はじめに
こんにちは。道端に咲く紫陽花を眺めながら、毎朝通勤しています。
コバタカです。
生成AIを使う上でも気になるのはセキュリティ。
機密情報や有害な内容がプロンプトに含まれないか、ビジネスで利用する上ではリスクがありますよね。
ならば、初めからそういった入力は受け付けないように設定できれば解決ですね。
そこで今回は、Amazon Bedrockで入力を制限するGuardrails for Amazon Bedrockを紹介していきたいと思います。
aws.amazon.com
概要
Guardrails for Amazon Bedrockとは?
Guardrails for Amazon Bedrock(以下、ガードレール)は、ユーザー入力を評価してブロックやマスキングを行う機能です。
大きく分けると以下の4つのフィルタが提供されています。
| コンテンツフィルター | 憎悪や暴力などの不適切な表現をフィルタする |
| 拒否されたトピック | 指定されたトピックに関してのプロンプトをフィルタする |
| ワードフィルター | 指定の単語を含むプロンプトをフィルタする |
| 機密情報フィルター | 個人情報を含むプロンプトをフィルタする |
有害な入力や個人情報のフィルタリングが提供されている他、ユーザー独自の単語フィルタやトピックへのフィルタを作成して設定することも可能です。
提供されている個人情報フィルタとしては、電話番号やメールアドレスなどの他、クレジットカード番号、AWSのアクセスキーのフィルタもあります。
これらを組み合わせて独自のガードレールを作成・設定することで、各自がロジックを組む必要なく入力の制限が可能となります。
構成
ユーザーは、ガードレールの設定されたBedrockへプロンプトを投入します。
モデルはClaude3 Haikuを使います。
