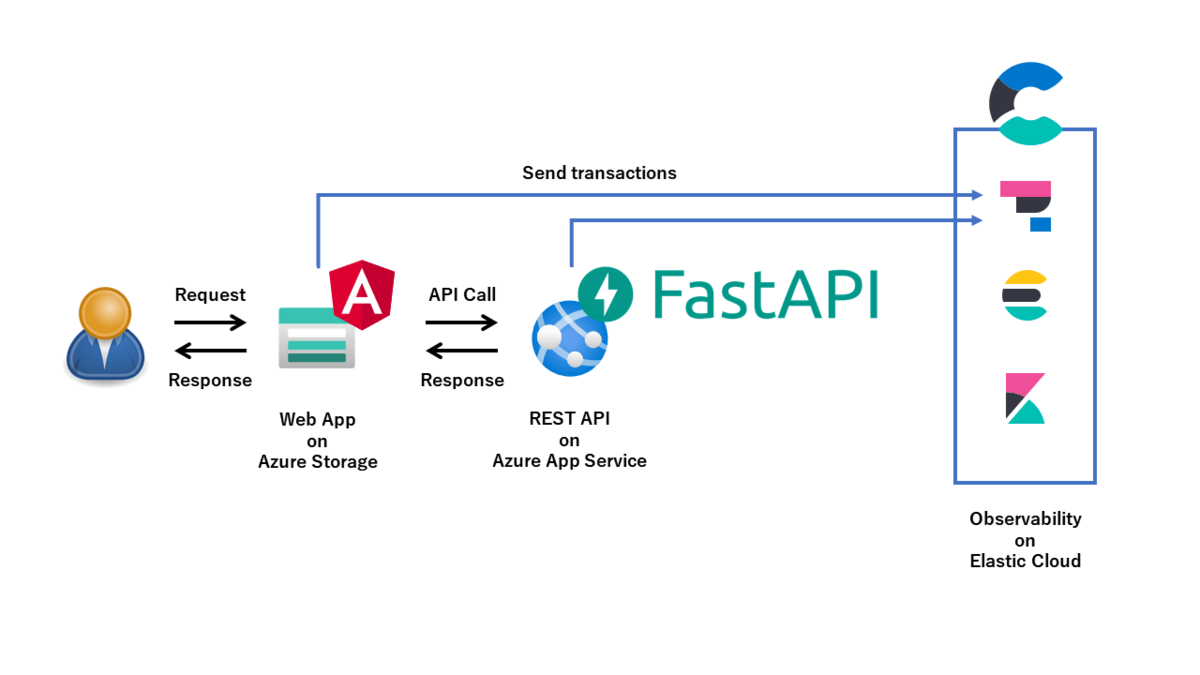
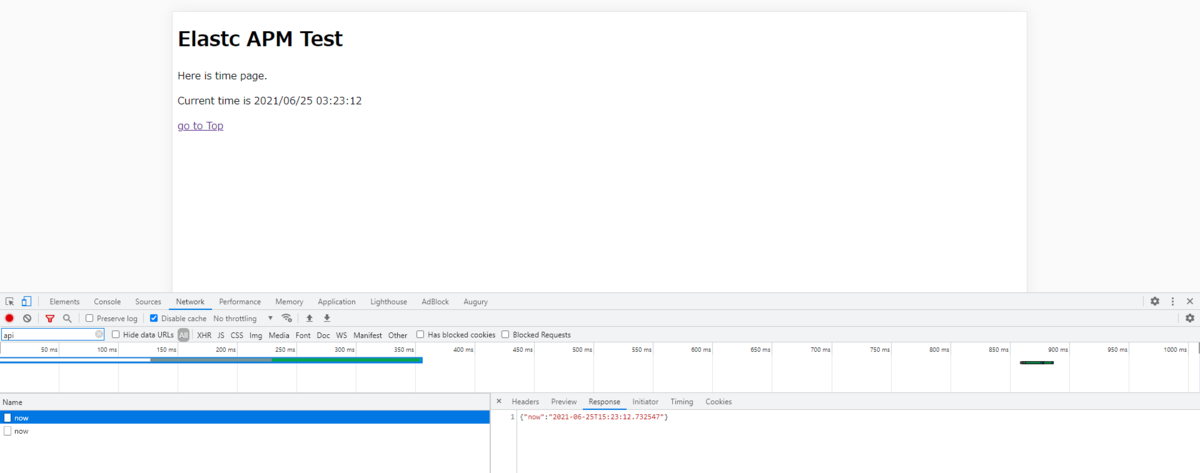
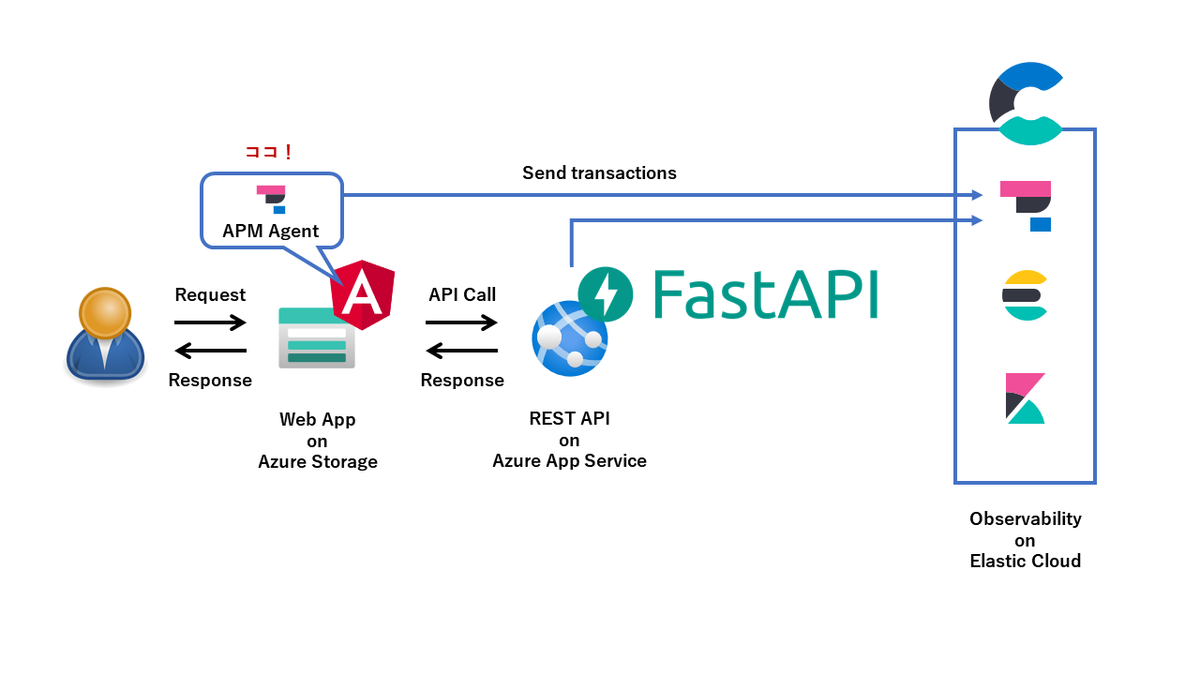
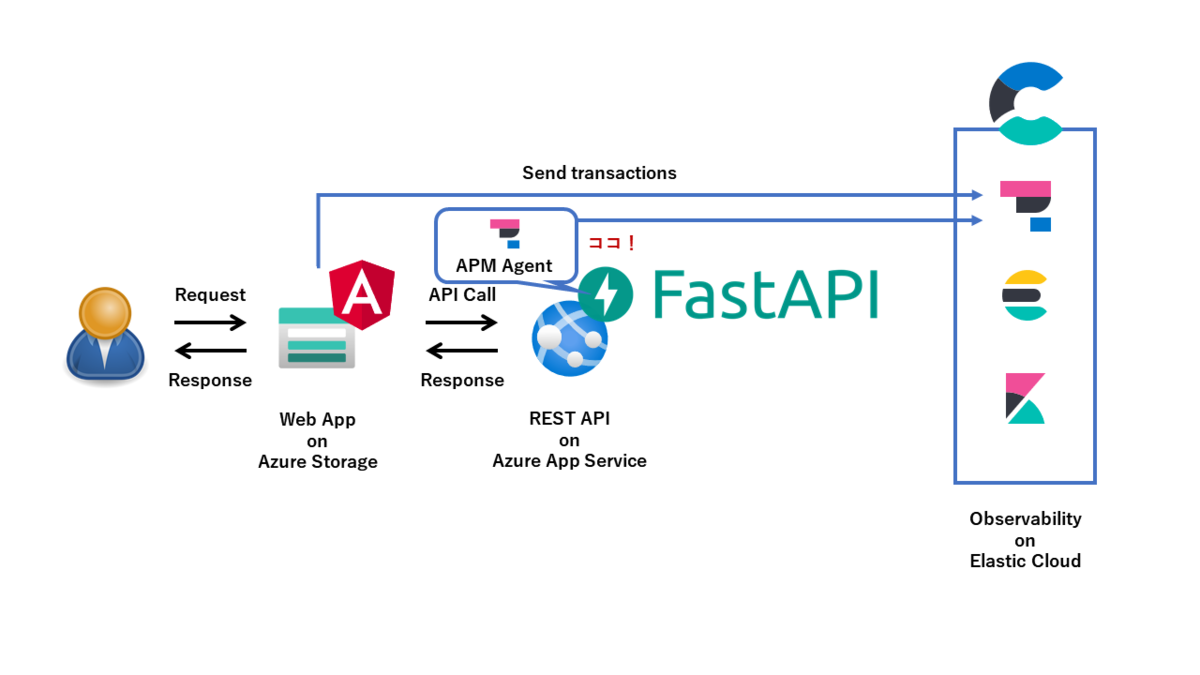
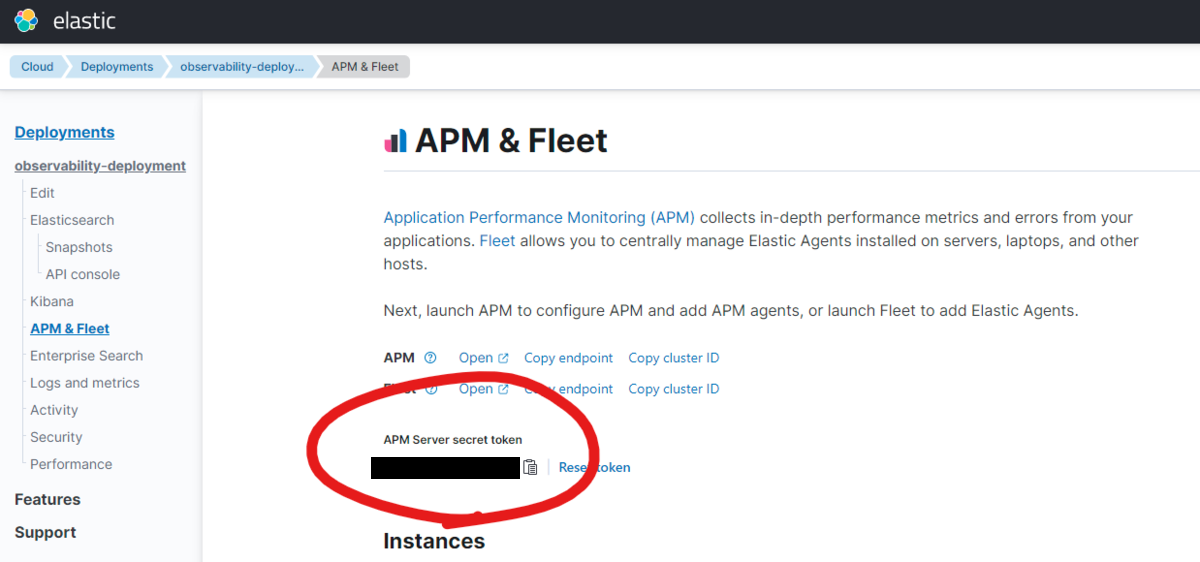
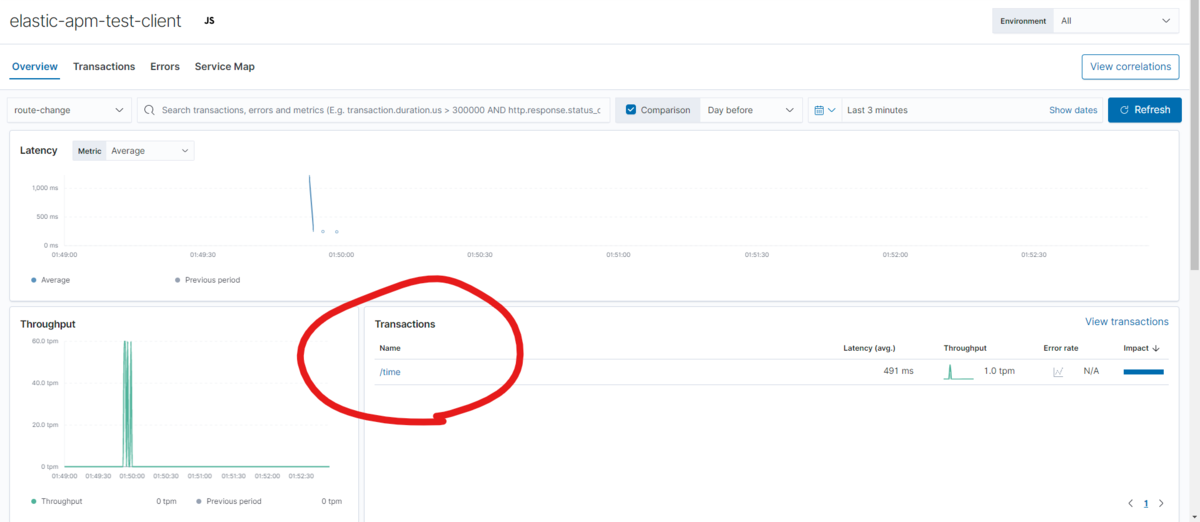
TorrentioVideoの開発に携わっている、3年目MLアプリケーションエンジニアの@yktm31です。
7/9(金)に開催された、PRODUCT LEADERS 2021というイベントに参加したので、レポートしたいと思います。
イベント概要
PRODUCT LEADERS 2021は、Ken Wakamatsuさんが立ち上げた、日本CPO協会が主催するイベントで、
「日本企業をプロダクトの力で強く進化させる」というミッションのために開催されました。
Salesforce、Adobe、AtlassianなどのCPO、プロダクトマネージャーの、 プロダクトづくりにおける考えやマインド、意思決定やノウハウがなんと無料で聴けるというイベント。
全部で約9時間になるイベントで、一つ一つのセッションの密度が濃くとても刺激的でした。
全部を網羅するのは難しいので、本記事では特に印象に残ったセッションを3つほど取り上げたいとおもいます。
全体の概要を知りたい方は、ハヤカワカズキさんのまとめをぜひ読んでみてください
印象に残ったセッション
Keynote CPOとは - CEO/CTOとの働き方 (Pratima Arora)
Pratimaさんは、Atlassian社でPM(プロダクトマネージャー), GM(ジェネラルマネージャー)を経験し、 現在はChainalysis社でCPOとして働いている方。
