枝差ししていたバジルが順調に成長して切り出し元の株と代替わりをしました、またバジル生活が始まりそうな菅野です。 
皆さんはChatGPTのAPIを利用していますでしょうか? まだ利用していない、利用方法がわからないという方は以下の記事をご覧ください。
APIの仕組みの中でも直感的にわかりづらいトークン数について、今回はさらに深堀していこうと思います。
トークンとは、Chat Completions API等OpenAIが提供するAPIの処理単位です。
入力、出力共にByte Pair Encodingした結果を1トークンとして処理します。
英語の場合は通常1単語1トークン、日本語の場合は1文字でも複数トークン換算される場合がある模様です。
- 実際に利用する文章のトークン数が事前に知りたい場合は以下のページで確認することができます。
https://platform.openai.com/tokenizer
今回は、上記のサイトを活用して、プログラムを利用する場合のトークン数が表記方法や言語によってどのような差分になるかを見ていきましょう。
Pythonの通常表記とワンライナー表記
Pythonでは、内包表記等を活用することである程度の処理を一行で表すことができます(可読性とはトレードオフになりますが)。
5. データ構造 — Python 3.11.4 ドキュメント
利用する文字数が少なくなれば出力トークンも減る可能性があります。
それぞれの出力方法についてトークン数がどのように変化するのか見ていきましょう。
通常出力
まずは、ワンライナーではない記法を試してみましょう。
入力:
出力:
以下は、二次元リストを平滑化するPythonスクリプトの例です。
def flatten(lst): flattened = [] for sublist in lst: for item in sublist: flattened.append(item) return flattened # 二次元リストの例 nested_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] # 平滑化されたリストを取得 flattened_list = flatten(nested_list) # 結果を表示 print(flattened_list)上記のコードでは、
flattenという関数を定義し、引数として与えられた二次元リストを平滑化して一次元リストに変換します。内側のループでは、各要素を取り出してflattenedリストに追加しています。最終的に、flatten関数は平滑化されたリストを返します。上記の例では、
nested_listという名前の二次元リストを使用しています。プログラムを実行すると、flattened_listという名前の変数に平滑化されたリストが格納されます。最後に、結果をなお、このスクリプトでは、二次元リストの深さが固定されていることを前提としています。もし、より一般的なケースであれば、再帰的なアプローチを検討する必要があります。

145文字63トークンとなりました。
def や for などの単語は1トークンとしてカウントされていることがわかります。
興味深いのはflatten。「flatt」「en」で2トークン換算されていますね。
一方、「flattened」は1トークンとして出力されるため文字列の長さによってトークン分割されているわけではなさそうです。
また、単語と隣り合っていないインデントの空白文字も一文字ずつトークンとして扱われているようです。
試しにインデントを2文字にしてみたところ、129文字、47トークンとなりました。

ワンライナーでの出力
つづいて、ワンライナーを試してみましょう。
入力:
出力:
以下が、二次元リストを平滑化するPythonのワンライナースクリプトです。
flatten_list = [item for sublist in your_list for item in sublist]このスクリプトでは、二重のリスト内包表記を使用しています。最初の
forループでは、元の二次元リストの各要素(リスト)に対してループを実行し、次のforループでは各要素の要素を展開して新しいリストに追加しています。結果として得られるflatten_listは、二次元リストを平滑化した結果となります。

66文字20トークンとなりました。
文字数自体はおよそ半分ですが、トークン数自体は3分の1になりました。
まとめてトークン換算されない空白が減っていることが寄与していそうです。
出力言語による違い
Python内の表現方法による違いは確認できましたが、出力する言語によってはどのように差分が出てくるのかも確認してみましょう。
APIから取得した情報をJSONファイルに出力するコードをPython、Javaでそれぞれ作ってみました。
Pythonで作った場合
import requests import json class APIClient: def __init__(self, endpoint): self.endpoint = endpoint def get_data(self, params=None): try: response = requests.get(self.endpoint, params=params) response.raise_for_status() return response.json() except requests.RequestException as e: raise RuntimeError(f"API request failed: {str(e)}") def save_to_file(self, data, filename): try: with open(filename, 'w') as f: json.dump(data, f, indent=4) except Exception as e: raise RuntimeError(f"Failed to save data to file {filename}: {str(e)}") def fetch_and_save(self, filename, params=None): data = self.get_data(params) self.save_to_file(data, filename) if __name__ == "__main__": api = APIClient("https://api.example.com/data") try: api.fetch_and_save("data.json", params={"type": "sample"}) except RuntimeError as e: print(f"Error: {str(e)}")

