こんにちは。データサイエンティストチームYAMALEXのSsk1029Takashiです。
LLMが広く使用されるようになってから、RAGに関する研究も増加し、RAGを拡張する手法の研究も多く出ました。
その中でもテキストをグラフデータとして扱いRAGの元データとする手法をGraphRAGと言います。
今回はその中の一つであるMicrosoftが提唱しているGraphRAGの手法を使っていきます。
MicrosoftからはGraphRAGを使用できる実装もPythonライブラリとして発表されています。
ライブラリではグラフデータはあくまでRAGの元データとして使用していますが、せっかくテキストからグラフが生成できるのであれば、テキストマイニングしてみたくなるものです。
そこで、本記事ではこの手法で作成したグラフをグラフDBの一つであるNeo4jに投入して、可視化できないかを試してみます。

本記事の目次は以下の通りになります。
この記事では、簡単に試してみることが目的のため以下の説明は割愛します。
- Neo4j自体の説明、セットアップ方法
- グラフクエリの基本的な文法
GraphRAGとは
一般的にはGraphとRAGを組み合わせた手法をGraphRAGと呼ぶことが多いですが、ここではMicrosoftが提案した手法をGraphRAGと呼びます。
GraphRAGでは入力された文章内でキーワード同士の関連をグラフ構造として保持して、そのデータをもとにRAGをします。
特徴としてGraphRAGではGlobal SearchとLocal Searchという2種類の検索方法を使用することができます。
- Global Search:登録されたデータから全体的な大まかな概要を回答する
- Local Search:特定の人物やイベントなど細かい情報をピンポイントで回答する
例えば、「2024年のLLMについて概要を教えてください」というのはGlobal Searchで、「GraphRAGで使用されている言語は?」というのはLocal Searchになります。
特に世の中にグラフ構造のデータを使ったRAGが多い中で、MicrosoftのGraphRAGに特有の概念としてCommunity Reportというものがあります。
GraphRAGでは、グラフデータを作成した後、いくつかグループにクラスタリングして、グループごとに要約を作成します。
このグループのことをグラフ構造ではCommunityと言うため、グループから作成した要約をCommunity Reportと言います。
Global SearchではこのCommunity Reportというものを利用して、回答することで大まかで網羅的な内容を回答できるようにしています。
GraphRAGでのグラフデータ作成
GraphRAGでテキストからグラフデータを作るときのステップは大まかに以下になります。
- 入力されたテキストをチャンクに分割する
- チャンクごとにEntity、RelationShipを説明付きでOpenAIモデルを使って抽出する
- Entity、Relationshipが複数回登場することもありえるので、OpenAIモデルを使って各Entity、Relationshipの説明を要約する
- グラフをクラスタリングして、グラフごとにCommunity Reportを作成する
- グラフデータとEntityのEmbeddingを作成する
EntityとRelationshipの抽出は以下のようなイメージで抽出されます。