PratimaさんはCPOについて、乗り物に例え、以下のように説明していました。
- なぜその目的地を目指すのか
- 目的地では何をするのか
- なぜ私たちが、他の誰かではなく、その目的地に行くのか
- 同じ方向に向かっている船と、自分たちはどのように違うのか
つまり、CPOに求められるのは、ビジョンと戦略掲げること、それを元に帆を調整し前に進めること(=実行力)。
エンジニアである自分は普段、How(どのように目の前を解決するか)にコミットしています。 ですが、プロダクトリーダと同じ方向を向くためにも、プロダクトリーダが考えるWhy/Whatを理解していくことが重要だな、と感じました。
他には、顧客との関係、UXとの関わり方、多様性に対する考え方、チーム構築などの話をされていました。
その中でも特に印象に残ったのは、最後に話されていた、「最終的にはすべて人」ということ。
Pratimaさんは、少人数のチームから数百人規模のチームへ拡大した経験もある中、
「自律的で責任感のあるチームを作ること」が、ビジョンを元に前に進むために重要だと学んだと語っていました。
「PMだけでは何もできない」とも言っており、良いプロダクト作りは、
良い組織・良いコミュニケーションの中から生まれるのだ、と実感がこもった重みを感じました。
■CPOとは
— おざき はやと /// SaaSのプロダクトマネージャー /// (@grisoluto) 2021年7月9日
・方向性、ビジョン、戦略50%で、実行力が50%
・顧客文化の醸成のために、お客様の声を組織に持ち込むことが大事
・チームを作る上では認知多様性を意識し、経験ではなくスキルと情熱をみる
・最高のPMは情熱を持って問題を解決している人。興味のある問題を見つけることも大切
#japancpo pic.twitter.com/zQfe7LBf9v
