こんにちは、クラウドエンジニアの青山です。
最近、何か調べたいときには、通常の検索エンジンではなく、生成AIに聞くことが習慣になってきています。
調べたいことが分かりやすく得られるので、最近の生成AIの発展には、驚くばかりです。
とはいえ、単純な検索ではなく、関係するような情報をいろいろ調べたりするのは、生成AIを使っても時間がかかりますよね。
そこで有用なのが、ユーザーの質問に対して、より広く深く考察しながら、回答をしてくれる「DeepResearch」だと思います。
いろいろな生成AIサービスで、この機能が登場してきていますが、今回この「DeepResearch」の機能を、Difyを使って実現したいと思います。
1. 概要
DeepResearchとは
DeepResearchとは、単なるキーワード検索にとどまらず、検索結果をもとに次に必要な情報を段階的に掘り下げ、自動的かつ包括的な調査を実現するプロセスです。
OpenAIが2025年2月に発表したChatGPTに統合された高度なAIエージェントであり、複雑な調査タスクを効率的に自動化することを目的としています。
人間が数時間かけて行うインターネット上の大量の情報源から関連データを収集し、分析・統合して包括的なレポートを作成するというタスクを数十分で達成するということで注目を集めました。
2. Dify ワークフローを使ったDeepResearchの実現
DifyではDeepResearchのテンプレートが用意されています。
