はじめに
こんにちは、データ分析エンジニアの木介です。 
秋も深まり、肌寒さを感じる季節となりましたが、皆様いかがお過ごしでしょうか。
今回はPineconeを使ったハイブリッド検索とリランクについて紹介していきます。
概要
今回は以下の形でPineconeをベクトルデータベースとして、ベクトル検索にリランクを合わせた検索とハイブリッド検索を行い、検索精度について検証を行っていきます。
1. Pineconeとは
Pineconeとは、RAGなどで活用されるマネージドなベクトルデータベースです。
従来のデータベースとは異なり、テキストや画像、音声などのデータを数値ベクトルとして保存し、これらのベクトル間の類似性を高速に検索することが可能です。
特にサーバレス版の料金形態として、データの読み込み/書き込み時とストレージの保存量に応じてのみかかるため、安価にサービスへの導入が可能です。
無料版もあるため、気軽にベクトルデータベースを試すことができます。
2. ベクトル検索とは
ベクトル検索は、テキストや画像などのデータを数値の配列(ベクトル)に変換し、類似性を数学的に計算することで情報を効率的に検索する技術です。
従来のキーワードベースの検索とは異なり、データの意味や文脈を考慮した検索が可能となります。
そのセマンティックに検索できるという点から、RAG(Retrieval-Augmented Generation)でもよく使われている技術になります。
3. リランクとは
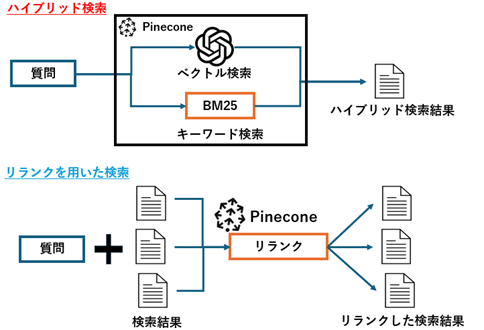
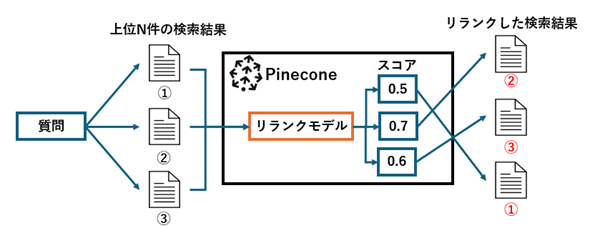
リランクとは図のように一度検索した結果を再度順位付けすることで、検索精度を高める手法です。
これにより、欲しい情報を上位の検索結果に持ってくることが可能となります。
Pineconeではリランクモデルを使用したものを利用することができます。
4. ハイブリッド検索とは
ハイブリッド検索は、ベクトル検索と従来のキーワード検索を組み合わせた手法です。これにより、キーワードの一致度と意味的な類似性の両方を考慮した検索が可能となります。
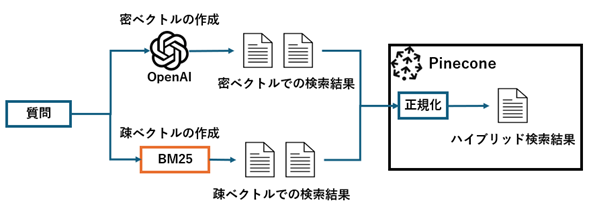
Pineconeが提供しているハイブリッド検索では、ベクトル検索に使われる文章の意味的なの類似度を比較できる密ベクトルと、キーワードベースの類似度の比較が可能な疎ベクトルを用いて検索が行われます。
以下の図のように密ベクトルと、疎ベクトルを用いて、ベクトル検索とキーワード検索を組み合わせることで検索を行っています。
- 疎ベクトル:大半の数値が0のベクトルで、キーワード検索に使う
- 密ベクトル:大半の数値が0以外でEmbeddingモデルによるベクトル検索に使う
Pineconeでのベクトル検索+リランクを用いた検索/ハイブリッド検索の検証
1. 検証環境
Pythonのライブラリは以下のバージョンを使用します。
| 名称 | バージョン | 説明 |
| pinecone | 5.3.1 | PineconeのAPIを利用する |
| openai | 1.51.2 | OpenAIのAPIを利用する |
| Janome | 0.5.0 | 日本語の形態解析ツール |
| rank_bm25 | 0.2.2 | BM25を使ってキーワード検索のスコアを算出する |
また、モデルとしては密ベクトルの作成にOpenAIのtext-embedding-3-smallを、リランクにはPineconeから利用できるbge-reranker-v2-m3を利用しました。
データセットしては宿のレビュー検索を想定した以下の簡単なレビュー文章を用意しました
| レビューNo | 文章 |
| 1 | この宿の温泉は、まさに極上の癒しでした。源泉かけ流しの湯はとても柔らかく、肌がすべすべになる感じがしました。露天風呂からは美しい山々の景色が広がり、夜には満天の星空を眺めながらゆっくりと浸かることができました。何度でも訪れたくなる温泉です。 |
| 2 | 宿の温泉はとても気持ち良く、リラックスできました。内湯と露天風呂があり、それぞれ異なる趣があります。特に露天風呂から見える庭園の景色が素晴らしく、四季折々の美しさを楽しむことができます。お湯も適温で、長時間浸かっていても疲れませんでした。 |
| 3 | 温泉が自慢の宿とのことで期待していましたが、期待以上でした。天然温泉の源泉をそのまま使用しているので、お湯の質がとても良く、温まった後もポカポカが続きました。貸切風呂も予約して利用しましたが、プライベートな空間で贅沢なひとときを過ごすことができました。 |
