantic Searchについては既存では、SentenceBERTのようなbi-encoderを使った方式と主にGPTを使うcross-encoderの方式がありますが、bi-encoderは高速な代わりに精度に問題があり、cross-encoderは逆に高精度な代わりに速度に問題があるなど、一長一短あるという状態でした。
この論文ではLLMの出力を「蒸留」のような形でより軽量なモデルに教え込むことで、bi-encoderよりも高精度かつ、cross-encoderよりも高速なSemantic Searchが可能になったとのことです。
LLMの出力からSemantic Searchに必要な要素をLossとして計算することで、学習させる手法が面白く、実際より既存手法よりも効果的な結果が出ているのもすごかったです。
今はベクトル検索と合わせてリランクでSemantic Searchもよく活用されるので、これからさらに研究が進んで活用幅が広がりそうな内容でした。
DRAGIN: Dynamic Retrieval Augmented Generation based on the Real-time Information Needs of Large Language Models
この論文では、既存のRAGとは異なるDynamic RAGという手法を提案し、実現性などを検証したものになります。
既存のRAGは会話を始める時に、ユーザーの入力を元に関連するKnowledgeを検索し、その後の回答に使用することが一般的です。
ただし、この論文の著者は長文かつ複雑な文章を出力するようなタスクでは、出力中に外部データを参照する必要があるのではないかという主張のようです。
例えば、「アルゼンチンのワールドカップ優勝について長いコメントを書いて」と指示した時に、LLMが何か名言のようなものを出力したとすると、それを誰が言ったのかということを追加の知識を取得して出力する必要があります。
このように、出力過程で知識の検索が必要なタイミングを検知したい というのが、この論文の目的で、そのために DRAGAINというフレームワークを提案していました。
ざっくりいうと、検索が必要そうなTokenを検知できるようにという仕組みでしたが、 実際の実験では いくつか必要なタイミングで検索し、LLMのハルシネーションを抑えらるなどに活用できたとのことでした。
自分もRAGを使ったプロダクトを開発している中で、出力から検索するタイミングを検知するというのは、自分にはなかった発想で面白いなと思いました。
まとめ
ACL2024の前半までの参加記事でした。
明日からは本会議最終日とWorkshopがあるので、まだまだ楽しんでいきます。
それではまた。
Acroquest Technologyでは、キャリア採用を行っています。
- Azure OpenAI/Amazon Bedrock等を使った生成AIソリューションの開発
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- マイクロサービス、DevOps、最新のOSSやクラウドサービスを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。