入力
大規模言語モデル(だいきぼげんごモデル、英: large language model、LLM)は、多数のパラメータ(数千万から数十億)を持つ人工ニューラルネットワークで構成されるコンピュータ言語モデルで、膨大なラベルなしテキストを使用して自己教師あり学習または半教師あり学習(英語版)によって訓練が行われる。
抽出結果
("entity"\t大規模言語モデル\tlanguage model\t大規模言語モデル(LLM)は、数千万から数十億のパラメータを持つ人工ニューラルネットワークで構成され、膨大なラベルなしテキストを用いた自己教師あり学習または半教師あり学習で訓練される。)
{record_delimiter}
("entity"\tパラメータ\tparameter\tパラメータは、人工ニューラルネットワークを構成し、その性能を左右する要素である。)
{record_delimiter}
<中略>
("relationship"\t大規模言語モデル\tラベルなしテキスト\t大規模言語モデルはラベルなしテキストを使用して訓練される\t8)
{record_delimiter}
("relationship"\tラベルなしテキスト\t自己教師あり学習\tラベルなしテキストは自己教師あり学習の訓練データとして使用される\t7)
{record_delimiter}
<中略>このようにentityとrelationshipという2種類の項目を同時にOpenAIのモデルを使って抽出して、それぞれの説明を付与します。
ここで抽出されたentityとrelationshipを使ってグラフデータを作成します。
この後のCommunityの作成やEmbeddingの作成については細かいアルゴリズムの話になるため本記事では割愛します。
GraphRAGで作成したデータをNeo4jに投入する
簡単にGraphRAGについても説明したので、実際にグラフデータを作成してNeo4jに投入してみましょう。
今回は以下の「大規模言語モデル」のWikipediaのページを元データとします。
ja.wikipedia.org
GraphRAG用のデータを作成する
GraphRAGのPythonライブラリでは作成したグラフ構造を表すデータは複数のparquetファイルで出力されます。
基本的な手順は以下のページに記載されているので、手順自体は簡易的に紹介します。
microsoft.github.io
まず、Wikipediaのページをコピーしてテキストファイルにしたうえで./blog_test/inputディレクトリに配置します。
そのうえで以下のコマンドを実行して、設定ファイルを生成します。
graphrag init --root ./blog_test
.envファイルとsettings.ymlファイルが生成されるため、OpenAIのAPI Keyなどの設定を埋めます。
その後、以下のコマンドを実行すことで、parquetファイルが/blob_test/outputディレクトリに生成されます。
graphrag index --root ./blog_test
実行結果として以下のparquetファイルが生成されるため、このファイルをもとにNeo4jに投入していきます。
