概要
こんにちは、機械学習エンジニアの古賀です。
最近、人の動きを時系列で解析するためにグラフデータを扱ったのですが、データ量が大きくなると解析に時間がかかってしまい、効率が悪いと感じることがありました。
そんな中、cuGraph という高速にグラフ分析ができるライブラリが あることを知ったので、どれくらい高速なのか、有名なページランクの計算を題材に他のライブラリと速度を比較してみました。
目次は以下です。
グラフとは
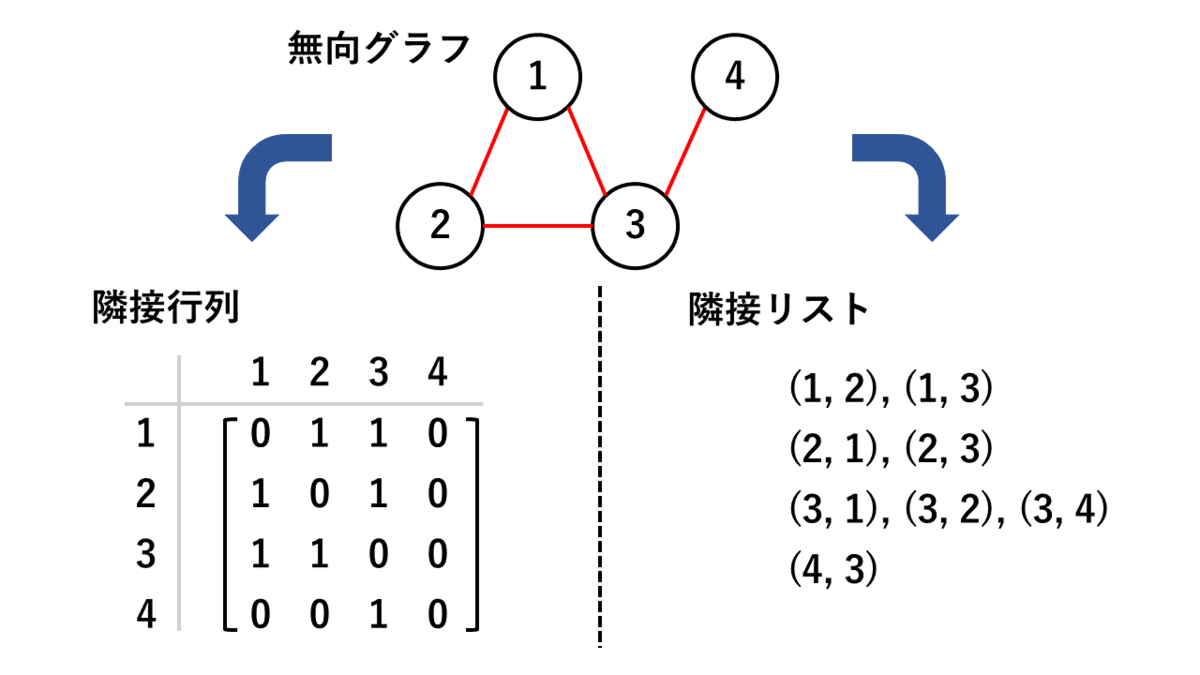
グラフ(Graph)とは、頂点(node)と辺(edge)により構成された図形のことです。
グラフによって、路線図、ソーシャルネットワーク、分子構造など、ものとものとの繋がりを抽象的に表現することができます。
これにより様々なデータを分析することができますが、特にソーシャルネットワークのデータなどはデータ数が大きくなりがちななため、分析の際の計算に時間がかかってしまうのが課題の一つです。
グラフは主に、
- 有向グラフ (directed graph)
- 頂点と向きを持つ辺により構成されたグラフ
- 無向グラフ (undirected graph)
- 頂点と辺のみにより構成されたグラフ
の2つに分類されます(以下の図)。
またさらにその中にも、各辺に重みがあるもの(重み付きグラフ)、2頂点間に複数の辺があるもの(多重グラフ)などのグラフが存在します。

グラフを表現するデータ構造には、
- 隣接行列
- 各要素が、頂点の対がグラフ中で隣接しているか否かを示す行列
- 隣接リスト
- グラフにある頂点または辺を全てリストで表現したもの
などがあり(以下の図)、利用用途によって使い分けられます。
Python によるグラフデータの分析
上で書いたようにグラフには様々な種類があり、その分析のためのアルゴリズムも多種多様です。そのため、グラフの構築、グラフアルゴリズムの計算、グラフの可視化などを一から実装するのはとても大変です。
Python にはこれらを簡単に行うことができるライブラリがいくつかあり、代表的なライブラリに NetworkX があります。
NetworkX は機能が豊富で非常に便利なのですが、GPU に対応していないため、データ量が大きくなると計算速度が遅くなってしまうのが課題となっています。
cuGraphとは
cuGraph はNVIDIAさんが開発している、GPU でのグラフデータ分析のアルゴリズムを集めたライブラリです。
NetworkX など他の Python のグラフライブラリと違い GPU に対応しており、 GPU 上で高速に処理することができます。
ページランクとは
グラフデータで利用される有名なアルゴリズムとして、ページランク (PageRank) があります。
ページランクは、Web ページの相対的な重要度を決定し、順位付けするためのアルゴリズムです。 検索エンジンの Google において、検索語に対する適切な結果を得るために用いられています。
この時、各 Web ページに固有の重要度を表す数値をページランク値と呼び、ページランクのアルゴリズムで算出されます。
各 Web ページのページランク値は「重要なページからのリンクが多いページは価値が高い」となるよう、リンク元の Web ページのページランク値を元に算出されます(詳細は以下)。
ページランク値の定義
Web ページ のページランク値
は、
で定義されます。
ここで、 は Web ページ
のリンク元のWeb ページの集合を、
はWebページ
から出ているリンクの総数を、
はWeb ページの総数を表します。また、
は damping factor とよばれ、リンク元の Web ページのページランクによる影響度を調整するパラメータです。
0 ≦ d < 1 の間の数で、通常 に設定されます。
ページランクとグラフ
Web ページのリンク関係は、各 Web ページを頂点、Web ページへのリンクを辺とする有向グラフと考え、隣接行列で表現することができます。