プロダクトチームをリードする人材育成 (Marcus Torres)
ServiceNow社でGeneral Managerを勤めるMarcusさんによる、PMの育成・チーム構築の話でした。
Marcusさんが言っていた、「プロダクト・マインドセット」という言葉が、特に印象に残りました。
「プロダクト・マインドセット」とは、Marcusさん曰く、ソフトウェアに限らず物理的なものについても、
「その製品の目的はなんなのか」「何を達成しようとしているのか」「どうすればより良くなるのか」というプロダクト視点で見ること。
Marcusさん自身のエピソードとして、とあるホテルのシャワーノブが非常に使いづらかった時、
「人が使いこなせないものは、自分なら選ばない!」と思ったそうです。
このように、身の回りの有形・無形の製品に対しする姿勢から、その人がプロダクトを些細なもの、と考えているのかどうか見えてくるそうです。
そして、この「プロダクト・マインドセット」は本からでは学べず、偽れないもの。
エンジニア出身のPMや、MBA出身のPMがいて、それぞれの視点があるが、この「プロダクト・マインドセット」は、共通的に重要なことだとMarcusさんは語っていました。

実際にMarcusさんは採用面接の場で、
「ある物理的な製品について自分の意見と、それをどうやって改善するのか」
ということを、候補者に聞いているそうです。
自分の胸に手を当て、、、出来ていないなと思わされました。
開発の中で、バックエンド・フロントエンド両方担当していますが、
特にフロントエンドの開発では、「使い勝手」を考え実装する、というチャンスを多くもらってます。
フロントをやる以上、UIデザインの知識がないといけないかな、と思っていましたが、
スキル的な面だけではなく、「プロダクト・マインドセット」を持つことの重要性を学びました。