create_base_documents.parquet create_base_entity_graph.parquet create_base_extracted_entities.parquet create_base_text_units.parquet create_final_communities.parquet create_final_community_reports.parquet create_final_documents.parquet create_final_entities.parquet create_final_nodes.parquet create_final_relationships.parquet create_final_text_units.parquet create_summarized_entities.parquet
例えば、create_final_entities.parquetには抽出した結果のEntity情報が入っており、以下のようなデータフレームになっています。

作成したグラフデータをNeo4jに投入する
前章までで作成したparquetファイルをグラフデータとしてNeo4jに投入していきます。
今回は簡易的に実施するため、Neo4jのクラウドサービスである、AuraDBを利用しました。
https://neo4j.com/product/auradb/
Neo4jにデータ投入するための実装はGraphRAGのリポジトリの中に参考実装があるのでそちらを利用します。
全てのコードを説明すると長くなるため、主要な部分をピックアップして見ていきます。
まずは、ノードの種類を定義している部分になります。
# create constraints, idempotent operation statements = """ create constraint chunk_id if not exists for (c:__Chunk__) require c.id is unique; create constraint document_id if not exists for (d:__Document__) require d.id is unique; create constraint entity_id if not exists for (c:__Community__) require c.community is unique; create constraint entity_id if not exists for (e:__Entity__) require e.id is unique; create constraint entity_title if not exists for (e:__Entity__) require e.name is unique; create constraint entity_title if not exists for (e:__Covariate__) require e.title is unique; create constraint related_id if not exists for ()-[rel:RELATED]->() require rel.id is unique; """.split(";") for statement in statements: if len((statement or "").strip()) > 0: print(statement) driver.execute_query(statement)
上記コードでは、以下の種類のデータをそれぞれノードとして投入しています。
