こんにちは。
Acroquestのデータサイエンスチーム「YAMALEX」に所属する@shin0higuchiです😊
YAMALEXチームでは、コンペティションへの参加や自社製品開発、技術研究などに日々取り組んでいます。
2025年12月11日(木)、東京で開催された OpenSearch Con Japan 2025 に参加してきました。
events.linuxfoundation.org
私は普段 OpenSearch/Elasticsearchなどを利用した検索サービスの開発やチューニングなどに携わっているので、今回のイベントはとても楽しみにしていました。
この記事では、イベント全体の雰囲気を簡単お伝えしつつ、
個人的に「これは実運用で効く!」と強く感じたセッションについて、少し厚めにレポートしたいと思います。

イベントの概要と雰囲気
OpenSearchは、Elasticsearchからフォークして以降、独自の進化を続けているオープンソースの検索・分析エンジンです。
昨年Linux Foundationが「OpenSearch Software Foundation」の発足を発表し、コミュニティ主導の開発・活動が進められています。
今回のカンファレンスは、OpenSearchのグローバルカンファレンスとして初めて日本で開催されたものでした。グローバル前提だったので英語セッションを基本としつつも、Wordlyによるリアルタイムな日本語訳も提供されていました。
コミュニティ主導のガバナンスの話から、ベクトル検索(Vector Search)のパフォーマンス改善、そしてAI/LLMを活用したRAG(Retrieval-Augmented Generation)の実装パターンまで、多岐にわたるセッションが行われました。

検索基盤としてだけでなく、生成AIのバックエンドとしてOpenSearchを利用しようとするエンジニアやデータサイエンティストの姿も多く、エコシステムの広がりを肌で感じることができました。

注目のセッション:Maximize Resource Efficiency with Separated Index and Search Workloads
さて、今回私が最も興味深く聴かせていただいたのが、Amazon Web ServicesのSotaro Hikitaさんによる 「Maximize Resource Efficiency with Separated Index and Search Workloads」というセッションです。
OpenSearch(やElasticsearch)を大規模に運用していると、必ずと言っていいほど直面するのが「インデックス(書き込み)とサーチ(検索)のリソース競合」という課題です。
このセッションでは、OpenSearchの新しいアーキテクチャ機能を活用してこれらのワークロードを分離し、リソース効率を最大化する方法が解説されていました。
OpenSearch Serverlessを利用すると、この悩み自体は解決するのですが、
OpenSearchがソフトウェアレベルでRead/Writeの分離構成をとることができるというのは大きな変化だと感じました。