新規開発とプロダクトマーケットフィット (Geoff Baum)
Adobe社の新規事業のリーダーを経験し、現在はAcceldata社でマーケティングを統括するBaumさんのセッション。
よりビジネスサイドの話題が中心で、Adobe社で新規事業を立ち上げたときのエピソードや、PMF(Product Market Fit)について話されていました。
その中での、Photoshop Expressについてのエピソードが面白かったです。
PhotoshopやLightroomという製品がある中で、写真家ではない人のモバイルでの写真編集という市場を開拓。
まず最初にターゲットのニーズを満たすためのアクセシビリティを考え、iOSアプリをリリースしてPMFを検証。
どこでどんな機能を使っているのか、編集した写真を有料で保存、印刷したりするのか、などさまざまなメトリクスを分析し、
ユーザに価値が届いていると判断した時、次のGo-to-Marketのための施策を打つ。
プロダクトを立ち上げから、顧客のニーズを検証、プロダクトのスケールのために動いていく。
プロダクトマネージャーは、プロダクトのCEO(ミニCEO)と呼ばれることもありますが、
まさにプロダクトの成長にコミットするという、プロダクトマネージャー的なエピソードだと感じました。
パワーポイント上で作ったアイディアを、1000万ドル以上の収益にまで成長させた経験があるというBaumさんの、経験に裏打ちされた解像度の高い話がとても面白かったです。
■新規開発とプロダクトマーケットフィット
— おざき はやと /// SaaSのプロダクトマネージャー /// (@grisoluto) 2021年7月9日
登壇:AcceldataのVPoM
・顧客が中心、ビジネスの中心は顧客
・顧客が切実に悩む狭いスペースを見つけ、集中して取り組むことで差別化・独自性が生まれてくる