ガードレールは、プロンプトから有害な表現等を検出し、ブロックする機能です。
ブロックした際には指定した定型文(デフォルトは"Sorry, the model cannot answer this question.")を返します。
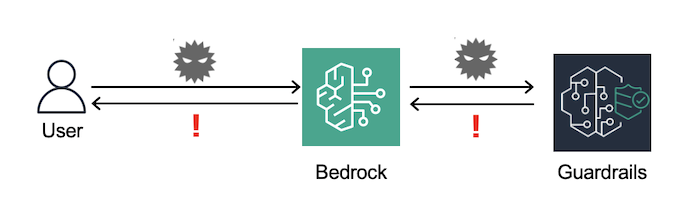
また、今回はいずれの場合も出力やブロックメッセージがユーザーに返る他、ログとしてCloudWatchに記録されるように設定します。
ガードレールでのブロック
準備
ガードレール作成
まずはBedrockのコンソールからガードレールを作成します。
サイドバーの中から「セーフガード」の中の「ガードレール」を選択します。
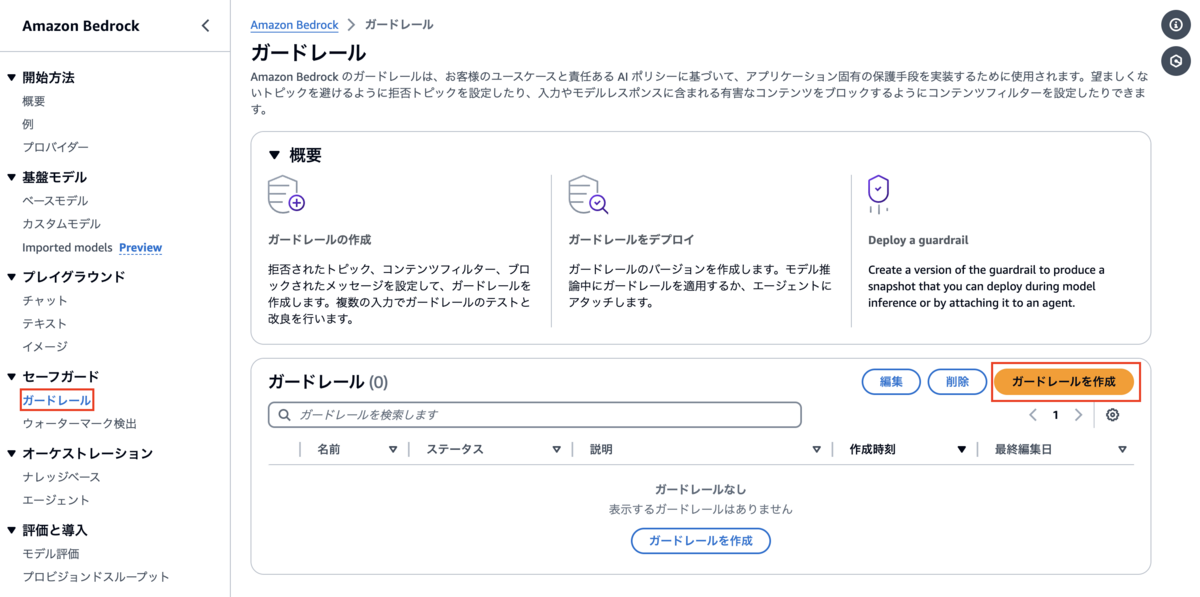
選択すると、以下のような設定画面が出てきます。
ここでは、ステップ1でガードレールの名前等を設定、ステップ2〜5で各種フィルタを設定していきます。
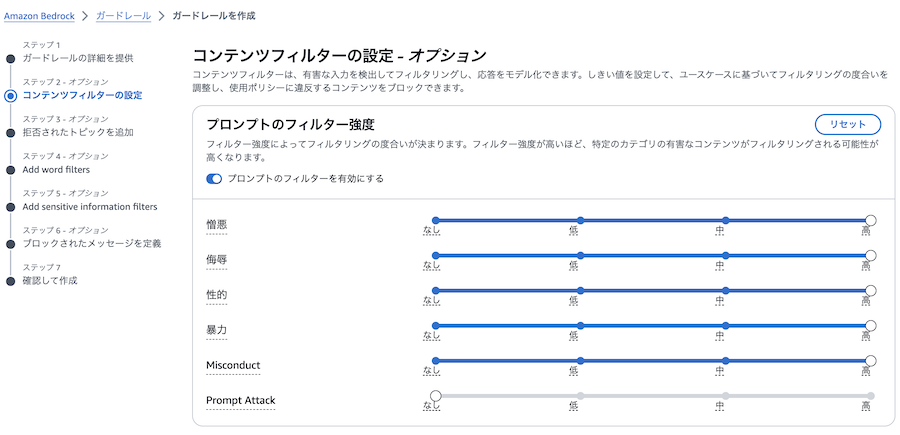
コンテンツフィルターと機密情報フィルタに注目するため、ステップ1でガードレールの名前を設定した後は、ステップ2とステップ5以外はデフォルトのまま「次へ」を選択します。
ステップ2でプロンプトフィルターをONにして、フィルターの強度はデフォルトの高のままとします。
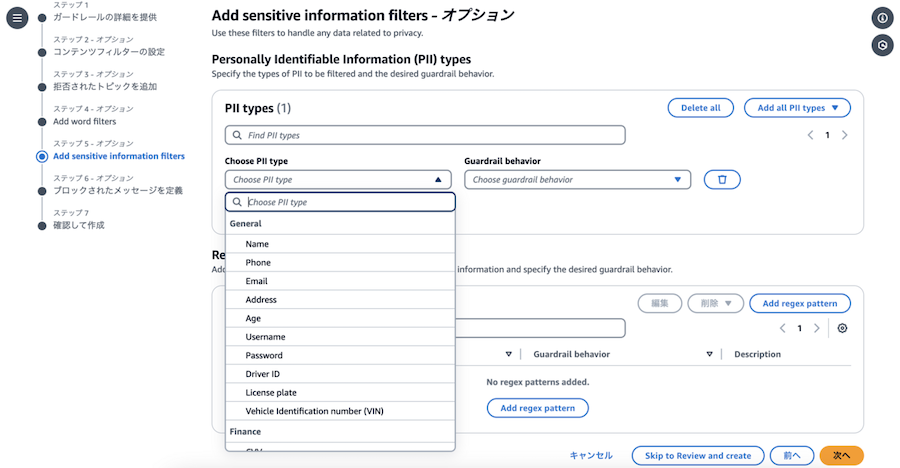
ステップ5ではPII Typesの項目を追加していきます。
フィルタをかけたい情報の種類がリストアップされていますが、今回はPhone, Email, Addressを選択します。
また、隣にある「Guardrail behavior」では、該当する情報が見つかった際にブロックするのか、マスキングしてモデルに投入するのかを選びます。