これまでの標準的なクラスタ構成では、「データノード」がインデックス処理と検索処理の両方を担っていました。
そのため、以下のような問題が頻発していました。
1. Noisy Neighbor(うるさい隣人)問題:
大量のログデータを取り込んでいる最中(CPU/IO高負荷)に、ユーザーからの検索リクエストが遅延する。
2. スケーリングのジレンマ:
「検索だけが重い」のに、ノードを追加するとインデックス用のリソース(CPU/ディスク)も余分についてきてしまい、コスト効率が悪い。
Hikitaさんのセッションでは、「インデクシングと検索を物理的に分離する」ことで、これらの課題を解決するアプローチが紹介されました。
Segment Replication と Remote Store による分離
具体的な解決策のキーとなるのが、Segment Replication と Remote Store の活用です。
従来の「Document Replication」では、プライマリシャードとレプリカシャードの両方でインデキシング処理(CPUを消費する解析処理など)を行っていました。つまり、レプリカを増やせば増やすほど、書き込み時のCPU総コストも増えてしまっていました。
対して、新しいアーキテクチャでは以下のような動きになります。
Writer(インデックス用ノード): 書き込みを受け付け、セグメント(インデックスの実体ファイル)を作成し、それをRemote Store(S3などのオブジェクトストレージ)に転送します。
Reader(検索用ノード): 自分でインデックス処理(ドキュメント解析等)は行わず、Remote Storeからセグメントデータをプルして同期します。
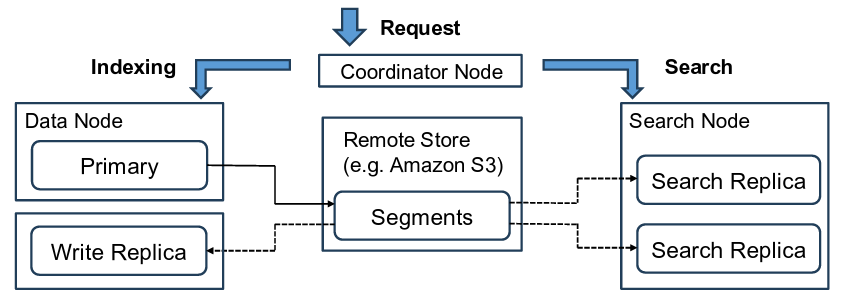
これにより、検索用ノード(Reader)は重いインデキシング処理から解放され、CPUリソースを純粋に検索クエリの処理だけに集中させることができるようになります。
このアーキテクチャの何が嬉しいのか?
個人的に刺さったメリットは、「独立したスケーリング(Independent Scaling)」が可能になる点です。
例えば、「夜間に大量のバッチ取り込みがあり、日中は検索アクセスがスパイクする」といったECサイトのようなケースでも、それぞれのピークに合わせて必要なリソースだけをスケールさせることが可能になります。
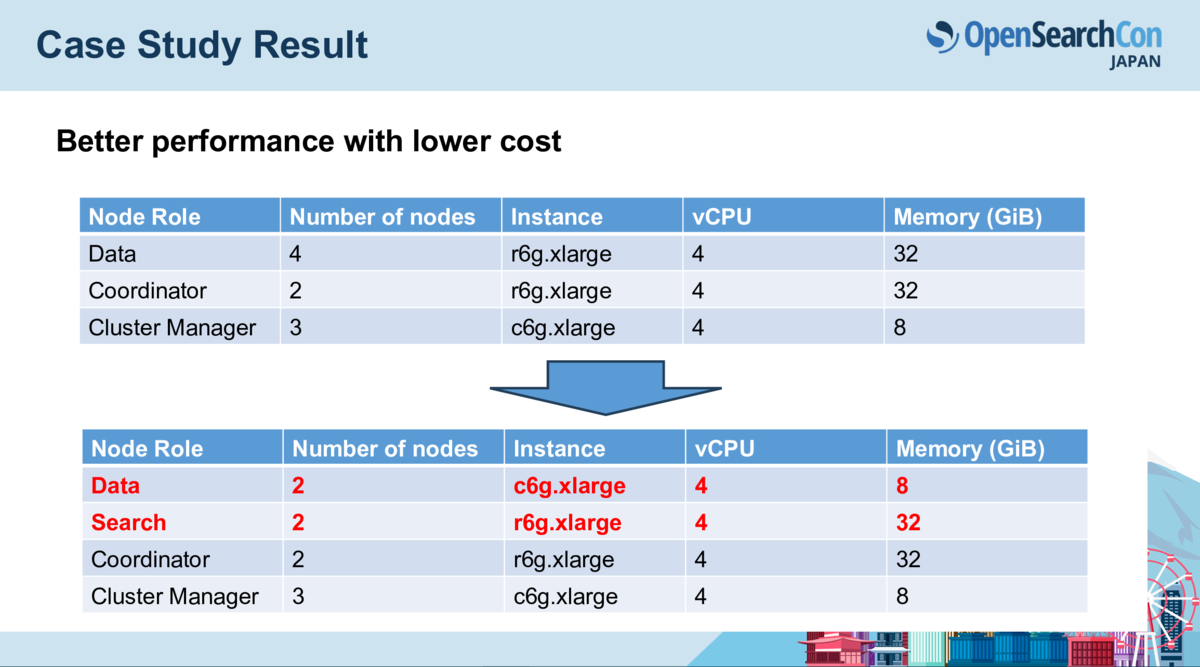
セッションでは、この構成によるコスト削減効果やスループット向上のベンチマーク結果も示されており、大規模な検索基盤を抱える場合の悩みを解消してくれそうだと感じました。
発表の中で示された例としては 32GiBのインスタンス4つを利用していたところ、そのうちの2台を 8GiB のインスタンスに変更して同トラフィックを捌く例などがありました。
実運用上でも、近いケースはありそうなので、非常に有用だと感じます。
その他のトピックもちろん、このセッション以外にも興味深いトピックが目白押しでした。
- OpenSearch Agentic Memory: AIエージェントに「記憶」を持たせるための新しいアプローチ。
- インテリジェントな日本語検索をOpenSearchで実現する方法など。
opensearchconjapan2025.sched.com
opensearchconjapan2025.sched.com
まとめ
OpenSearch Con Japan 2025は、単なる機能紹介にとどまらず、実際の運用課題に即したDeep Diveなセッションが多く、非常に充実した一日でした。
今回の記事は以上となります。
最後までお読みいただきありがとうございました。