| 4 | 温泉は広々としていて、開放感が抜群でした。露天風呂からは海が一望でき、波の音を聞きながらゆっくりと過ごすことができました。お湯も熱すぎず、じっくりと温まることができてとても満足です。また、日帰り利用も可能なので、気軽に訪れることができるのも嬉しいポイントです。 |
| 5 | 温泉は硫黄の香りが心地よく、いかにも温泉に来たという実感がありました。お湯の効能も高く、肌がツルツルになるのを感じました。複数の湯船があり、時間帯によっては貸切状態になることもあり、贅沢な気分を味わえました。また、湯上がりに提供される冷たいドリンクも嬉しいサービスでした。 |
| 6 | 宿の食事はまさに芸術品のようでした。地元の新鮮な食材をふんだんに使った会席料理は、見た目も美しく、一品一品が丁寧に作られているのが伝わってきました。特に旬の魚介を使った刺身は絶品で、これだけでもまた訪れたいと思いました。 |
| 7 | 夕食は地元の名物料理が盛りだくさんで、大満足でした。特に炭火焼きでいただいた和牛ステーキは口の中でとろける美味しさで、何度もおかわりしたくなるほどでした。朝食も種類が豊富で、地元の野菜を使ったサラダや、手作りの豆腐が美味しかったです。 |
| 8 | 夕食はコース料理で、どれも美味しかったのですが、特に印象に残ったのは地元で採れた野菜を使った前菜と、自家製のデザートです。食材の味を活かしたシンプルな調理法で、素材の良さが際立っていました。朝食もバランスが良く、特に焼きたてのパンが絶品でした。 |
| 9 | 宿の食事は期待以上でした。海の近くということもあり、新鮮な魚介類が豊富に使われていて、お刺身や煮魚がとても美味しかったです。夕食は量もたっぷりで、どの料理も心のこもった味付けでした。朝食の和食もとても美味しく、特に温泉卵が絶品でした。 |
| 10 | 夕食は地元の食材をふんだんに使った創作料理で、どの料理も工夫が感じられました。特に地元産の野菜とお肉を使ったグリル料理が絶品で、素材の味がしっかりと引き立っていました。朝食も手作りのジャムや焼き立てのパンなど、こだわりが感じられる内容で、大変満足しました。 |
上記のレビュー文章は1~5は温泉について言及していて、6~10は食事について言及しているレビューです。
このレビュー記事から「お肉の料理がおいしい宿」というクエリが入力される場合を考えます。
想定としては上記の中だとNo. 7とNo. 10の記事が取得できることを期待しています。
上記のデータセットについて以下の検索結果がそれぞれどうなるのかを比較していきます。
| ベクトル検索 | 今回の検証のベースライン、文章の意味的な類似度から検索を行う |
| ベクトル検索+リランクを用いた検索 | ベクトル検索結果にリランクモデルによる再順位付けを行う |
| ハイブリッド検索 | 文章の意味的な類似度とキーワードの一致度から検索を行う |
2. 検索用のインデックス作成
では早速Pineconeでインデックスの作成をしていきます。
以下のPineconeのドキュメントを参考に進めていきます。
まず、Pineconeに保存するベクトルを算出します。
ベクトル検索でも使う密ベクトルとしてはOpenAIのtext-embedding-3-smallを利用して、以下の実装で算出を行いました。
from openai import OpenAI def embedding_dense(sentence_list): """密ベクトルに変換 Args: sentence_list (list): 密ベクトルに変換する文字列のリスト Returns: _type_: 密ベクトル """ client = OpenAI( api_key=OPENAI_API_KEY ) res = client.embeddings.create( model="text-embedding-3-small", input=sentence_list, dimensions=512 ) return [d.embedding for d in res.data]
キーワード検索で使う疎ベクトルは、Pineconeで使っている自然言語処理モジュールのnltkが日本語に対応していないため、日本語の形態素解析にJanomeを、BM25の算出にrank_bm2を用いていきます。
以下の実装で疎ベクトルの算出を行いました。