構築方法についてはDify公式ブログの「DeepResearch: Building a Research Automation App with Dify」の記事を参照してください。
このDeepResearchのテンプレートは、日本人の岸田崇史さん(https://note.com/conaxam)が作成されたものが、Dify公式のテンプレートとして採用されたもののようです。
dify.ai
ワークフローの説明
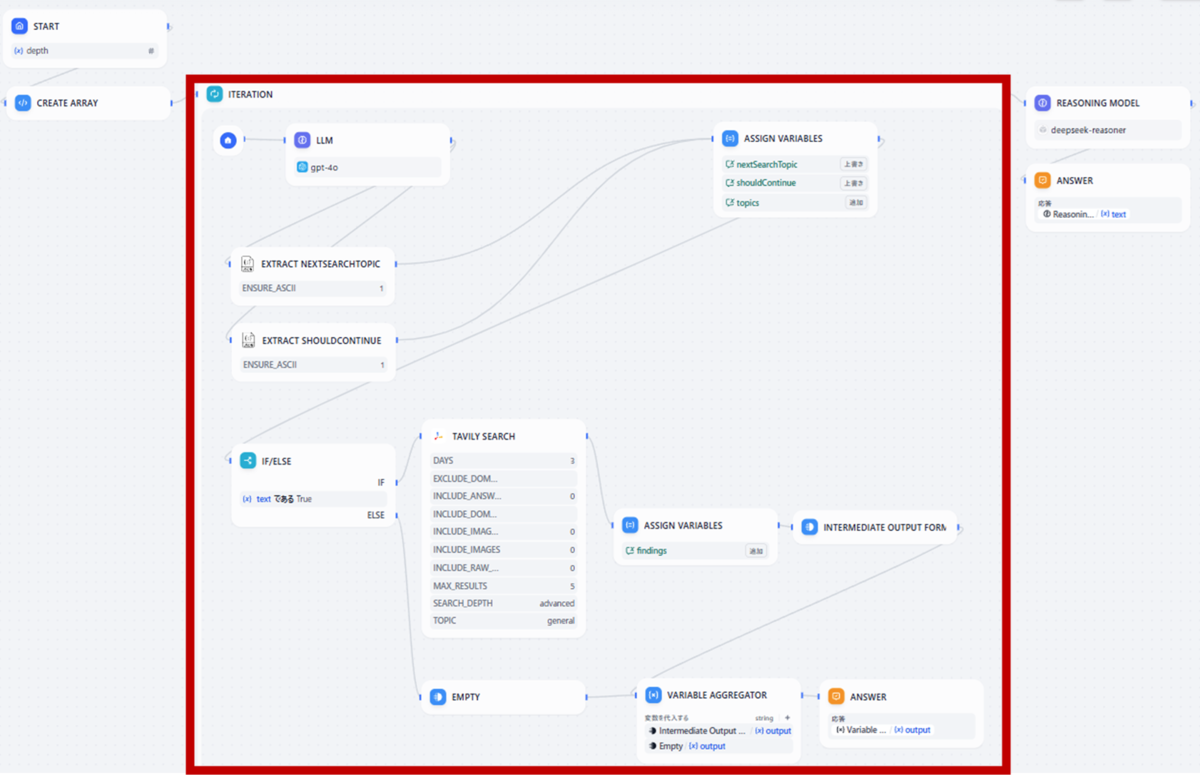
こちらがテンプレートを読み込んだワークフローになります。
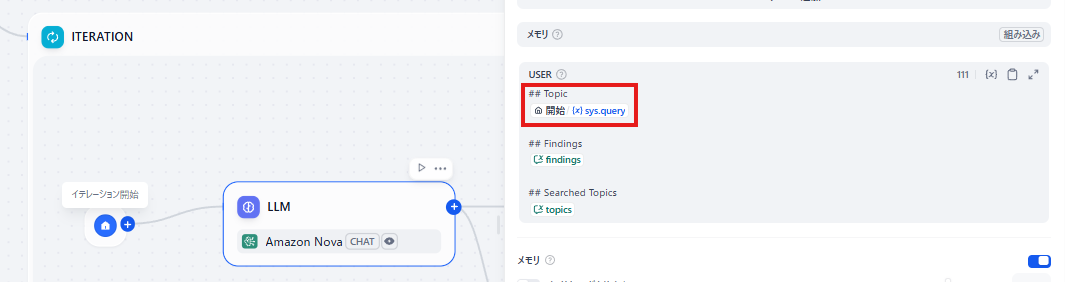
DeepResearch を再現しているコアな部分は、赤枠で囲ったイテレーションブロックです。
ユーザーの入力を基に、LLMノードで最初に設定した検索キーワードを出発点として、AIが新たな検索トピックを次々と生成し、自動で連続的な調査を実施します。
この仕組みにより、手動では膨大な時間がかかる多面的かつ深層的なリサーチを自動化できます。
このイテレーションを、STARTノードで指定した回数もしくはLLMノードで調査が不要と判定されるまで繰り返します。
本記事での変更点としては、LLMブロックのAIモデルを以下のように変更しました。
| ブロック名 | 説明 | LLM |