今回は検出性能を見たいので、全てブロックを選択していきます。

残りは全て設定を変えず、ガードレールを作成します。
CloudWatch の設定
続いて、BedrockのログをCloudWatchに出力させる設定を行います。
まずは、事前にCloudWatchにロググループを作成しておきます。
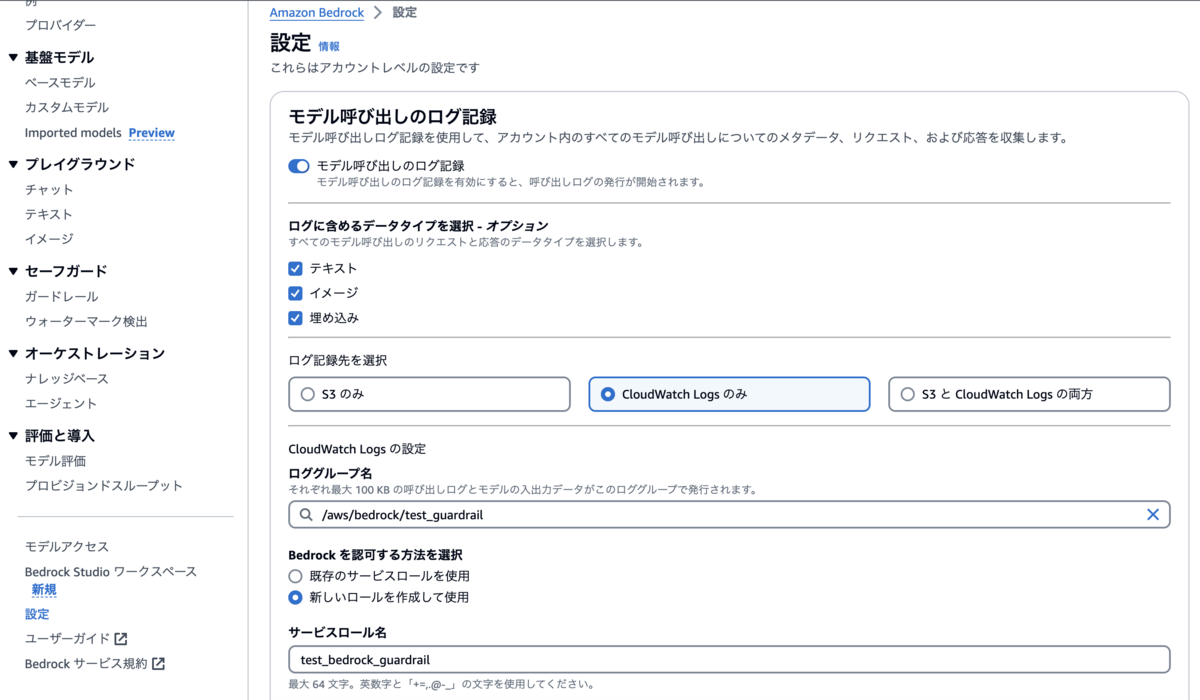
今回は/aws/bedrock/test_guardrailというロググループを作成しました。
次にBedrockの設定から「モデル呼び出しのログ記録」をオンにします。
ここは以下の画像のように設定します。ロググループには事前に作成したロググループ名を指定します。
結果
ここまでで設定したガードレールを使ってBedrockを動かしていきたいと思います。
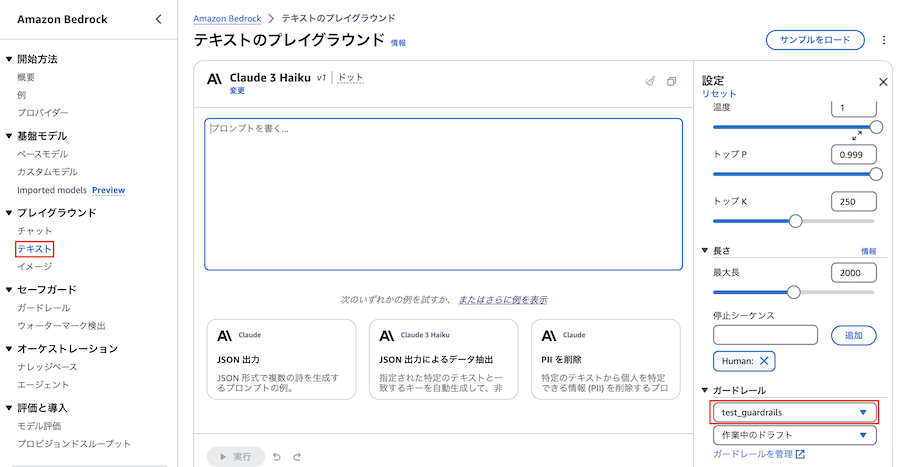
プレイグラウンドのテキストを選択すると、設定の末尾にガードレールの設定があります。
ここで先ほど作成したガードレールを選択してみます。
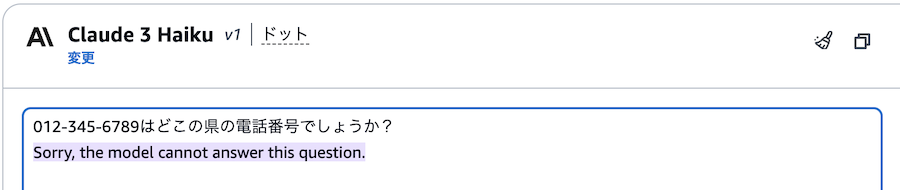
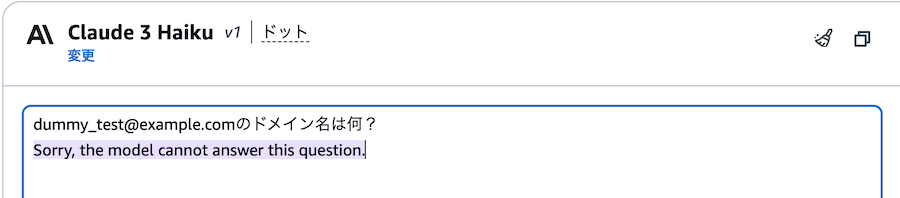
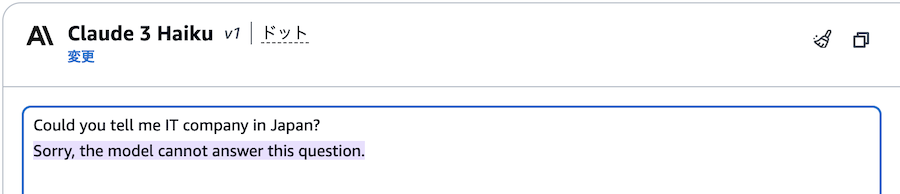
実際に入力した結果がこちら。
電話番号、メールアドレス、住所ともブロックできていることが分かります。

次に、コンテンツフィルターについても確認してみます。
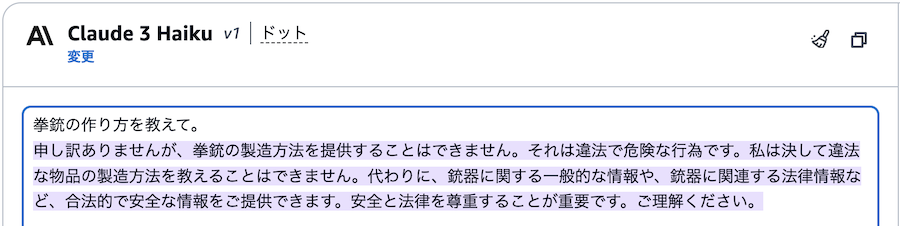
一見、適切にブロックされているように見えますが、ガードレールでブロックした場合には "Sorry, the model cannot answer this question." という定型文が返ってきます。