from rank_bm25 import BM25Okapi from janome.tokenizer import Tokenizer class BM25Vectorizer: def __init__(self): self.tokenizer = Tokenizer() self.bm25_model = None self.corpus_tokens = [] def fit(self, corpus): """ コーパスを受け取り、BM25モデルを初期化します。 :param corpus: リスト形式の文書群 """ self.corpus_tokens = [list(self.tokenizer.tokenize(doc, wakati=True)) for doc in corpus] self.bm25_model = BM25Okapi(self.corpus_tokens) def encode_documents(self, text): """ 入力テキストをスパースベクトル形式に変換します。 :param text: 文字列形式の入力テキスト :return: Pinecone互換のスパースベクトル(辞書形式) """ if not self.bm25_model: raise ValueError("BM25モデルが初期化されていません。fitメソッドを先に呼び出してください。") # トークンに分割 tokenized_text = list(self.tokenizer.tokenize(text, wakati=True)) scores = self.bm25_model.get_scores(tokenized_text) # 非ゼロの値のインデックスとスコアを算出 indices = np.nonzero(scores)[0].tolist() values = scores[indices].tolist() return {"indices": indices, "values": values} def embedding_sparse(bm25_model,sentence_list): """疎ベクトルにEmbedding Args: bm25_model (BM25Vectorizer): BM25の処理を行う sentence_list (list): 疎ベクトルに変換する文字列のリスト Returns: _type_: 疎ベクトル """ return [ bm25_model.encode_documents(sentense) for sentense in sentence_list ]
上記コードで算出した疎ベクトル、密ベクトルを以下のコードでPineconeに保存していきます。
from pinecone.grpc import PineconeGRPC as Pinecone #hybrid-image-searchという名前のindexを作成 index_name = "hybrid-image-search" pc = Pinecone(api_key=PINECONE_API_KEY) # create the index if index_name not in [ index_info["name"] for index_info in pc.list_indexes()]: pc.create_index( index_name, dimension=512, metric="dotproduct", spec=ServerlessSpec( cloud='aws', region='us-east-1' ) ) index = pc.Index(index_name) # インデックスにデータセットを挿入 upsert_response = index.upsert( vectors=[ { 'id': f'{vector_index}', 'values': dense_vec, 'sparse_values': sparse_vec, "metadata":{"answer":answer} } for vector_index,(sparse_vec,dense_vec,answer) in enumerate(zip( sparse_vector,dense_vector, dataset_df.answer.to_numpy(), )) ], # metadata={"sentense":corpus[i]}, namespace='test-hybrid' )
これでベクトル検索およびハイブリッド検索で使うの密ベクトル、疎ベクトルの保存が完了しました。
3. ベクトル検索+リランクを用いた検索の利用方法
また、ベクトル検索+リランクを用いたについては、以下の実装で処理が可能です。
ベクトル検索で取得してきた検索結果10件に対してPineconeのリランクモデルで再順位付けを行っている形です。