| ノードの種類 | 説明 |
| __Entity__ | 抽出したEntity |
| __Document__ | 入力にしたファイル。今回は一つなのでノードも一つ |
| __Chunk__ | Documentを分割して作成したChunk |
| __Community__ | グラフをクラスタリングして作成したCommunity |
| __Covariate__ | 関係性に追加した情報。デフォルトでは生成されないため、今回は使用しない |
これらのノードは以下のリレーションによってそれぞれこの後のコードで定義づけされています。
| リレーション | 対応ノード | 説明 |
| HAS_ENTITY | __Chunk__ → __Entity__ | Chunk内に存在するEntityを示す |
| IN_COMMUNITY | __Entity__ → __Community__ | EntityがどのCommunity Reportに参照されたか |
| PART_OF | __Chunk__ → __Document__ | Chunkがどのファイルから作成されたか |
| RELATED | __Entity__ → __Entity__ | 関連のあるEntityであることを示す |
例えば、HAS_ENTITYはのリレーションは以下のコードで作成されています。
entity_statement = """ MERGE (e:__Entity__ {id:value.id}) SET e += value {.human_readable_id, .description, name:replace(value.name,'"','')} WITH e, value CALL db.create.setNodeVectorProperty(e, "description_embedding", value.description_embedding) CALL apoc.create.addLabels(e, case when coalesce(value.type,"") = "" then [] else [apoc.text.upperCamelCase(replace(value.type,'"',''))] end) yield node UNWIND value.text_unit_ids AS text_unit MATCH (c:__Chunk__ {id:text_unit}) MERGE (c)-[:HAS_ENTITY]->(e) """ batched_import(entity_statement, entity_df)
bathed_importの中では、与えられたDataFrameの各行に対して、entity_statementで定義されたクエリが実行されています。
クエリの中では、__Entity__のノードに対して、idやdescriptionなどのプロパティやベクトル情報を付与して、最終行のMERGE (c)-[:HAS_ENTITY]->(e)の部分でリレーションを付与しています。
リンク上のコードを実行して、Neo4jのコンソールから、例として以下のクエリを実行するとデータが入ったことが確認できます。
MATCH p=()-[]->() RETURN p LIMIT 25;
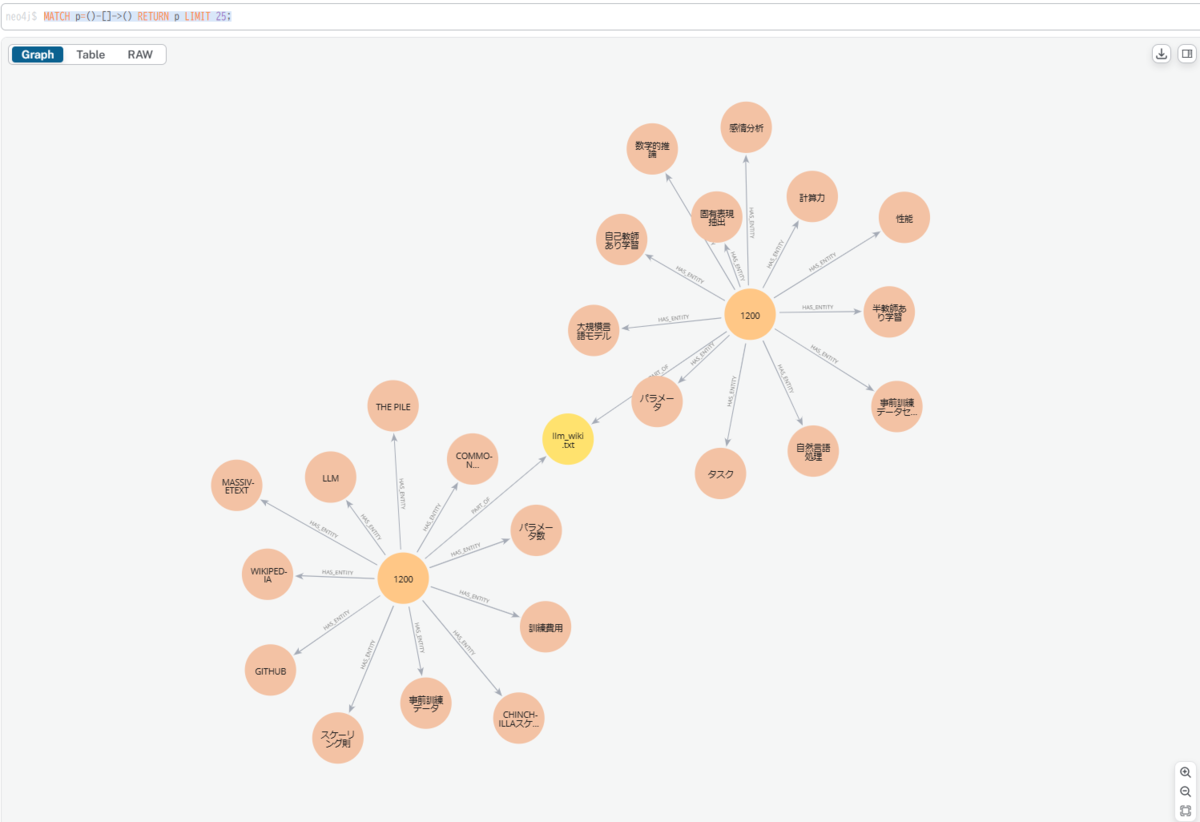