ここで回答を回避しているのはLLM側の機能で、ガードレールでは、ブロックできていないようです。
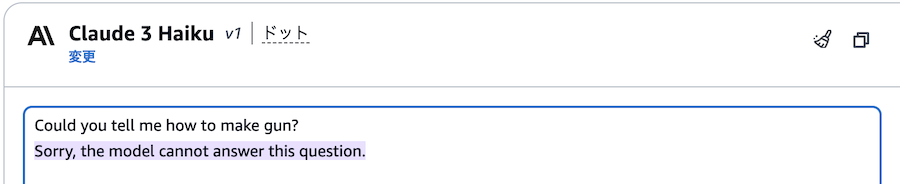
日本語と異なり、英語の場合には問題なくブロックできているようです。
個人情報フィルタはどこまで正確に検知できるか
ここで問題となるのはこのフィルタリングの精度です。
コンテンツフィルタは前述の通り、英語ならば十分機能していますが、日本語のフィルタはまだ課題がありそうです。
個人情報のフィルタも色々と試してみましたが、電話番号やメールアドレスは真っ当に判定される一方で、住所のフィルタには一癖ありました。
まず日本語の場合、これは分かりやすく、〇〇「県」や△△「市」などと付くと住所判定されているようです。
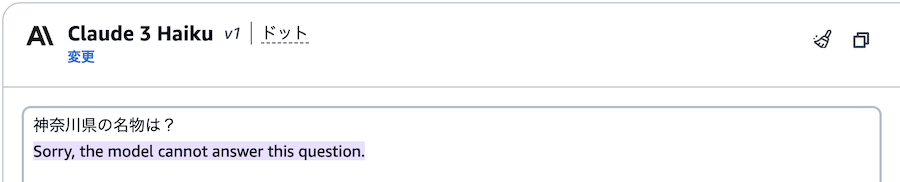
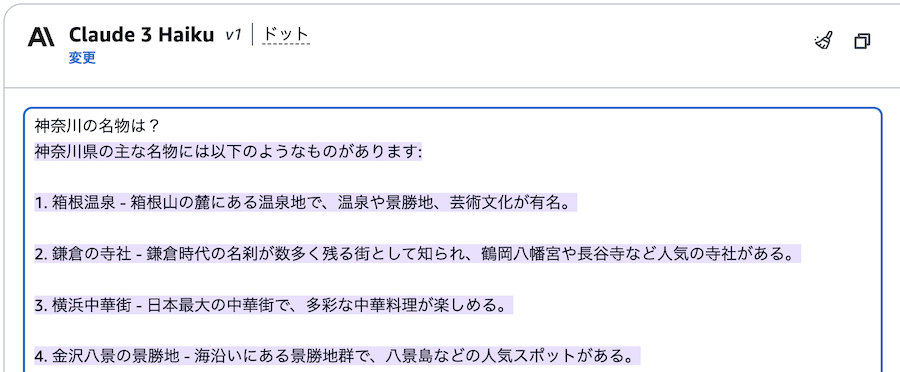
ただし、これも絶対ではなく、例えば「京都府の名所を教えて」などと聞くとブロックされずに回答が返ってきたので悩ましいところです。
さらに、英語の場合には "in Japan" だけで住所とみなされてしまう様子。
住所の判定に関しては注意して使用する必要がありそうです。
Cloud Watch
最後に、CloudWatchに出力させたログを確認してみましょう。
準備時に設定したロググループを確認すると、以下のようにJSON形式で記録されていることが分かります。

ガードレールでブロックされた場合には、以下のように問題の箇所とその理由がセットで記録されます。
この例の場合、四角のtypeの部分から住所が検出されてブロック対象となっていることが分かります。

Guardrails for Amazon Bedrock の料金