したがって、上で定義したページランク値の式も行列で表現することができ、ページランクは「グラフの各ノードの重要度を算出するアルゴリズム」と考えることができます。
詳細については以下の文献を参考にしてください。
PageRank アルゴリズム およびそれに関連する研究について
検証
cuGraph がどの程度高速に処理できるのか、GPUを使わないグラフ計算のライブラリ NetworkX と比較します。
実行環境
手元にGPUがなくても簡単に試すことができるよう、Google Colaboratory を使用しました。
ランタイムは、ハードウェアアクセラレータをGPU、ランタイムの仕様をハイメモリに設定しました。
cuGraph ライブラリのインストール
Google Colaboratory 上で cuGraph を動かすため、以下のコマンドを実行してください。
!git clone https://github.com/rapidsai/rapidsai-csp-utils.git !bash rapidsai-csp-utils/colab/rapids-colab.sh stable import sys, os dist_package_index = sys.path.index('/usr/local/lib/python3.7/dist-packages') sys.path = sys.path[:dist_package_index] + ['/usr/local/lib/python3.7/site-packages'] + sys.path[dist_package_index:] sys.path exec(open('rapidsai-csp-utils/colab/update_modules.py').read(), globals())
ライブラリのインポート
以下のコマンドで cugraph ライブラリと、検証に必要なライブラリをインポートします。
import time import cudf import cugraph import networkx as nx import numpy as np import pandas as pd
データセット
本検証では疑似データとして、ノード10万個、エッジ約2,000万個のグラフデータを作成します。
N = 20000000 df = pd.DataFrame([{'src': np.random.randint(0,100000), 'dst': np.random.randint(0, 100000)} for _ in range(N)] df = df.astype(np.int32) df = df.drop_duplicates() print(f'nodes: {len(df["src"].unique())}') print(f'edges: {df.shape[0]}'
上記を実行した結果は
nodes: 100000 edges: 19980133
でした。
検証内容・結果
公式の README.md によると、cuGraph は cuGraph Graph classes だけでなく、NetworkX graph classes にも対応しているようなので、
今回は、ページランクアルゴリズムだけでなくグラフオブジェクトも cuGraph, NetworkX の両方を使い、計算速度を比較してみました。
1. NetworkX のグラフ、NetworkX のアルゴリズムを用いてページランクを計算
# source (src), destination (dst) ベクトルのペアからグラフを生成する G = nx.from_pandas_edgelist(df, source='src', target='dst', create_using=nx.DiGraph()) # ページランクの計算時間を計測する start_time = time.time() pr = nx.pagerank(G) print(f'{time.time() - start_time:.3f}秒')
上記を5回実行した平均は、19.158秒 でした。
