こんにちは。アキバです。
この記事は、Elastic Stack (Elasticsearch) Advent Calendar 2020 - Qiita の12日目です。
qiita.com
当社ではリモートワークに移行し始めて9~10か月になろうかというこの頃ですが、リモートワークをされている皆さんはどのような工夫をされているでしょうか?
私はiPad Proを日常的に使って、社内のホワイトボードでやっているような手書き体験の共有をしています。
最近、新しいペーパーライクフィルムを使用することになったのですが、これまでのペーパーライクと触感がガラリと変わり、慣れるまでちょっとぎこちない感じです。
今日は、そんな手書き体験の話とは全く関係ない、ログ収集に関する話です。
何の話か?
定期的に起きる質問
今の時代、アプリケーションをDocker/Kubernetesなどのコンテナ上で動作させることが多くなってきましたが、定期的に以下のような質問が出ます。
コンテナに載せたアプリケーションが複数のログを出力するような場合に、どうやってログを収集するのが良いのか?
コンテナを使わない場合は以下のような形でログ収集することができます。

アプリケーションをコンテナに載せて動かそうとしたときに、通常はFilebeatはコンテナの外に置きたいと思います。
特に、Kubernetesの場合はFilebeatはDaemonSetで動かし、AutoDiscoverによってログ収集対象となるPodを(アプリコンテナの外で)選択します。
こうした構成で、以下のようにコンテナ内で複数種類のログを出力していると、単純にはコンテナ外からログが収集できないわけです。
(もっとも、コンテナ内にログを出力すること自体が悪手であり、ログを活用できないため意味のない行為ではありますが...)

単純にログが1種類ならば、コンソール出力にしてcontainer inputで取得するのが定石かなと思いますが、コンソール出力は複数にできないので、何かしら策を講じる必要が出てきます。
理想的には
お作法的なことを言えば、1つのコンテナで動作するプロセスは1つであり、そのプロセスが出力する(収集対象となる)ログも1種類にしたいところです。
しかしながら、一部のアプリケーションには(アプリケーションの動作ログの他に)以下のようなログを出力するものがあります。
- アクセスログ - 自分のAPIが呼び出された際の記録(エンドポイント、ステータスコード、応答時間など)
- 監査ログ - システム/アプリケーションの重要な操作(試行)の記録(操作/権限、ユーザ、成功or失敗など)
どのようにログ収集の仕組みを構築し、Elasticsearch+Kibanaで可視化するか?をパターンに分けて検討してみたいと思います。
※個人的な見解を含みます。もっと良い方法があるかもしれません。
コンテナ内のアプリが複数種類のログファイルを出力する場合の収集方法
方法1:ログファイルをコンテナ外から参照できるように共有する
Dockerであれば、Volume Mountを使ってホストのディレクトリをコンテナ(のログ出力ディレクトリ)にマウントする方法が可能です。
これにより、ホスト側で動作するFilebeatが、コンテナ内のプロセスが出力したログファイルを参照し、ログを収集することが可能になります。