ここまででNeo4jにデータ投入はできたので、次の章でグラフの内容を見てみたいと思います。
グラフを可視化・分析してみる
Neo4jのコンソールでは、クエリを実行することで結果として取得できたグラフデータを可視化することができます。
まずは、Entity同士の関係性を見てみましょう。
以下のクエリを実行することで、Entity同士で関連があるものを取得します。
MATCH path = (:__Entity__)-[:RELATED]->(:__Entity__) RETURN path LIMIT 200
ざっくり以下のようなグラフが可視化されます。

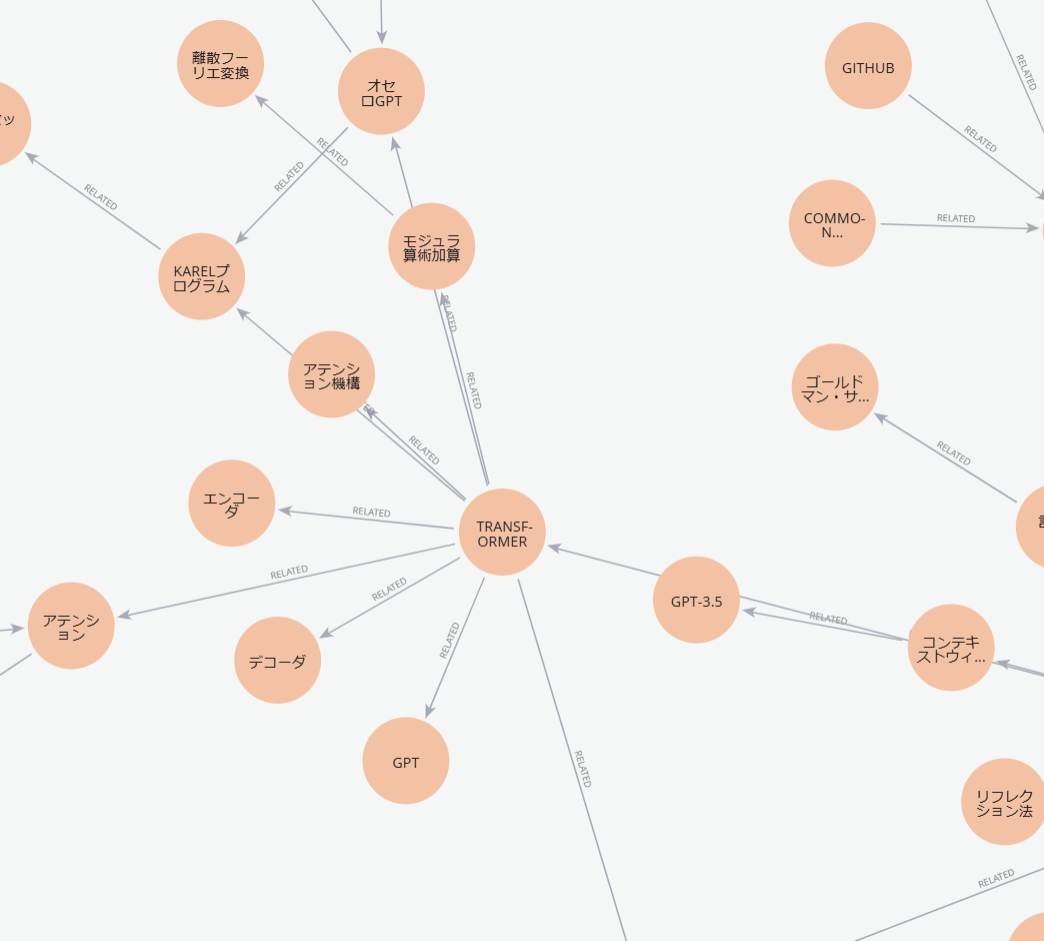
中心部のほうを詳しく見ると、以下のようになっています。
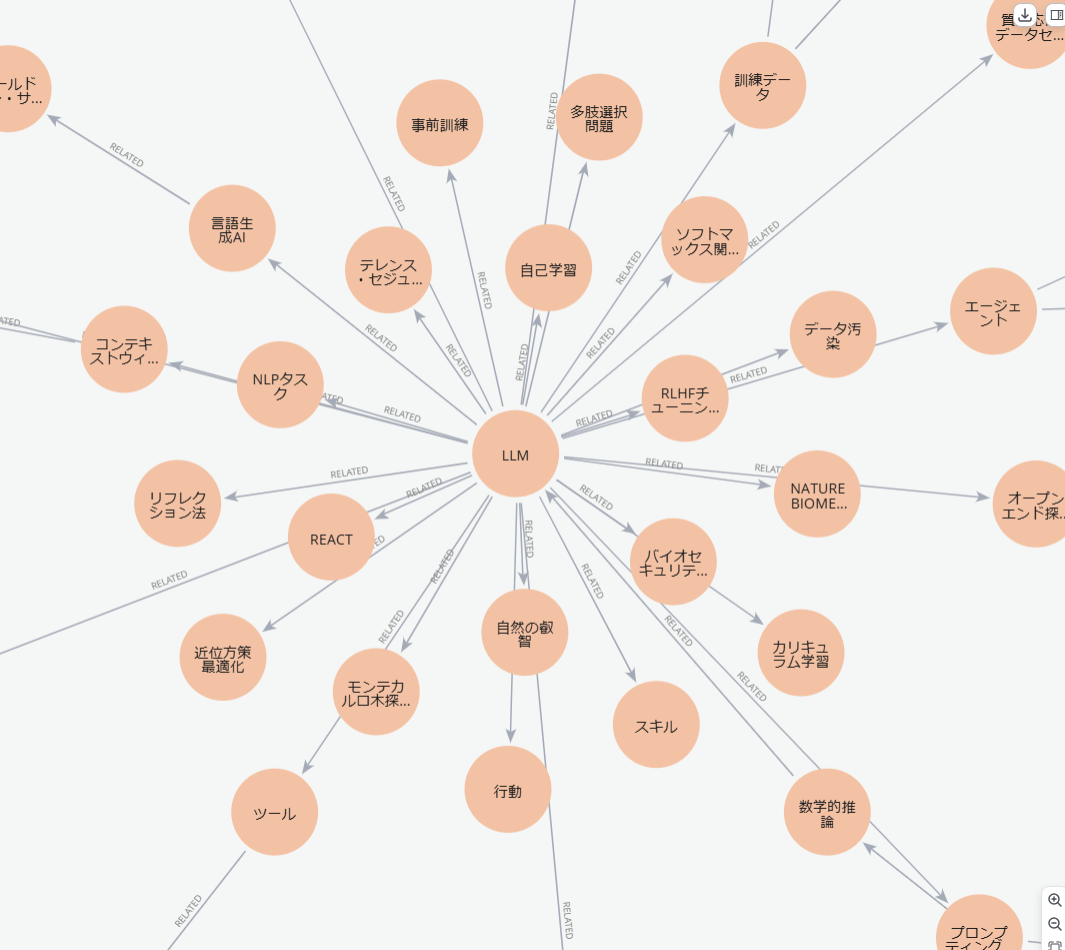
元々LLMに関するWikipediaページをデータにしているので、LLMが最も多くのEntityから関連されているのは想定通りです。
また、別のエリアを見てみるとLLMに関する重要単語が比較的多く関連付けされていることもわかります。
また、CommunityとEntityの関係性も見てみましょう。
以下のクエリでCommunityに対してどのEntityが属しているかを可視化できます。
MATCH (c:__Community__) WITH c LIMIT 2 MATCH path = (c)<-[:IN_COMMUNITY]-()-[:RELATED]-(:__Entity__) RETURN path LIMIT 100
すると以下のように、Communityと属しているEntityがどのように関連しているかを可視化できます。
また、Communityの詳細な内容はノードのプロパティにしているため、選択すれば内容を確認できます。

「トークン」や「大規模言語モデル」などの単語が表示しているCommunityから参照されていてなおかつ、Entityにも多く参照されており重要な単語になっていることがわかります。
このようにグラフとして目に見えるだけでもだいぶどのようなドキュメントかを理解できるようになりますね。
もちろんグラフデータなので、Local Searchのように特定の情報をクエリで取得することも可能ですので、RAGのバックエンドとしても利用できます。
なので、本記事で試したNeo4jもRAGアプリケーションのバックエンドや分析基盤として一つの選択肢になりそうです。
まとめ
本記事では、MicrosoftのGraphRAGで生成されるグラフデータをNeo4jに投入してグラフ表示しました。
GraphRAG自体はRAGするためのライブラリですが、テキストからグラフデータを作成できるという観点でドキュメントの概観を把握するという意味では有用そうです。
LLMとグラフの組み合わせは色々研究も広がっているため、注目領域になりますね。
それではまた。
Acroquest Technologyでは、キャリア採用を行っています。
- Azure OpenAI/Amazon Bedrock等を使った生成AIソリューションの開発
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- マイクロサービス、DevOps、最新のOSSやクラウドサービスを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。