・シリコンバレーでは、販売が先で製品が後。それ以外では、製品が先で販売が後。
#japancpo pic.twitter.com/VvUOkrZWDk
最後に
このイベント登壇していたのは、最先端のテック企業で、 複数のプロダクトをマネージし、複雑な意思決定をしてきた熟練のCPOやPM。
たかだか2,3年のSWE経験しかない自分には、難しい話も正直多かったです。 しかしそれでも、プロダクトに関わる一人でもあり、 どのようにプロダクトを育てていくかという点は興味がある部分。
今回のイベントを通して、世界のプロダクトリーダのマインドセット・考え方に触れることができたのは、 とても刺激になりました。
当社は、ENdoSnipe、そして私が関わるTorrentioVideoという2つのプロダクトを展開しています。 プロダクトを通し、顧客に価値を届け、世の中の課題を解決していきたい。そう思えるイベントでした。
今回初回だったPRODUCT LEADERS 2021、年末に2回目の開催が予定されているそうです。
このような会を、無料で開催してもらえていること、とても有難いなと感じます。
主催の、日本CPO協会の方々ありがとうございます。
(微力ながら寄付させていただきました。)
次回もぜひ、参加しようと思います。
P.S.
記事中、おざきはやとさんのTweetを引用させていただきました。
イベント実況、ありがとうございました。
Acroquest Technologyでは、キャリア採用を行っています。
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。
【データ分析】 Kaggle Masterと働きたい尖ったエンジニアWanted! - Acroquest Technology株式会社のデータサイエンティストの求人 - Wantedlywww.wantedly.com