1033文字、459トークンでした。
Javaでの出力
import java.net.HttpURLConnection; import java.net.URL; import java.util.Map; import java.nio.file.Files; import java.nio.file.Paths; import java.io.BufferedReader; import java.io.InputStreamReader; import java.io.OutputStream; import org.json.JSONObject; public class APIClient { private final String endpoint; public APIClient(String endpoint) { this.endpoint = endpoint; } public JSONObject getData(Map<String, String> params) throws Exception { StringBuilder urlWithParams = new StringBuilder(endpoint); if (params != null && !params.isEmpty()) { urlWithParams.append("?"); boolean isFirst = true; for (Map.Entry<String, String> entry : params.entrySet()) { if (!isFirst) { urlWithParams.append("&"); } urlWithParams.append(entry.getKey()).append("=").append(entry.getValue()); isFirst = false; } } URL url = new URL(urlWithParams.toString()); HttpURLConnection conn = (HttpURLConnection) url.openConnection(); conn.setRequestMethod("GET"); if (conn.getResponseCode() != 200) { throw new RuntimeException("Failed : HTTP error code : " + conn.getResponseCode()); } BufferedReader br = new BufferedReader(new InputStreamReader((conn.getInputStream()))); String output, jsonResponse = ""; while ((output = br.readLine()) != null) { jsonResponse += output; } conn.disconnect(); return new JSONObject(jsonResponse); } public void saveToFile(JSONObject data, String filename) throws Exception { try (OutputStream os = Files.newOutputStream(Paths.get(filename))) { os.write(data.toString(4).getBytes()); } } public void fetchAndSave(String filename, Map<String, String> params) throws Exception { JSONObject data = getData(params); saveToFile(data, filename); } public static void main(String[] args) { APIClient apiClient = new APIClient("https://api.example.com/data"); try { apiClient.fetchAndSave("data.json", Map.of("type", "sample")); } catch (Exception e) { e.printStackTrace(); } } }
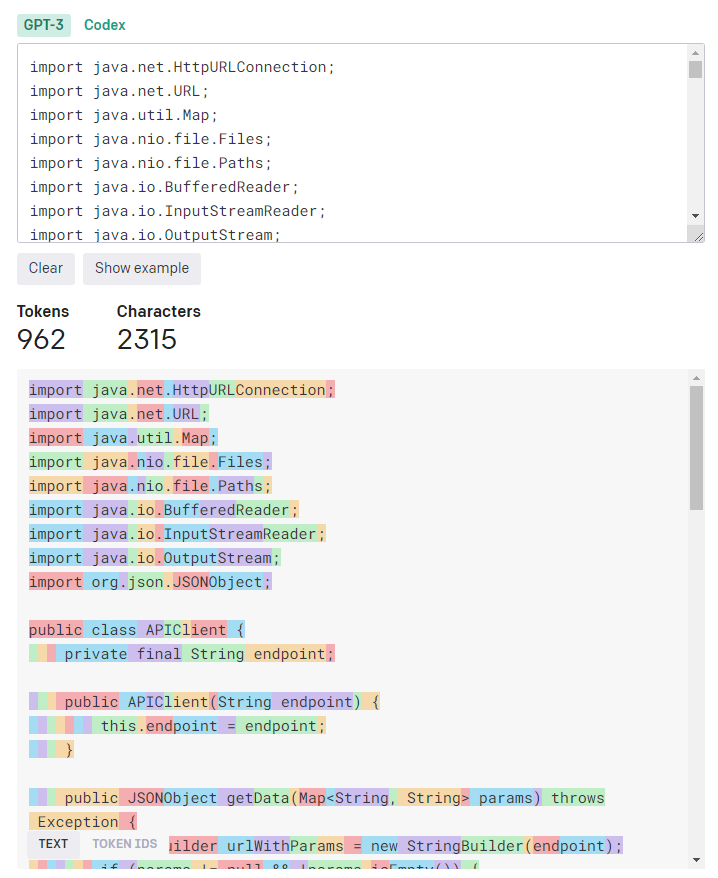
2315文字数、962トークンとなりました。
Pythonと比較してJavaでAPIでリクエストした結果をJSONに保存する処理でループを回す必要があるなど
処理が多い、且つインデントが深くなりやすい為、文字数、トークン数共に大きくなってしまう傾向にあります。
まとめ
コーディングの形式、言語ごとににかかるトークン数の調査を実施しました。
実際のコードよりも、インデントに用いられる空白がトークン数に大きく影響を与える点を知ることができました。
また、PythonとJavaの比較では、より処理の記載方法が複雑になりやすいJavaのほうがトークン数が多くなる傾向にあるみたいです(徐々にJavaもシンプルな記載ができるようにはなってきていますが)。
今後もChatGPT、OpenAIのAPIについて様々なことを試していこうと思います。
Acroquest Technologyでは、キャリア採用を行っています。少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。 www.wantedly.com
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSやクラウドサービスを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長