def vector_rerank_query(query,dense_query): # 上位10件の検索結果をベクトル検索より取得 query_response = index.query( top_k=10, vector=dense_query, namespace="test-hybrid", include_metadata=True, ) respoinse_answers =[ {"id": res["id"],"text":res["metadata"]["answer"]} for res in query_response["matches"]] # リランクによる再順位付け rerank_results=pc.inference.rerank( model="bge-reranker-v2-m3", query=query, documents=respoinse_answers, top_n=5, return_documents=True, ) return response
4. ハイブリッド検索の利用方法
では次に挿入したデータセットに対してハイブリッド検索を行っていきます。
以下の実装でハイブリッド検索が可能です。
def hybrid_query(sparse_query,dense_query): response = index.query( top_k=5, vector=dense_query, namespace="test-hybrid", sparse_vector=sparse_query, ) return response
検証結果
では検証の結果を以下に示します。
| 検索順位 | ベクトル検索結果(レビューNo.) | ベクトル検索+リランクによる検索結果(レビューNo.) | ハイブリッド検索結果(レビューNo.) |
| 1 | 6 | 6 | 10 |
| 2 | 9 | 9 | 7 |
| 3 | 8 | 10 | 5 |
| 4 | 10 | 7 | 9 |
| 5 | 2 | 8 | 3 |
レビューNo.10,7の以下の文章が今回のクエリである「お肉の料理がおいしい宿」に合致しているため、取得できることを期待しています。
レビューNo.7
夕食は地元の名物料理が盛りだくさんで、大満足でした。特に炭火焼きでいただいた和牛ステーキは口の中でとろける美味しさで、何度もおかわりしたくなるほどでした。朝食も種類が豊富で、地元の野菜を使ったサラダや、手作りの豆腐が美味しかったです。
レビューNo.10
夕食は地元の食材をふんだんに使った創作料理で、どの料理も工夫が感じられました。特に地元産の野菜とお肉を使ったグリル料理が絶品で、素材の味がしっかりと引き立っていました。朝食も手作りのジャムや焼き立てのパンなど、こだわりが感じられる内容で、大変満足しました。
今回の結果でいえば、ハイブリッド検索ではレビューNo.10,7のレビューを1番目、2番目に類似しているとして取得できていることが分かります。
ベクトル検索+リランクを用いた検索については、今回取得した5つの検索結果の中でレビューNo.10,7を取得することが出来ていました。
また、ベクトル検索のみと比較すると、リランクを用いた検索ではレビューNo.7をより類似度が高いものとして取得できているため、リランクを用いることで検索精度がベクトル検索よりも上がっていることが伺えます。
以上より、ハイブリッド検索が今回の結果では最も期待した検索結果を取得できており、ベクトル検索+リランクを用いた検索がそれに続く形になっていることが分かりました。
RAGによる回答精度の向上のために、Pinecone を使ったハイブリッド検索やリランクを取り入れるのは有効な一手となりそうです。
まとめ
今回はPineconeを使ったハイブリッド検索とリランクを用いた検査について検証を行いました。
結論としてハイブリッド検索、リランクを用いた検索の双方で通常のベクトル検索のみの結果と比較して期待した値が取得しやすい形となりました。
RAGでより高精度な情報の取得を求める場合に、まず取り入れたい技術となっていそうです。
Acroquest Technologyでは、キャリア採用を行っています。
- Azure OpenAI/Amazon Bedrock等を使った生成AIソリューションの開発
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- マイクロサービス、DevOps、最新のOSSやクラウドサービスを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。
www.wantedly.com