メリット
- コンテナが異常終了しても出力したログはホスト側に残るので、欠損(出力したログがElasticsearchに送られない現象)が発生しにくい
- アプリケーションはログ出力の方式(出力するファイルの数やフォーマット)を変更する必要がない
- ログの種類ごとのタグ付けはFilebeatで行い、投入先のElasticsearchのインデックス指定をLogstashで行う
- ログ加工が必要な場合は、Ingest PipelineまたはLogstashを使用可能
デメリット
- コンテナの可搬性は下がる(DockerComposeを使うことで一部吸収可能だが、ホスト側のディレクトリ準備やuidの統一など一部制約が生まれる)
- ホスト側でコンテナx収集対象ログファイル数のFilebeatを起動する必要がある
- Kubernetesの場合はこの方式は適用できない
方法2:Filebeatをコンテナ内に入れる
コンテナ内でFilebeatを動かせば、任意のログファイルを収集対象にすることができます。
複数のFilebeatを動かせば、複数のログファイルを収集することができますね。
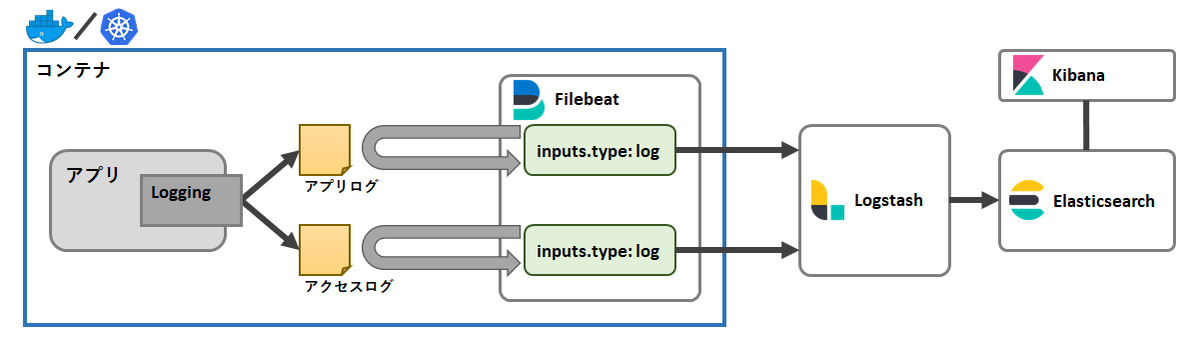
メリット
- コンテナの可搬性は高い(イメージに含まれているリソースのみでログ収集が完結する)→ Kubernetesでも実現可能
- アプリケーションはログ出力の方式(出力するファイルの数やフォーマット)を変更する必要がない
- ログの種類ごとのタグ付けはFilebeatで行い、投入先のElasticsearchのインデックス指定をLogstashで行う
- ログ加工が必要な場合は、Ingest PipelineまたはLogstashを使用可能
デメリット
Filebeatをコンテナ内に置くことでいくつかの注意点が発生します。
- 「どのコンテナから送られてきたログか」を示すには、コンテナ起動時にひと工夫が必要
(それさえ出来れば、大きなデメリットではない) - コンテナの終了タイミングでFilebeatも終了してしまうため、一部のログがElasticsearchに送られず欠損する可能性がある
- Filebeatを入れて動かす分、わずかにコンテナサイズが肥大化する
- 設定がコンテナごとに存在するため、Filebeatの設定変更でコンテナの再作成(再起動)が必要になる
方法3:アプリでログの種類がわかるようにタグ付けし、すべてコンソールに出力する
アプリケーションがすべてのログをコンソール出力するように設定すれば、一つのFilebeatを使ってcontainer inputでまとめて収集することが可能です。

メリット
- コンテナの可搬性は高い(ログ収集に関するリソースをアプリコンテナが持たない)→ Kubernetesでも実現可能
- コンテナが異常終了しても出力したログはホスト側に残るので、欠損(出力したログがElasticsearchに送られない現象)が発生しにくい
- コンテナの外でログ収集が可能なので、Filebeat側でコンテナを区別してタグ付けが可能
- コンテナにFilebeatを含める必要がないため、イメージの肥大化やライフサイクルの依存がない
デメリット
- アプリケーション側でログ出力先とフォーマット、特に種類がわかるようにするタグ付けが必要(初期の設計または設計変更が必要となる)
- 1つのFilebeatで処理をするため、設定できるタグや送信先は1つになる
ログの種類ごとにElasticsearchのインデックスを分けたり、ログ加工が必要になる場合は、Logstashが必須(Ingest Pipelineだけでは実現できない)
共通:Kibanaでの可視化について
いずれの場合も、Elasticsearchに投入するまでの過程でタグ付けやログ加工、インデックスの振り分けを行えますので、Kibana(LogsやVisualize)で可視化する際の要求に対しては柔軟な設定が可能です。
(どの段階で加工・振り分けを行うか?の違いがあるため、システムの変更/構成管理のしやすさで制約が発生する可能性があります)
逆の言い方をすると、どのような可視化をするか?に沿ってこれらの処理を決める必要があります。
タグ付けやログ加工はそれほど頻繁に変わるものではないですが、コンテナのライフサイクルに影響を与えないことを考えると、Filebeatはコンテナの外にいることが望ましいと思います。
まとめ
Docker単独/Kubernetes上で動かすか、アプリケーション側の対応や変更が可能かによって選択肢が変わってくる部分があるかと思いますが、個人的には方法3がベターなのかなと思っています。
アプリケーション側で最初の設計さえ行えれば、それ以外のログ収集に関する要素をアプリケーション側から切り離すことができるのが最大のメリットだと思います。
ログ収集は後からでも始められますが、システム構築の設計段階からこういったことを考慮しておくと運用がしやすくなるのではないかと思いますので、参考にしていただければと思います。
それでは。
Acroquest Technologyでは、キャリア採用を行っています。
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- Elasticsearch等を使ったデータ収集/分析/可視化
- マイクロサービス、DevOps、最新のOSSを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。世界初のElastic認定エンジニアと一緒に働きたい人Wanted! - Acroquest Technology株式会社のデータサイエンティストの求人 - Wantedlywww.wantedly.com