| LLM | 検索トピックを生成 | Nova Pro |
| Reasoning Model | トピックに関する包括的な分析を行う | Claude 3.7 Sonnet |

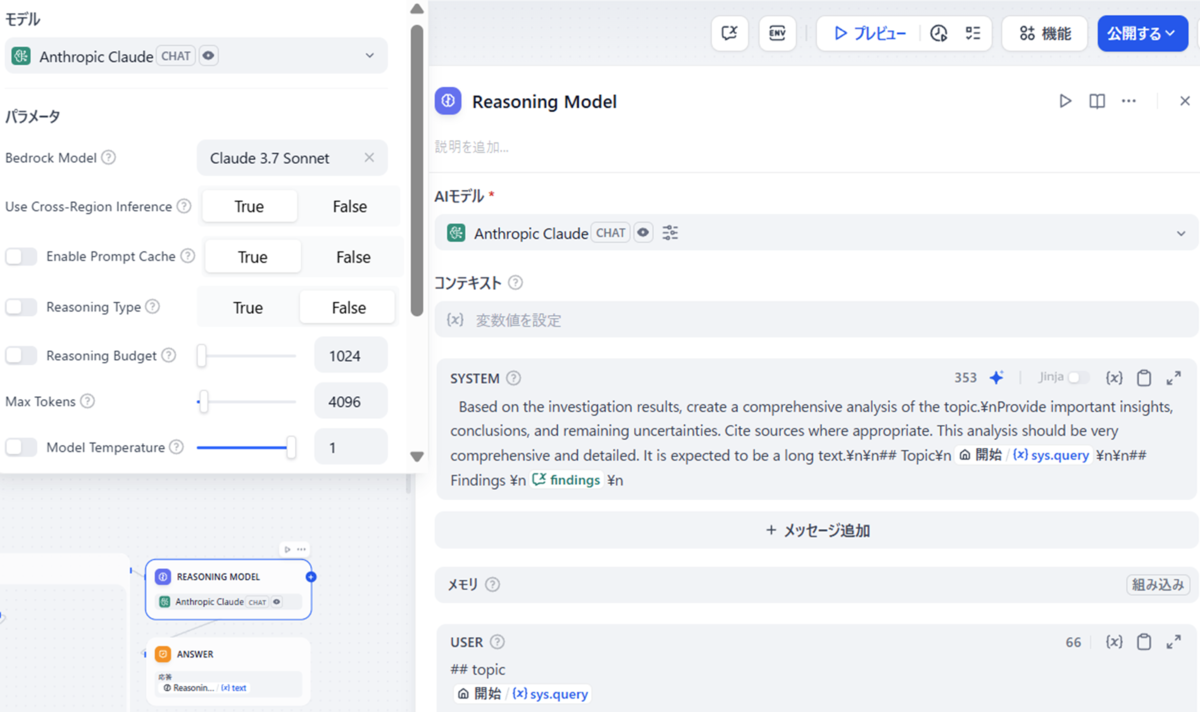
※DifyとBedrockの連携はできているものとします
また、検索の思考過程が中国語になる事象があったので、思考過程を全て日本語で出力するようにシステムプロンプトを追記しました。
ワークフロー中のイテレーションブロックのアルゴリズムの説明
1. ワークフローの入力
ワークフローの入力は以下の2つです。
- ①depth:何回までイテレーションするかの最大回数(オプション)
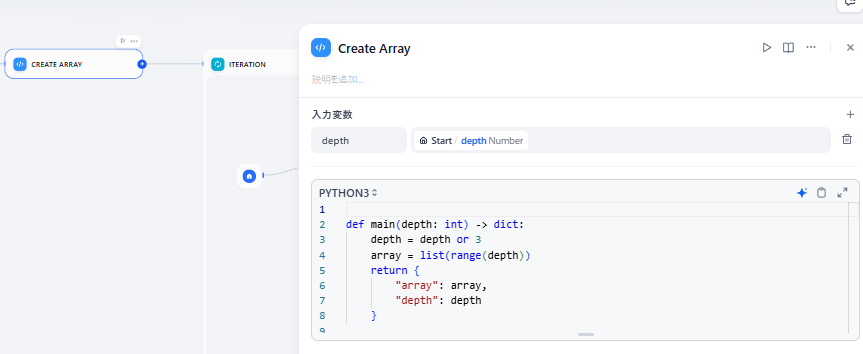
- ②sys.query:ユーザーが最初に入力した「調べたいテーマ」
2. 検索トピックの生成方法
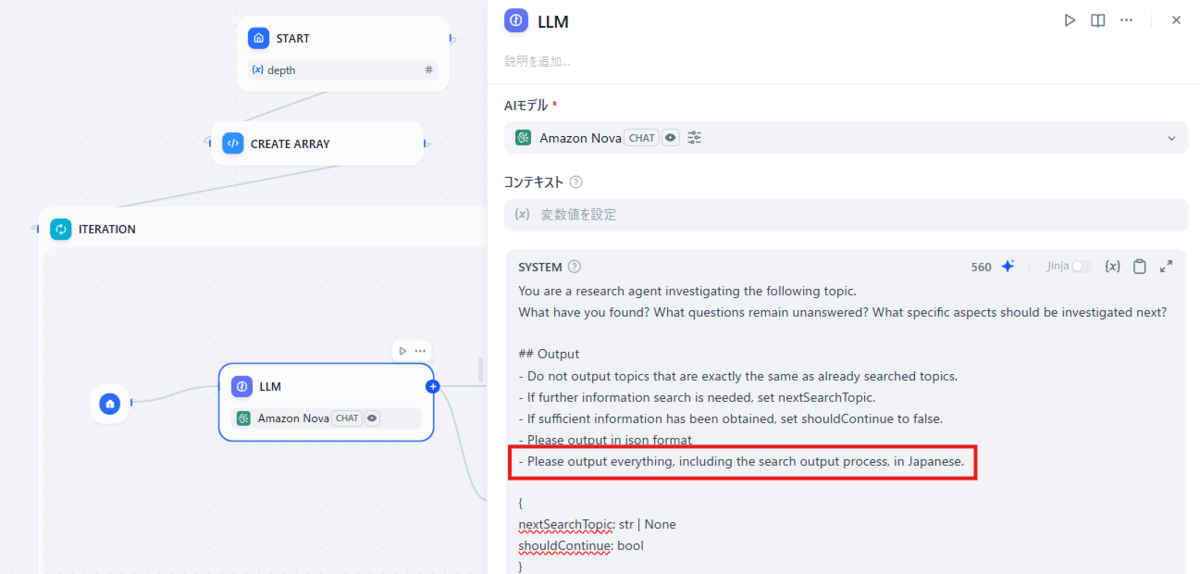
検索トピックの生成はLLMによって生成されています。
LLMに与えているシステムプロンプトは以下のようになっています。
要するに、今まで検索した結果から不明点があるものの中で、これまで検索したトピックとは被らないトピックを再度検索するようにしています。
You are a research agent investigating the following topic.
