こんにちは。データサイエンスチームYAMALEXの@Ssk1029Takashiです。
(YAMALEXについて詳細はこちらをぜひご覧下さい。)
www.acroquest.co.jp
つい先日Phi-4-reasoningというモデルがMicrosoftから発表されました。
軽量な事前学習済み言語モデル(SLM)も性能が上がってきて利用されることが増えてきています。
SLM は量子化などを施すことで、ハイエンド GPU を使わずとも動かせる点が利点です。
そのため、外に出せないデータを扱ったり、通信できない環境で利用されることが多いとされています。
SLMを扱う場合に必要になるのはFine Tuningになります。
OpenAIのようなLLMとは違い、モデル自体はそこまで強力ではないため、実行させたいタスクを狭めて、そのタスク用にFine Tuningしたモデルを利用することが主流です。
今回はPhi-4-mini-instructモデルを対象にAzure AI FoundryのServerless APIを使ってFine Tuningからデプロイして文章を生成するところまでを簡単に実行してみます。
- Azure AI FoundryでのFine Tuning
- Serverless APIでのFine Tuning
- phi-4-mini-instructをFine Tuningする
- Fine TuningしたモデルをAzure AI Foundry上にデプロイする
- Fine Tuningしたモデルの出力を確認する。
- まとめ
Azure AI FoundryでのFine Tuning
Azure AI Foundryではモデルカタログのうち一部のモデルでFine Tuning機能を提供しています。
learn.microsoft.com
Fine Tuningはデータセットを用意すればすべて画面から可能なため、コーディングの知識がない場合でも実施可能です。
ただし、Fine Tuningを使用するケースについては注意が必要です。
ドキュメントにも記載されていますが、モデルは事前に大量のデータで学習されているため、新しいタスク・知識を覚え込ませるためには大量のデータが必要になります。
出力のフォーマットを調整するなどのタスクをFine Tuningで学習する分にはそこまで多くのデータはいりませんが、もし新しい知識を覚え込ませたいなどの場合はRAGを使うことが推奨されています。
Serverless APIでのFine Tuning
Azure AI Foundry上ではLLMのFine Tuning方法としてServerless APIとManaged Computingがサポートされています。
2つの方法の比較は以下になります。
| 方法 | 説明 | メリット |
| Managed Computing | 自分でFoundry上でManaged Computingを立てて、そこでFine Tuningを実行する | 自分で学習環境を設定できるためカスタマイズが効く |
| Serverless API | モデルと学習データだけ設定して自動でFine Tuningを実行する | データ量に応じた従量課金になり、コストを抑えられやすい。複雑な設定が不要。 |
ただし、それぞれの方法はサポートしているモデルが異なるため、両方サポートしているモデルもあれば、どちらかしか使用できない場合もあるので事前の確認が必要です。
また、Serverless APIは現在一部のリージョンでのみ使用可能なため、その点も注意しましょう。
詳細は以下のページを参照してください。
learn.microsoft.com
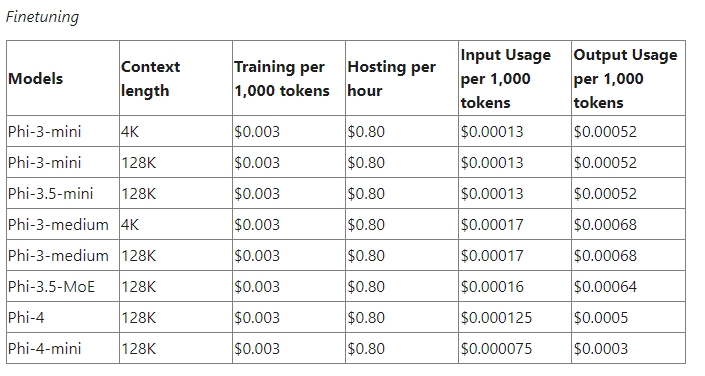
また、Serverless APIを使用したFine Tuningの料金やデプロイしたモデルの料金はモデルごとに異なるため、個別にチェックが必要です。
特にFine Tuningしたモデルは推論用のエンドポイントを作成すると、時間単位で料金が発生するため注意が必要です。
例えばPhi-4ファミリは以下のページに記載されています。
techcommunity.microsoft.com
phi-4-mini-instructをFine Tuningする
Fine Tuningは大きく以下のステップになります。
- Fine Tuningのタスクに適したデータを用意する。
- Azure AI Foundry上でFine Tuningを実行する
データを準備
Phi-4ファミリのモデルをFine Tuningするときには以下のChat Completion形式のデータを用意する必要があります。
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}今回は固有表現抽出をタスクを学習させてみます。
以下のリポジトリで公開されているデータを加工してLLMのFine Tuningに利用できるフォーマットにします。
github.com
以下は作成したデータセットのサンプル行になります。
{"messages": [{"role": "system", "content": "入力された文章から固有表現を抽出してください。"}, {"role": "user", "content": "SPRiNGSと最も仲の良いライバルグループ。"}, {"role": "assistant", "content": "[{\"name\": \"SPRiNGS\", \"type\": \"その他の組織名\"}]"}]}
{"messages": [{"role": "system", "content": "入力された文章から固有表現を抽出してください。"}, {"role": "user", "content": "日本マイクロソフトは、東京都港区に本社を置くITサービス企業である。"}, {"role": "assistant", "content": "[{\"name\": \"日本マイクロソフト\", \"type\": \"法人名\"}, {\"name\": \"東京都港区\", \"type\": \"地名\"}]"}]}タスクの内容としては与えられた文章から決められたフォーマットで固有表現抽出を実施する処理になります。
本来、このような処理をLLMで実施しようとするとプロンプト内でフォーマットの指示など細かくする必要がありますが、今回はFine Tuningすることでタスク内容を覚え込ませるので、システムプロンプトもシンプルな内容になっています。
件数としては500件用意しました。
Azure AI Foundry上でFine Tuningを実行する
今回は対象のモデルはPhi-4-mini-instructを使用するため、まずモデルカタログから対象のモデルを選択します。