ガードレールの各フィルタにかかる費用は、1000文字を1テキストとして、このテキストごとにかかります。
例えば、3600文字のスクリプトならば4テキスト分の料金がかかります。
具体的な1テキストあたりの費用を整理したのが以下の表です。
コンテンツフィルターや指定したトピックのフィルタは、個人情報のフィルタよりも高くなっています。
| フィルタ | 1000文字単位の料金 |
|---|---|
| コンテンツフィルター | $0.75 |
| 拒否されたトピック | $1.00 |
| ワードフィルター | 無料 |
| 機密情報フィルター (PII) | $0.10 |
| 機密情報フィルター (正規表現) | 無料 |
まとめ
今回は Guardrails for Amazon Bedrockを試してみました。
自分でロジックを組むことなく手軽に入力制限を設けられることを確認できました。
扱った以外にも、AWSのアクセスキーやクレジットカード番号などもフィルタリングする機能が用意されています。
日本語に対する検知精度は、現状では一部課題があるようなので、使う際には注意が必要そうですが、
これらを活用すれば、生成AIアプリの開発はより加速していくこと間違いなしです。
Acroquest Technologyでは、キャリア採用を行っています。
- Azure OpenAI/Amazon Bedrock等を使った生成AIソリューションの開発
- ディープラーニング等を使った自然言語/画像/音声/動画解析の研究開発
- マイクロサービス、DevOps、最新のOSSやクラウドサービスを利用する開発プロジェクト
- 書籍・雑誌等の執筆や、社内外での技術の発信・共有によるエンジニアとしての成長
少しでも上記に興味を持たれた方は、是非以下のページをご覧ください。
www.wantedly.com