What have you found? What questions remain unanswered? What specific aspects should be investigated next?
## Output
- Do not output topics that are exactly the same as already searched topics.
- If further information search is needed, set nextSearchTopic.
- If sufficient information has been obtained, set shouldContinue to false.
- Please output in json format
- Please output everything, including the search output process, in Japanese.
{
nextSearchTopic: str | None
shouldContinue: bool
}
3. どうやって再検索が必要か否かを判断されているか
イテレーションを抜ける条件は以下の2つです。
- shouldContinueがFalseになったとき
- イテレーションした回数がdepthに達したとき
3. 実際にワークフローを動かす
では、実際に、Dify上でワークフローを動作させてみます。
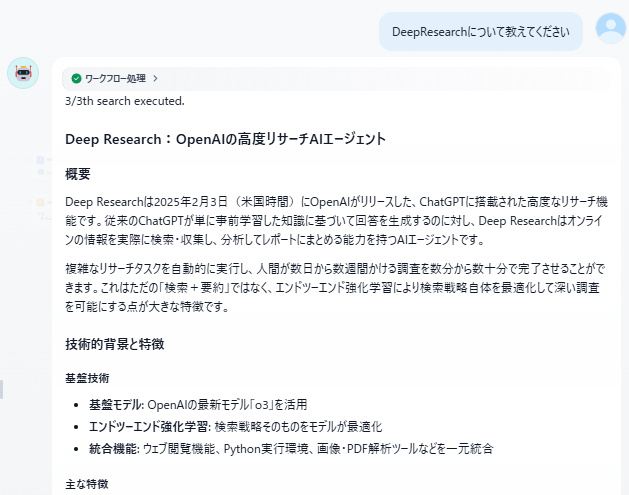
DeepResearchについて質問してみたところ、以下のような出力が得られました。
概要の説明だけでなく、付随した情報まで検索してくれるため曖昧さを残さない結果を得ることができました。
また、概要の説明も複数の情報源を参照して出力されるため、信頼性の高いレポートになっていると言えます。
さらに、AIの出力のワークフロー処理を開くと、検索の過程の結果を見ることができます。
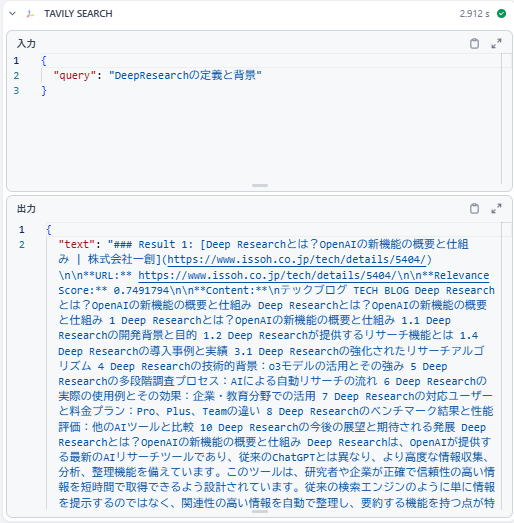
以下の画像では、入力キーワードに対して次の検索トピック(nextSearchTopic)が生成され、再検索が必要な場合にはshouldContinueフラグが「true」になっていることが確認できます。
- 各ブロックの実行時間
| # | ブロック | 実行時間(秒) |
| 1 | Start | 0.080 |
| 2 | 配列作成 | 0.108 |
| 3 | イテレーション1回目 | 4.563 |
| 4 | イテレーション2回目 | 4.866 |
| 5 | イテレーション3回目 | 2.225 |
| 6 | Reasoning Model | 55.904 |
| 7 | 回答 | 0.039 |
| 計 | 67.885 |
4. まとめ
この記事では、Difyを使ってDeepResearchを実現する方法について説明しました。
Difyを活用すれば、AIが生成したトピックを連続的に検索・分析し、調査の深度を自動で制御することでDeepResearchを実現させることができます。
AWSのBedrockとDifyの連携も容易であり、柔軟なモデル選択が可能です。ぜひ自身のプロジェクトにも取り入れ、調査業務の効率化を体感してください。
Acroquest Technologyでは、キャリア採用を行っています。
- Azure OpenAI/Amazon Bedrock等を使った生成AIソリューションの開発
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- マイクロサービス、DevOps、最新のOSSやクラウドサービスを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。