2. NetworkX のグラフ、cuGraph のアルゴリズムを用いてページランクを計算
# source (src), destination (dst) ベクトルのペアからグラフを生成する G = nx.from_pandas_edgelist(df, source='src', target='dst', create_using=nx.DiGraph()) # ページランクの計算時間を計測する start_time = time.time() df_page = cugraph.pagerank(G) print(f'{time.time() - start_time:.3f}秒')
上記を5回実行した平均は、11.720秒 でした。
3. cuGraph のグラフ、cuGraph のアルゴリズムを用いてページランクを計算
cuGraph のグラフ(cuGraph Graph classes)作成時の入力には、Pandas の DataFrame ではなく、cuDF という GPU 上で高速に計算できるライブラリの DataFrame を使用します。
cuDF の詳細は以下の記事を参考にしてください。
# Pandas.DataFrame を cudf に変換する gdf = cudf.from_pandas(df) # source (src), destination (dst) ベクトルのペアからグラフを生成する cuG = cugraph.DiGraph() cuG.from_cudf_edgelist(gdf, source='src', destination='dst') # ページランクの計算時間を計測する start_time = time.time() df_page = cugraph.pagerank(cuG) print(f'{time.time() - start_time:.3f}秒')
上記を5回実行した平均は、0.009秒 でした。
まとめると以下の結果になりました。
| グラフのライブラリ | ページランクアルゴリズムのライブラリ | 計算時間(5回の平均)[秒] |
|---|---|---|
| NetworkX | NetworkX | 19.158 |
| NetworkX | cuGraph | 11.720 |
| cuGraph | cuGraph | 0.009 |
cuGraph のグラフ、cuGraph のアルゴリズムを用いたときの計算時間は、驚きの速さになりました!これだけ速いと実験もはかどりますね。
計算時間の順番も、
cuGraph のグラフ, cuGraph のアルゴリズム > NetworkX のグラフ, cuGraph のアルゴリズム > NetworkX のグラフ, NetworkX のアルゴリズム
という、予想と一致する内容となりました。
大規模なグラフデータを扱う際に GPU 環境が用意できるならば、cuDF + cuGraph の組み合わせが有力な候補になりそうです。
最後に
今回初めて cuGraph を使ってみましたが、とくに癖もなく使いやすく、かなり高速で驚きました。
ページランク以外にも便利なアルゴリズムがいくつも実装されているので、今後もグラフデータを扱う際には重宝しそうです。
Acroquest Technologyでは、キャリア採用を行っています。
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。
【データ分析】 Kaggle Masterと働きたい尖ったエンジニアWanted! - Acroquest Technology株式会社のデータサイエンティストの求人 - Wantedlywww.wantedly.com