このメニューの微調整からFine Tuningを実行できます。
微調整のメニューを選択するとServerless APIかManaged Computingかを選ぶ画面になるのでServerless APIを選択します。

続く画面ではモデル名などを設定するので、任意の名前を入力します。

続く画面ではFine Tuningに使用するデータを選択します。
AI Foundry上にアップロード済みのデータか、新規のファイルを選択できるため、新規にファイルをアップロードします。
アップロードに成功すると以下のようにデータのプレビューを表示できます。

続いては精度を計測するための検証データを選択します。
今回は簡単に実行するために、トレーニングデータを自動分割を選択します。
こうすることで、前の画面でアップロードしたデータの中から自動で検証データを切り出してくれます。

後は以下の画面でBatch Size、Learning rate、Epoch数を設定します。

ここまで設定すれば、Fine Tuningを実行できます。

Fine Tuning結果を確認する
Fine Tuningが無事完了すれば以下のような画面が表示されます。

また、学習時のメトリックの画面も参照できて、lossなどの推移が表示できます。

今回はデータ件数もそこまで多くなかったため、42分程度で学習は完了しました。
Fine TuningしたモデルをAzure AI Foundry上にデプロイする
Fine TuningしたモデルはAzure AI Foundry上でデプロイして、他のモデルと同じように使用できます。
Fine Tuning結果の画面から「デプロイ」を選択すると以下のようにデプロイ設定画面になります。

デプロイに必要なのはデプロイ名とコンテンツフィルターの設定のみのため、簡単にデプロイ可能です。
デプロイに成功した場合、以下のようにエンドポイントをキーが表示されます。

これでFine TuningしたモデルをAPIから呼び出して利用できるようになりました。
非常に簡単ですね。
一点注意なのは、デプロイされたモデルは時間単位でも課金されるので、利用しないときは必ずエンドポイントを削除しておきましょう。
Fine Tuningしたモデルの出力を確認する。
それではデプロイしたエンドポイントからモデルの出力を確認してみましょう。
Azure AI Foundryのポータルからはプレイグラウンドが利用できますが、その場合システムプロンプトを指定できないため、Fine Tuningしたモデルを試す場合には適しません。
なので、今回は以下のサンプルプログラムを使って結果を確認
from azure.ai.inference import ChatCompletionsClient from azure.core.credentials import AzureKeyCredential client = ChatCompletionsClient( endpoint='xxx', # 実際には生成されたエンドポイントを記載 credential=AzureKeyCredential("xxx") # 実際には生成されたキーを記載 ) model_info = client.get_model_info() payload = { "messages": [ { "role": "system", "content": "入力された文章から固有表現を抽出してください。" }, { "role": "user", "content": "Acroquestは新横浜に本拠地を置く会社である。" } ], "max_tokens": 800, "temperature": 0.0, "top_p": 0.95, "presence_penalty": 0, "frequency_penalty": 0 } response = client.complete(payload) print("Response:", response.choices[0].message.content) print("Usage:") print(" Prompt tokens:", response.usage.prompt_tokens) print(" Total tokens:", response.usage.total_tokens) print(" Completion tokens:", response.usage.completion_tokens)
上記の出力は以下のようになります。
Response: [{"name": "Acroquest", "type": "法人名"}, {"name": "新横浜", "type": "地名"}]
Usage:
Prompt tokens: 37
Total tokens: 70
Completion tokens: 33結果としては、正しい内容が想定したフォーマットできていそうです。
システムプロンプトで細かい指定をする必要がなく、プロンプト数の節約にもなるので便利ですね。
まとめ
本記事はPhi-4-mini-instructをAzure AI Foundryで簡単にFine Tuningしました。
Fine Tuningだけならデータを用意して、あとは画面上で設定するだけで簡単にFine Tuningを実行できました。
これでモデルを検証する準備は整ったので、どのようなタスクに適用できるかなど検証していきます。
今回は固有表現抽出を試してうまくいきましたが、特定ドメインのQAを学習するなどは難しかったのでどこまでできるかなど引き続き調べていきたいと思います。
それではまた。
Acroquest Technologyでは、キャリア採用を行っています。
- Azure OpenAI/Amazon Bedrock等を使った生成AIソリューションの開発
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- マイクロサービス、DevOps、最新のOSSやクラウドサービスを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。